目前在抓取Yahoo新聞裡面完整的內容
是使用BeautifulSoup和scrapy來抓取
在抓取時遇到一個問題,就是目標tag底下還有其他tag或者其他東西
所以會抓出不只是新聞內容的文字
舉例來說,新聞內容都放在<div> class="caas-body" 底下的<p>裡面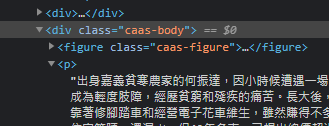
但是有的<p>裡面還會有其他tag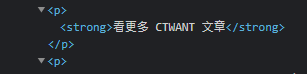
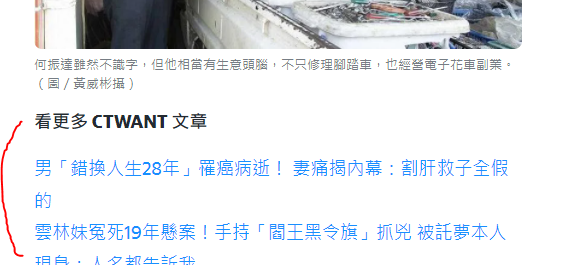
或是出現其他非內容的東西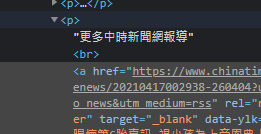

因為不是新聞內容,所以不需要抓出來
想請問有沒有方法可以只抓取乾淨的<p>(裡面除了文字沒有其他雜質)裡面的內容就好?
程式如下:
import scrapy
from bs4 import BeautifulSoup
class YahooCrawler(scrapy.Spider):
name = 'yahoo'
start_urls = (['https://tw.news.yahoo.com/%E7%94%B7%E5%AD%90%E6%BC%A2%E4%B9%8B%E7%B4%841-%E7%88%B6%E8%87%A8%E7%B5%82%E5%8F%AE%E5%9B%91-%E8%A6%81%E5%A0%85%E6%8C%81-%E6%B4%BB%E8%8F%A9%E8%96%A9-%E9%98%BF%E9%81%94%E5%93%A5-220000852.html'])
def parse(self, response):
res = BeautifulSoup(response.body)
for content in res.select('div.caas-body p'):
print(content.get_text())
已邀請的邦友 {{ invite_list.length }}/5
for content in bsObj.select('div.caas-body p'):
# 看底下有沒有其他 tag
children = content.findChild()
# 沒有的話才是想要的
if children == None:
print(content.get_text())
這邊問一個蠢問題,小弟完全程式新手
大大的這個方法有想過,但是我的想法是
content.get_text()這個指令只要執行
就是把所有找到符合的tag內容都印出來
不會因為前面的條件而改變
雖然前面有if的條件,但也只是在這個條件下
把原本所有找到符合的tag內容都印出來
因為感覺content沒有被改變
請問這個觀念該怎麼調整?
for迴圈觀念不足? 還是if 或者是值被賦予另個值不了解
比如一個籃子裡面有的很多不同顏色的球
有個動作是(好比content.get_text()): 抓出所有印有A字樣的球
children = content.findChild() = 數一數球裡面還有沒有球
if children == None: = 若球裡面沒有球
print(content.get_text()) = 抓出所有印有A字樣的球
結果還是不會因為裡面有沒有球而改變...
for in 在做甚麼,content 是去迭代res.select('div.caas-body p')找到符合的tag。是「一個接一個」去迭代。所以for in裡面執行的程式碼,是「一個接一個」針對符合的tag去做判斷。就代表content是「某一個」符合的tag。LIST = [x for x in range(1, 5)]
for i in LIST:
if i % 2 :
print(i) # 如果你說的對,這裡應該印出整個 LIST
謝謝,找時間仔細了解一下
