各位前輩好
小弟剛開始入門影像辨識這塊
目前可以透過Webcam辨識英文字並且印出該英文字
然後產生txt檔,目前全部辨識的文字都集中在裡面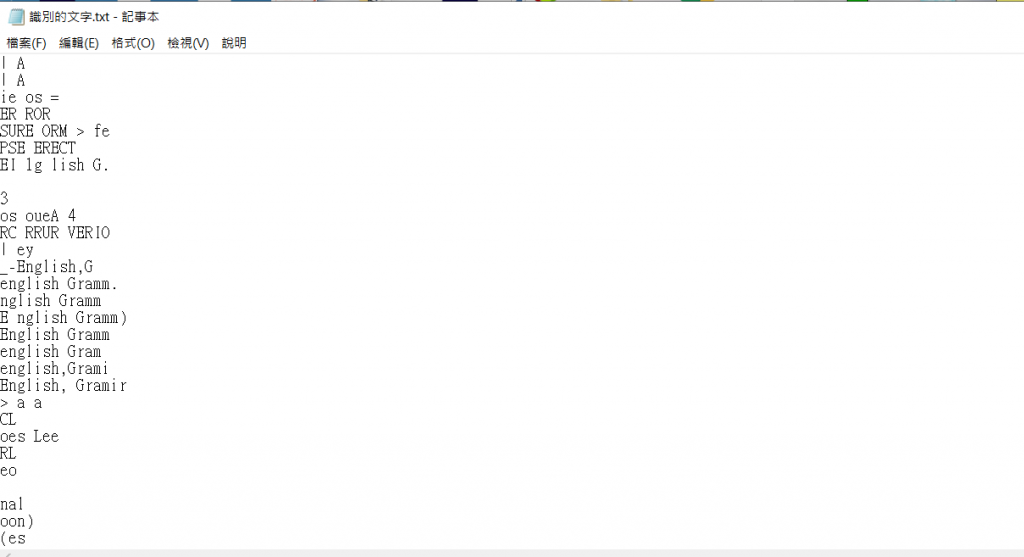
我想要每辨識到一組文字就產一個txt或xml並且文字印到txt或xml裡面
然後檔名是影像辨識到的文字
個別輸出TXT或XML (內容辨識到的文字,檔名辨識到的文字)
例如辨識到123 檔名123 TXT內容123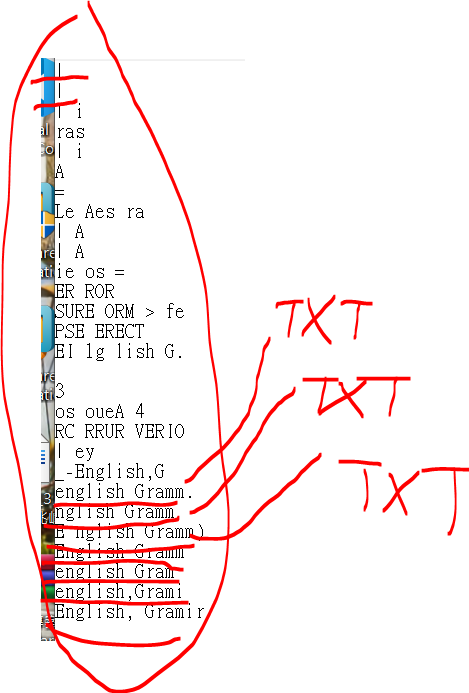
附上code
import cv2
import sys
import pyocr
from PIL import Image
import pytesseract
import pyocr.builders
tools = pyocr.get_available_tools()
tool = tools[0]
cap = cv2.VideoCapture(0)
imgs = Image.open('test01.png')
imga = imgs.convert('L')
ans = pytesseract.image_to_string(imga)
print('OCR光學辨識:',ans)
while True:
ret, frame = cap.read()
Height , Width = frame.shape[:2]
img = cv2.resize(frame,(int(Width),int(Height)))
#OCR 讀取範圍 紅框
cv2.rectangle(img, (100, 100), (Width-200,Height-200),(0, 0, 255), 10)
dst = img[100:Height-200,100:Width-200]#OCR讀出識別後印出
PIL_Image = Image.fromarray(dst)
text = tool.image_to_string(
PIL_Image,
lang = 'chi_tra+eng',
builder=pyocr.builders.TextBuilder())
k = cv2.waitKey(1) & 0xFF
if k == 27:
break
if k == 32:
if(text !=''):
print(text)
with open('識別的文字.txt','a',encoding='utf-8') as fObject:
fObject.write(text+'\n')
cv2.imshow('001',img)
cv2.waitKey(1)
cap.release()
cv2.destroyAllWindows()
請各位前輩指教
已邀請的邦友 {{ invite_list.length }}/5
