先附上自己的程式版本資訊:
python版本3.7(用Spyder IDE開發)
pandas版本0.23.4
為避免不同地區的行、列有歧義,
本問題指的行(columns)、列(row)為「直行橫列」
假設我們有大約1000個1*n的dataframe,
n的值大約是一萬左右,
dataframe中的每的格子是一個浮點數,
資料量非常大,
每個dataframe的column名稱可能重複也可能不重複,
我想要將這些dataframe串接成一個1000列的dataframe
目前想到的方法是用pandas內建的concat函數來做
為了方便測試,這邊我用隨機生成的資料表做測試,
(由於1000個dataframes有點多,測試只生成100個)
如下:
import random
import pandas as pd
import time
def random_str(length=4):
return ''.join([chr(ord('a')+random.randrange(26)) for _ in range(length)])
def random_df(col_num):
data = {}
for _ in range(col_num):
key = random_str()
data[key] = [random.uniform(0,1)]
return pd.DataFrame.from_dict(data)
random.seed(100) #為了確保每次產生的結果相同,設固定的seed
datas = [random_df(10000) for _ in range(100)]
## 以下開始做concat的測試
start = time.time()
res = pd.DataFrame()
for d in datas:
res = pd.concat([res,d], ignore_index=True)
end = time.time()
print(f"串接dataframes時間: {end-start:4f}")
這支程式首先生成100個「一列(row)*約10000行(column)」的資料表,
欄位名稱為隨機產生的4個英文字母,
然後用for迴圈合併
然而可能是資料量大,
一直做concat很耗時,
我在自己的電腦上執行這段程式碼(concat的部分)要651秒之久,
想問是否有好的加速方法呢?
非常感謝大家協助
由於跑651秒實在非常耗時,
以下給個迷你範例方便大家在自己電腦上測
以下程式在我的電腦上執行約8秒,還是有點久。
import random
import pandas as pd
import time
def random_str(length=4):
return ''.join([chr(ord('a')+random.randrange(26)) for _ in range(length)])
def random_df(col_num):
data = {}
for _ in range(col_num):
key = random_str()
data[key] = [random.uniform(0,1)]
return pd.DataFrame.from_dict(data)
random.seed(100) #為了確保每次產生的結果相同,設固定的seed
datas = [random_df(10000) for _ in range(5)]
## 以下開始做concat的測試
start = time.time()
res = pd.DataFrame()
for d in datas:
res = pd.concat([res,d], ignore_index=True)
end = time.time()
print(f"串接dataframes時間: {end-start:4f}")
已邀請的邦友 {{ invite_list.length }}/5
我改寫...167秒
i5-3470/8GB/win10 2004/python3.8.5 debug on VisualCode
import random
import pandas as pd
import time
def random_str(length=4):
return ''.join([chr(ord('a')+random.randrange(26)) for _ in range(length)])
def random_df(col_num):
data = {}
for _ in range(col_num):
key = random_str()
data[key] = [random.uniform(0,1)]
return data
start = time.time()
random.seed(100) #為了確保每次產生的結果相同,設固定的seed
datas=pd.DataFrame([random_df(10000) for _ in range(100)])
end = time.time()
print(datas)
print(f"組成dataframes時間: {end-start:4f}")
輸出
2 NaN NaN ... NaN NaN
3 NaN NaN ... NaN NaN
4 NaN NaN ... NaN NaN
.. ... ... ... ... ...
95 [0.7715769496453805] NaN ... NaN NaN
96 NaN NaN ... NaN NaN
97 NaN NaN ... NaN NaN
98 NaN NaN ... NaN NaN
99 [0.0783298473116465] NaN ... [0.26089702985762075] [0.4339433542861454]
看到這個方法突然恍然大悟XD
這裡再改成 data[key] = random.uniform(0,1)
輸出就一模一樣了
謝謝,我覺得是非常出色的解答~
用pd.DataFrame()一次性地創建一個dataframe真的快很多
因為我電腦跑 5 筆時間都差不多所以我改成 20 筆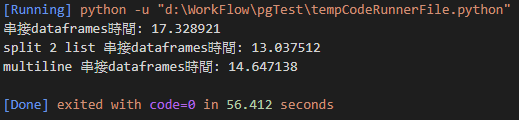
一開始的想法是拆成兩個去跑
start = time.time()
res1 = pd.DataFrame()
res2 = pd.DataFrame()
pivot = 0
bpivot = len(datas) -1
if (len(datas) % 2):
while pivot < bpivot:
res1 = pd.concat([res1, datas[pivot]], ignore_index=True)
res2 = pd.concat([datas[bpivot], res2], ignore_index=True)
pivot += 1
bpivot -= 1
res1 = pd.concat([res1, datas[pivot]], ignore_index=True)
res1 = pd.concat([res1, res2], ignore_index=True)
else:
while pivot < bpivot:
res1 = pd.concat([res1, datas[pivot]], ignore_index=True)
res2 = pd.concat([datas[bpivot], res2], ignore_index=True)
pivot += 1
bpivot -= 1
res1=pd.concat([res1, res2], ignore_index=True)
end = time.time()
print(f"串接dataframes時間: {end-start:4f}")
那既然可以用拆的去跑就直接跑多執行緒
不過我測使用兩個 thread 好像比直接跑還慢
import math
import threading
from queue import Queue
def concatList(arr):
res = pd.DataFrame()
for d in arr:
res = pd.concat([res,d], ignore_index=True)
q.put(res)
start = time.time()
q = Queue()
t1 = threading.Thread(target=concatList, args=(datas[:math.ceil(len(datas)/2)],))
t1.start()
res1 = pd.DataFrame()
for d in datas[math.ceil(len(datas)/2):len(datas)]:
res1 = pd.concat([res1, d], ignore_index=True)
t1.join()
res2 = q.get()
res1 = pd.concat([res1, res2], ignore_index=True)
end = time.time()
print(f"串接dataframes時間: {end-start:4f}")
謝謝分享,不過印象中好像threading模組仍然是單核心在模擬多線程的所以不會加速,要用multiprocessing模組才可以用CPU多核心同時一起跑(不知這樣講有沒有講錯~)
我後來去搜尋了一下的確像馬大說的這樣
要使用 multiprocessing 才能真正實現多核心XD
使用 Modin 套件,號稱可以從3.56秒(Pandas)縮短為0.041秒(Modin),範例如下,只要改第一行就可以從 Pandas 切換至 Modin。
import modin.pandas as pd
df = pd.read_csv("esea_master_dmg_demos.part1.csv")
s = time.time()
df = pd.concat([df for _ in range(5)])
e = time.time()
print("Modin Concat Time = {}".format(e-s))
做成series在concat 最後在transpose()
1000row的時間
def random_sr(col_num):
data = {}
for _ in range(col_num):
key = random_str()
data[key] = [random.uniform(0,1)]
return pd.Series(data)
datas = [random_sr(10000) for _ in range(1000)]
## 以下開始做concat的測試
start = time.time()
r2 = pd.concat(datas, axis=1, ignore_index=True)
r2 = r2.T
end = time.time()
print(f"串接dataframes時間: {end-start:4f}")
串接dataframes時間: 82.335420
r2.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Columns: 456976 entries, oitv to ndly
dtypes: object(456976)
memory usage: 3.4+ GB
intel-i7/16g/mac-os
