詢問一下各位高手
import tensorflow as tf
from sklearn.model_selection import train_test_split
import glob
import numpy as np
import os.path as path
import os
import cv2
IMAGEPATH = 'images'
dirs = os.listdir(IMAGEPATH)
X=[]
Y=[]
print(dirs);
w=32 # 224
h=32 # 224
i=0
for name in dirs:
file_paths = glob.glob(path.join(IMAGEPATH+"/"+name, '.'))
for path3 in file_paths:
img = cv2.imread(path3)
img = cv2.resize(img, (w,h), interpolation=cv2.INTER_AREA)
im_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
X.append(im_rgb)
Y.append(i)
i=i+1
請問這段CODE 後面為什麼會出現
img = cv2.resize(img, (w,h), interpolation=cv2.INTER_AREA)
cv2.error: OpenCV(4.5.1) C:\Users\appveyor\AppData\Local\Temp\1\pip-req-build-6uw63ony\opencv\modules\imgproc\src\resize.cpp:4051: error: (-215:Assertion failed) !ssize.empty() in function 'cv::resize'
已經有在網路上查詢可能為以下狀況
1.圖片路徑不對(確認過/方向正確)
2.資料夾內圖片都為JPG檔案
3.中文問題(圖片名稱皆用英文)
4.圖片格式不對(這個有些不太懂所以不知如何改變)
5.圖片數量不對(應該不會是這個問題吧)
已邀請的邦友 {{ invite_list.length }}/5
剛剛測試了一下,大概有幾個問題
路徑錯誤
join 已經會自己加 \ 了
for name in dirs:
file_paths = glob.glob(path.join(IMAGEPATH+"/"+name, '.'))
print(file_paths) 會變成
['IMAGEPATH路徑/xxx.jpg\\.']
可能改這樣
glob.glob(path.join(IMAGEPATH,name))
另一個問題有發現上面的顯示問題嗎?
會發現 file_paths 並沒有累加
你下面的迴圈,每次 file_paths 都被更新成新的那一筆
for name in dirs:
file_paths = glob.glob(path.join(IMAGEPATH+"/"+name, '.'))
所以你的 for 跑完還是只有最新的一筆
後續的沒有繼續再看,可能要依你的做法再調整
import tensorflow as tf
from sklearn.model_selection import train_test_split
import glob
import numpy as np
import os.path as path
import os
import cv2
IMAGEPATH = 'images'
dirs = os.listdir(IMAGEPATH)
X=[]
Y=[]
print(dirs);
w=400 # 4000
h=300 # 3000
i=8
for name in dirs:
file_paths = glob.glob(path.join(IMAGEPATH,name))
for path3 in file_paths:
img = cv2.imread(path3)
img = cv2.resize(img, (w,h), interpolation=cv2.INTER_AREA)
im_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
X.append(im_rgb)
Y.append(i)
i=i+1
可以詢問一下
我想把images資料夾內的八種資料夾當作訓練資料
但目前好像是讀取不到影像
請問可能發生的問題是在哪邊呢?
目前看起來是讀取不到且不會累加造成後續轉矩陣轉不了
圖片是4000*3000畫素
再麻煩了 謝謝
godman08
不確定你的檔案架構
可以先把 file_paths 或是 path3 列印出來看看路徑哪邊怪怪的
for name in dirs:
file_paths = glob.glob(path.join(IMAGEPATH,name))
print(file_paths)
for path3 in file_paths:
print(path3)
用DEBBUG模式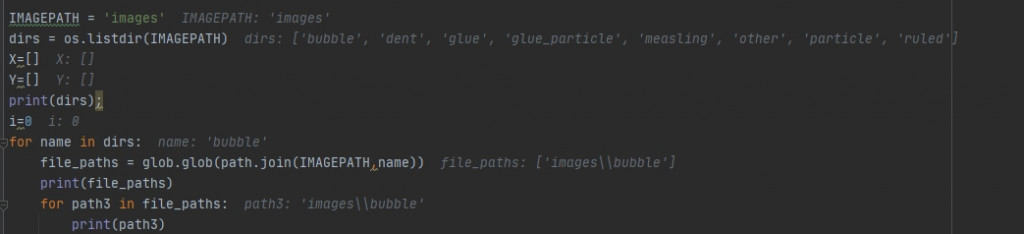
看起來路徑沒甚麼錯誤耶
godman08
你的 path3 和 file_paths 看起來一樣耶
正常 path3 應該已經要有 JPG 之類的副檔名,不然你 cv2 是讀不到的
for name in dirs:
file_paths = glob.glob(path.join(IMAGEPATH,name))
file_name = os.listdir(file_paths)
print(file_name) # 應該要是JPG清單
for path3 in file_name:
print(path.join(file_paths,path3))
img = cv2.imread(path.join(file_paths,path3))
另一個是你目前的PY檔 跟 images 資料夾是在同一個位置嗎
我自己資料夾會使用相對路徑
如 "./images"
不好意思~新手問題很多
想請問一下改成這程式碼後
出現
TypeError: listdir: path should be string, bytes, os.PathLike or None, not list
是說路徑應該是字串嗎??
另外PY檔案跟IMAGES資料夾是在同一個位置唷
也改成這樣了
IMAGEPATH = './images'
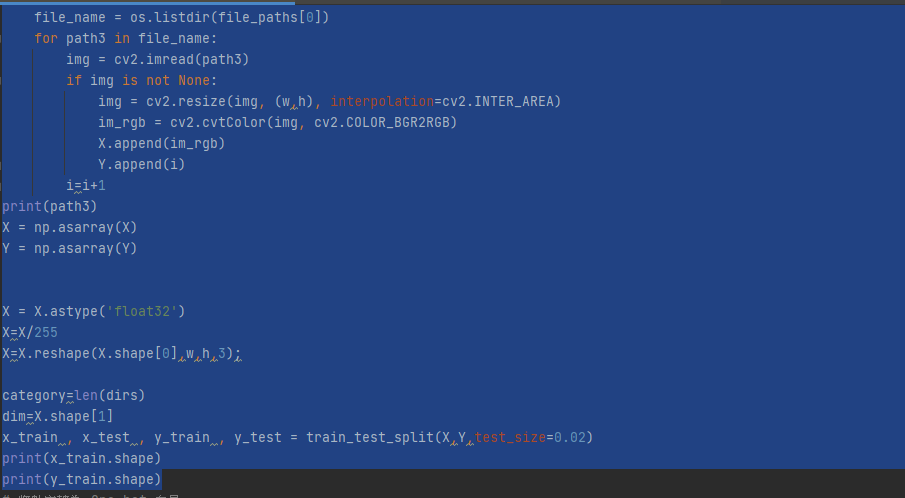
godman08
看來是 glob.glob() 出來是一個 list
所以要再把存的路徑挑出來
file_name = os.listdir(file_paths[0])
ValueError: With n_samples=0, test_size=0.02 and train_size=None, the resulting train set will be empty. Adjust any of the aforementioned parameters.
好像訓練集是空的
samples = 0
應該是圖片還是沒讀到,所以整個資料是空的
照你的設定
path3 是利用 for 逐一取得 file_name 這個路徑資料夾裡面的圖片名稱(list)
但是只有名稱,所以在 cv2.imread 讀取時要把前段的路徑加進去
前段的路徑則存在 file_paths 這個 list 內
所以才說要確認整個圖片讀取的路徑是否正確
for path3 in file_name:
print(path.join(file_paths[0],path3))
img = cv2.imread(path.join(file_paths[0],path3))
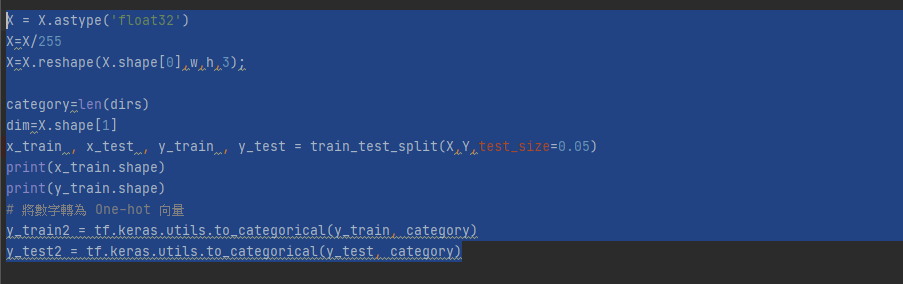
詢問一下 我想要把數字轉為one hot 降低電腦負擔
可是出現
IndexError: index 75 is out of bounds for axis 1 with size 8
是指index 75 超出邊界嗎?
麻煩了 感謝
看來是有順利讀到圖了,所以這算另一個問題了
程式碼不完整要前後猜
先猜測你的圖可能是76張
print(Y)
如果裡面的值超過7,代表分類錯了
因為有8個影像資料夾,所以分類照理會是
[0,1,2,3,4,5,6,7]
因此換一個資料夾 i+1
把 i=i+1 再往前一個 for 迴圈吧
圖片種類共8種
各有
1-36張
2-23張
3-8張
4-1張
5-24張
6-9張
7-9張
8-7張
共117張
好像消失了6張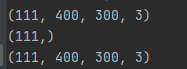
另外再訓練模組的時候發現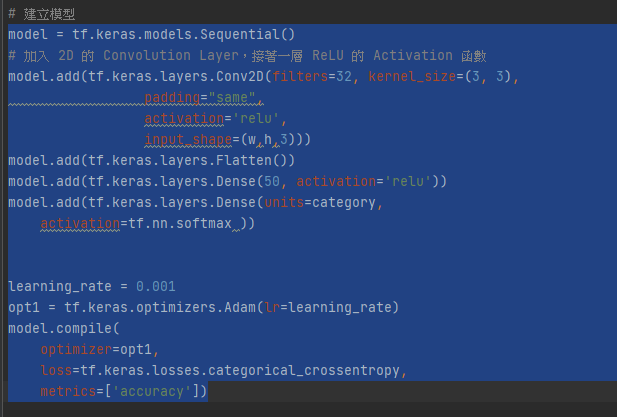
好像是用flatten無法轉成1D維度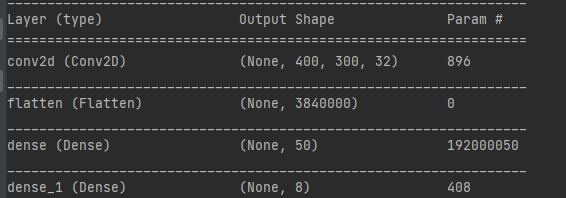
你的顯示是不是 train
若是的話,你的 test_size = 0.05
117 x 0.05 = 5.85 => 6張在 test
另外你已經攤平了啊 不是沒錯誤?
400 x 300 x 32 =3840000
方便提供學習來源嗎? 感覺難度跳好多

跑完訓練集後會出現
ValueError: Shapes (3840000, 50) and (32768, 50) are incompatible
學習來源是柯博文老師出的這本書哦
看上面說明是有附範例檔案的喔
建議再比對差異,或是用其他的方式讓人理解完整程式碼
我自己會先用設定的跑看看,逐一調整
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
參考資料
https://stackoverflow.com/questions/61742556/valueerror-shapes-none-1-and-none-2-are-incompatible
https://www.tensorflow.org/tutorials/images/cnn
