使用pyscard模組搭配讀卡機,我是先用程式範例做測試
IC卡讀取程式參考範例來源
他沒做什麼特殊的轉碼卻能正常顯示姓名(雖然有打馬但看的出來)
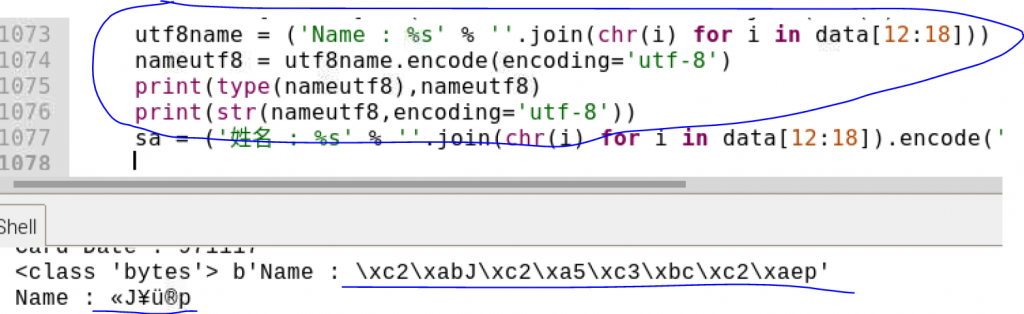
後續 看了網路上的方法,自己嘗試去改 轉成bytes
圖一連結
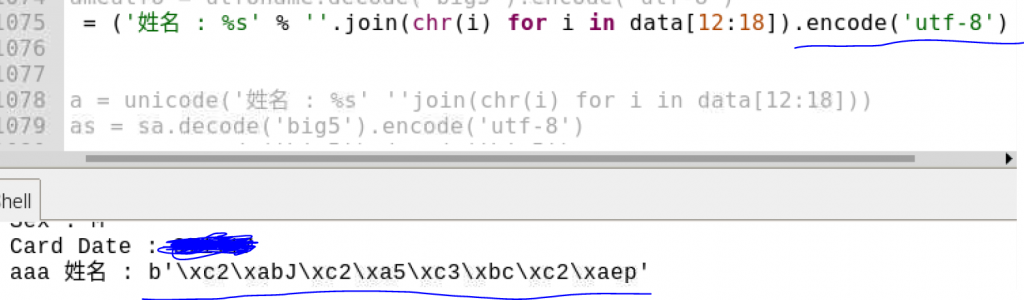
再次轉換unicode又變成了亂碼,但這次亂碼變得不一樣感覺稍微有前進了一步.....
圖二連結
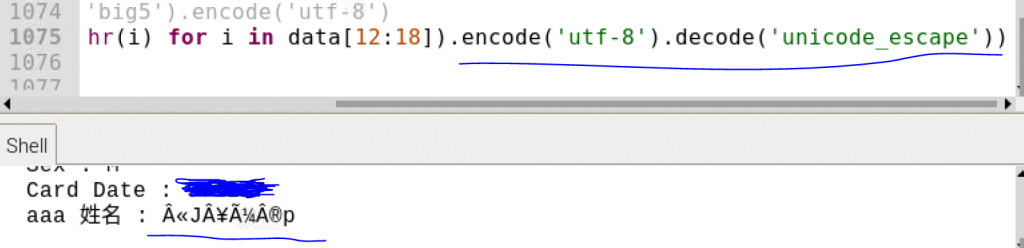
也嘗試了 又被打回原形
圖三連結
--------2020年6月20日早上11點半更新------------
試了網路上很多關於python3編碼轉換的方法
算有小小的進展? 苦笑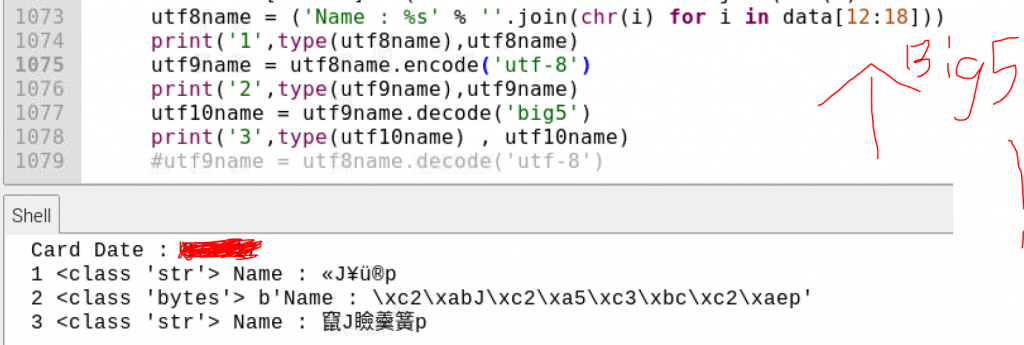
所需模組 Pyscard 環境 Linux
from smartcard.System import readers
SelectAPDU = [ 0x00, 0xA4, 0x04, 0x00, 0x10, 0xD1, 0x58, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x11, 0x00 ]
ReadProfileAPDU = [ 0x00, 0xca, 0x11, 0x00, 0x02, 0x00, 0x00 ]
r = readers()
reader = r[0]
connection.connect()
data, sw1, sw2 = connection.transmit(SelectAPDU)
data, sw1, sw2 = connection.transmit(ReadProfileAPDU)
print('姓名 : %s' % ''.join(chr(i) for i in data[12:32]))
已邀請的邦友 {{ invite_list.length }}/5
今天不想寫工作上的code,來幫忙解題好了。
讀取的code從下面抄的,改成python3。
https://gist.github.com/chihchun/4316159
from smartcard.System import readers
# define the APDUs used in this script
SelectAPDU = [ 0x00, 0xA4, 0x04, 0x00, 0x10, 0xD1, 0x58, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x11, 0x00 ]
ReadProfileAPDU = [ 0x00, 0xca, 0x11, 0x00, 0x02, 0x00, 0x00 ]
# get all the available readers
r = readers()
print ("Available readers:", r)
reader = r[0]
print ("Using:", reader)
connection = reader.createConnection()
connection.connect()
data, sw1, sw2 = connection.transmit(SelectAPDU)
print ("Select Applet: %02X %02X" % (sw1, sw2))
data, sw1, sw2 = connection.transmit(ReadProfileAPDU)
print ("Command: %02X %02X" % (sw1, sw2))
print ('Card Number : %s' % ''.join(chr(i) for i in data[0:12]))
# 讀卡機讀取進來的的資料的確是12~31這些byte,big5為雙位元字,所以在data中大概是前6~8個
# 在python3中,字串都是以bytes儲存的,你要顯示出來,只需要decode時指定正確的編碼就行了
print("name: {}".format(bytes(data[12:32]).decode("big5")))
print ('ID Number : %s' % ''.join(chr(i) for i in data[32:42]))
print ('Birthday : %s' % ''.join(chr(i) for i in data[43:49]))
print ('Sex : %s' % ''.join(chr(i) for i in data[49:50]))
print ('Card Date : %s' % ''.join(chr(i) for i in data[51:57]))
別再只貼圖了.
你應該用 str object has no attribute decode 去查一下啊.
Python3 跟 Python2 有很大不同.
Python 的開發時間很早,略早於Unicode,所以一直延續到比較長時間的版本 Python2,
都一直在 encode(), decode().
Python3 是有support Unicode的,所以不需要那樣麻煩,上面已經有兩位提醒你了.

{kind=link}
{kind=link}
{kind=link}