感謝前輩在前一篇問題指點迷津,前文連結如下
前文連結
延伸前一篇的問題,目前的想要針對TypeD和E的資料集,若有溢位,則將它分配在溢位區,如下圖所示。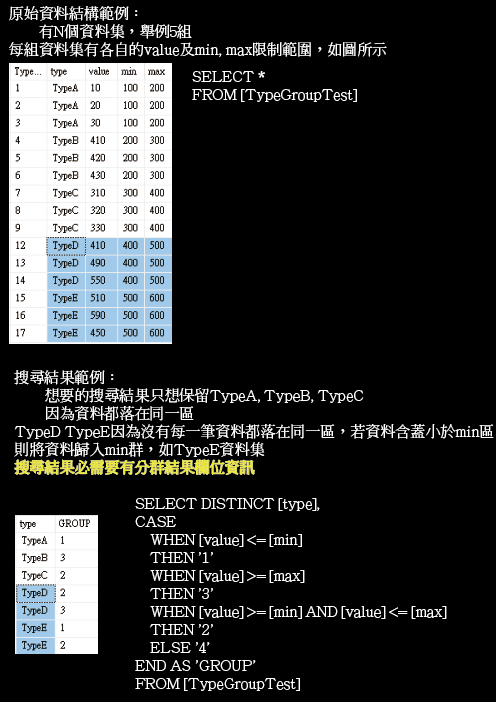
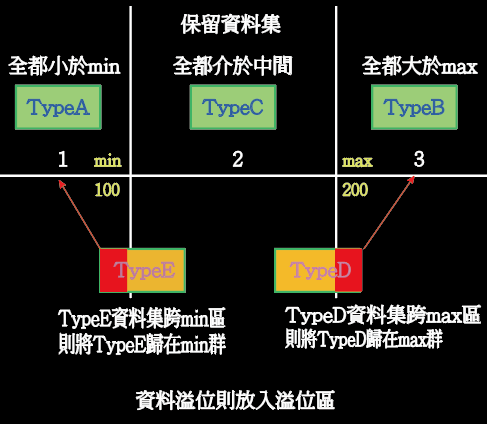
主要著重在要如何處理TypeD, TypeE資料集,如圖示若集料集有含跨小於min區或大於max區,則將資料集歸類在小於min區或大於max區的群組,不要歸類在中間區,也不要讓資料在兩個區域都有歸類。
不好意思,再度請教各位大大指點,感激不盡~
已邀請的邦友 {{ invite_list.length }}/5
依版主描述整合如下 :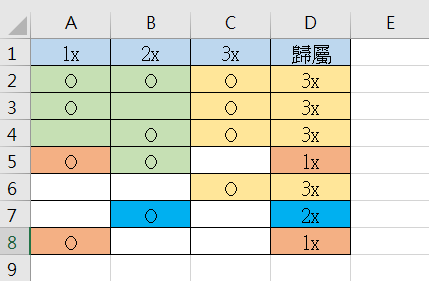
CREATE TABLE TypeGroupTest (
XTypeNo int NULL ,
Xtype nvarchar(40) NULL ,
Xvalue int NULL ,
Xmin int NULL ,
Xmax int NULL);
INSERT INTO TypeGroupTest (XTypeNo,Xtype,Xvalue,Xmin,Xmax)
VALUES
(1,'TypeA',10,100,200),
(2,'TypeA',20,100,200),
(3,'TypeA',30,100,200),
(4,'TypeB',410,200,300),
(5,'TypeB',420,200,300),
(6,'TypeB',430,200,300),
(7,'TypeC',310,300,400),
(8,'TypeC',320,300,400),
(9,'TypeC',330,300,400),
(12,'TypeD',410,400,500),
(13,'TypeD',490,400,500),
(14,'TypeD',550,400,500),
(15,'TypeE',510,500,600),
(16,'TypeE',590,500,600),
(17,'TypeE',450,500,600),
-- 額外加入
(18,'TypeD',505,400,500),
(19,'TypeD',506,400,500),
(20,'TypeF',590,500,600),
(21,'TypeF',450,500,600),
-- 額外加入PART2
(22,'TypeG',450,600,700),
(23,'TypeG',460,600,700),
(24,'TypeG',470,600,700),
(25,'TypeG',650,600,700),
(26,'TypeG',660,600,700),
(27,'TypeG',850,600,700),
(28,'TypeG',860,600,700),
(29,'TypeG',870,600,700),
-- 額外加入PART3
(30,'TypeH',NULL,NULL,NULL);
SELECT Xtype,X1,X2,X3,
CASE
WHEN X3 IS NOT NULL THEN 'X3'
WHEN X3 IS NULL AND X1 IS NOT NULL THEN 'X1'
WHEN X3 IS NULL AND X1 IS NULL AND X2 IS NOT NULL THEN 'X2'
WHEN X3 IS NULL AND X1 IS NULL AND X2 IS NULL THEN NULL
END AS XGROUP_NEW
FROM (
SELECT Xtype,1 as TempValue,
CASE
WHEN Xvalue <= Xmin
THEN 'X1'
WHEN Xvalue >= Xmax
THEN 'X3'
WHEN Xvalue > Xmin AND Xvalue < Xmax
THEN 'X2'
END AS XGROUP
FROM TypeGroupTest) AS TempA
PIVOT( SUM(TempValue) FOR XGROUP IN (X1, X2, X3)) TempP
ORDER BY Xtype
感謝前輩指教,目前單位使用的cloudera好像不支援PIVOT語法
所以目前先用UNION的方式來達到我的目的
Demo
SELECT [Xtype],[XGROUP]
FROM (
SELECT [Xtype],[XGROUP],
COUNT(1) OVER(PARTITION BY [Xtype]) AS ROWNUM
FROM (
SELECT DISTINCT [Xtype],
CASE
WHEN [Xvalue] <= [Xmin]
THEN 'X1'
WHEN [Xvalue] >= [Xmax]
THEN 'X3'
WHEN [Xvalue] BETWEEN [Xmin] AND [Xmax]
THEN 'X2'
END AS [XGROUP]
FROM [TypeGroupTest]) AS TempA
) AS TempB
WHERE ROWNUM=1
UNION
SELECT [Xtype],[XGROUP]
FROM (
SELECT [Xtype],[XGROUP],
COUNT(1) OVER(PARTITION BY [Xtype]) AS ROWNUM
FROM (
SELECT DISTINCT [Xtype],
CASE
WHEN [Xvalue] <= [Xmin]
THEN 'X1'
WHEN [Xvalue] >= [Xmax]
THEN 'X3'
ELSE 'X4'
END AS [XGROUP]
FROM [TypeGroupTest]) AS TempA
) AS TempB
WHERE ROWNUM=2 AND XGROUP <> 'X4'
UNION
SELECT [Xtype],[XGROUP]
FROM (
SELECT [Xtype],[XGROUP],
COUNT(1) OVER(PARTITION BY [Xtype]) AS ROWNUM
FROM (
SELECT DISTINCT [Xtype],
CASE
WHEN [Xvalue] <= [Xmin]
THEN 'X1'
WHEN [Xvalue] >= [Xmax]
THEN 'X3'
ELSE 'X2'
END AS [XGROUP]
FROM [TypeGroupTest]) AS TempA
) AS TempB
WHERE ROWNUM=3 AND XGROUP NOT IN ('X1', 'X2')
這樣感覺很瞎...><
海綿寶寶 也可以這樣說,Type 是一堆還沒有被歸類的資料,剛好同一個type都視為同一組資料,處理資料時再透過SQL針對條件來重新歸類分群
cloudera好像不支援PIVOT語法,那就換個語法.
SELECT Xtype,X1,X2,X3,
CASE
WHEN X3 <> 0 THEN 'X3'
WHEN X3 = 0 AND X1 <> 0 THEN 'X1'
WHEN X3 = 0 AND X1 = 0 AND X2 <> 0 THEN 'X2'
WHEN X3 = 0 AND X1 = 0 AND X2 = 0 THEN NULL
END AS XGROUP_NEW
FROM (
SELECT Xtype,
SUM(CASE WHEN XGROUP='X1' THEN TempValue ELSE 0 END) AS 'X1',
SUM(CASE WHEN XGROUP='X2' THEN TempValue ELSE 0 END) AS 'X2',
SUM(CASE WHEN XGROUP='X3' THEN TempValue ELSE 0 END) AS 'X3'
FROM (
SELECT Xtype,1 as TempValue,
CASE
WHEN Xvalue <= Xmin
THEN 'X1'
WHEN Xvalue >= Xmax
THEN 'X3'
WHEN Xvalue > Xmin AND Xvalue < Xmax
THEN 'X2'
END AS XGROUP
FROM TypeGroupTest) AS TempA
GROUP BY Xtype
) AS TempB
ORDER BY Xtype
這語法真是太強了,獲益良多,超級感謝~


