此程式碼是課文當中的範例。意旨在想把郵件辦別是否為垃圾郵件或一般郵件。
訓練完模型之後有這樣一個效用檢視的輸出:
import sklearn
from sklearn.metrics import precision_recall_fscore_support as score
# prediction on test data
predicted_blstm=model.predict(test_data)
predicted_blstm
# model evaluation
from sklearn.metrics import precision_recall_fscore_support as score
precision, recall, fscore, support = score(labels_test, predicted_blstm.round())
print('precision: {}'.format(precision))
print('recall: {}'.format(recall))
print('fscore: {}'.format(fscore))
print('support: {}'.format(support))
print("############################")
print(sklearn.metrics.classification_report(labels_test, predicted_blstm.round()))
結果: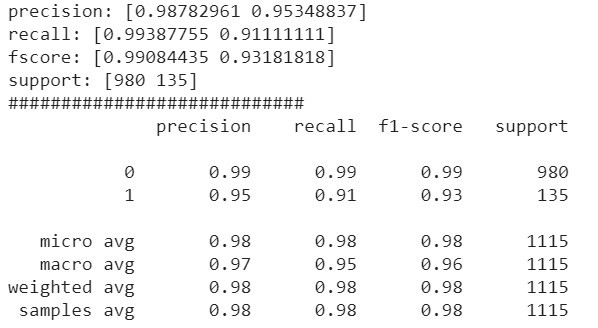
在這樣的模型完成後,請問要如何丟入新的data,讓它告訴我這封郵件是否為垃圾郵件呢?
已邀請的邦友 {{ invite_list.length }}/5
new_data=[['dfsdfjdjhfj']]
model.predict(new_data)
你好,我嘗試用這個方法,但是得出的結果是一個陣列像這樣
array([[9.9973804e-01, 2.6198191e-04],
[9.9988401e-01, 1.1600493e-04],
[9.9996233e-01, 3.7628190e-05],
[9.9998081e-01, 1.9162568e-05],
[9.9998498e-01, 1.5043216e-05],
[9.9907982e-01, 9.2014833e-04],
...
[9.9996233e-01, 3.7628190e-05],
[9.9996233e-01, 3.7628190e-05]], dtype=float32)
但我不是很懂這個陣列代表的意義?
是/不是 垃圾信的機率
但是我只輸入一則email內容,為何有那麼多組機率呢?
input_text = 'Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...'
input_sent = tokenizer.texts_to_sequences(input_text)
input_data = pad_sequences(input_sent, maxlen=MAX_SEQUENCE_LENGTH)
predicted = model.predict(input_data)
predicted
