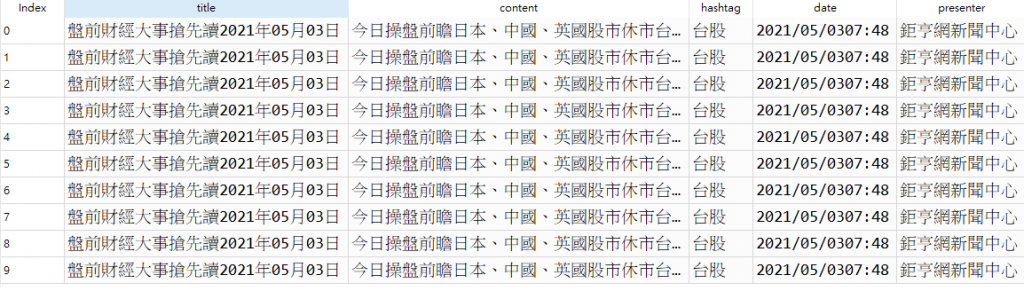
大家好,小弟是個爬蟲菜鳥,只會美麗的湯,近日爬鉅亨發現都只能爬出相同的文章標題,附件是我的code,謝謝大家~
#鉅亨基金新聞爬蟲
#https://news.cnyes.com/news/cat/fund
#https://news.cnyes.com/news/id/4646317 #每篇id
#假日無文,先爬五月份 5/1~5/16
import requests
from bs4 import BeautifulSoup
import time #for sleep 禮貌
#import datetime #計算爬蟲時間,未完
start_page = 4623040 #2020-01-02 4429138 2021-01-01 4555021
end_page = 4646459 #2021-05-14
title =[]
content = []
hashtag = []
date =[]
presenter =[]
#%%
'1萬篇 23:17 '
for page in range(start_page, end_page):
url = 'https://news.cnyes.com/news/id/4623040'#需更新
url = url.replace('x', str(start_page))
res = requests.get(url)#200 正常
soup = BeautifulSoup(res.text, 'html.parser')
#開爬 不乾淨,後面.text清除
title_get = soup.select('._uo1n h1')
content_get = soup.select('._2E8y')
hashtag_get = soup.select('._1E-R') #含相關個股(拆不掉)
date_get = soup.select('._1R6L time')
presenter_get = soup.select('._3lKe')
for items in range(len(title_get)):
title.append(title_get[items].text.replace('\n', '').replace(' ', ''))
content.append(content_get[items].text.replace('\n', '').replace(' ', ''))
hashtag.append(hashtag_get[items].text.replace('\n', '').replace(' ', ''))
date.append(date_get[items].text.replace('\n', '').replace(' ', ''))
presenter.append(presenter_get[items].text.replace('\n', '').replace(' ', ''))
print('時間:' ,date)
time.sleep(0.1) #通常設1或.5
print(title,content,hashtag,date,presenter)
#%%
import pandas as pd
df = pd.DataFrame({'title':title, 'content':content, 'hashtag':hashtag, 'date':date, 'presenter':presenter})
df.to_csv('D:/2021-01-01~2021-05-17鉅亨.csv',encoding='utf_8_sig')
已邀請的邦友 {{ invite_list.length }}/5
你抓取同一個網頁是因為你的網址沒更改
url = 'https://news.cnyes.com/news/id/' + str(page) #需更新
像是第二個要抓得網頁id是4623041
這篇就沒有內文
所以要去判斷沒內文的網頁就不爬
另外tag你沒抓完整
hashtag_get = soup.select('._1qS9._2Zhy ._1E-R') #含相關個股(拆不掉)
for i in hashtag_get:
hashtag.append(i.text.strip())
改完的就大概這樣
#鉅亨基金新聞爬蟲
#https://news.cnyes.com/news/cat/fund
#https://news.cnyes.com/news/id/4646317 #每篇id
#假日無文,先爬五月份 5/1~5/16
import requests
from bs4 import BeautifulSoup
import time #for sleep 禮貌
#import datetime #計算爬蟲時間,未完
start_page = 4623040 #2020-01-02 4429138 2021-01-01 4555021
end_page = 4646459 #2021-05-14
title =[]
content = []
hashtag = []
date =[]
presenter =[]
#%%'1萬篇 23:17 '
for page in range(start_page, end_page):
url = 'https://news.cnyes.com/news/id/' + str(page) #需更新
url = url.replace('x', str(start_page))
res = requests.get(url)#200 正常
soup = BeautifulSoup(res.text, 'html.parser')
#開爬 不乾淨,後面.text清除
title_get = soup.select('._uo1n h1')
content_get = soup.select('._2E8y')
hashtag_get = soup.select('._1qS9._2Zhy ._1E-R') #含相關個股(拆不掉)
for i in hashtag_get:
hashtag.append(i.text.strip())
date_get = soup.select('._1R6L time')
presenter_get = soup.select('._3lKe')
for items in range(len(title_get)):
title.append(title_get[items].text.replace('\n', '').replace(' ', ''))
content.append(content_get[items].text.replace('\n', '').replace(' ', ''))
date.append(date_get[items].text.replace('\n', '').replace(' ', ''))
presenter.append(presenter_get[items].text.replace('\n', '').replace(' ', ''))
print('時間:' ,date)
time.sleep(0.1) #通常設1或.5
print(title,content,hashtag,date,presenter)
import pandas as pd
df = pd.DataFrame({'title':title, 'content':content, 'hashtag':hashtag, 'date':date, 'presenter':presenter})
df.to_csv('D:/2021-01-01~2021-05-17鉅亨.csv',encoding='utf_8_sig')

 iThome鐵人賽
iThome鐵人賽