最近剛開始學習各種演算法 沒想到第一關我就卡住了...
教授丟給我一筆資料叫我去跑看看 但我總是跑不出來預測的資料準確度
想請問各位學長姊 我應該怎麼做
import pandas as pd #表格
import numpy as np #維度陣列與矩陣運算
import string #字串
import matplotlib.pyplot as plt #匯入數學算式
from sklearn.model_selection import train_test_split
import tensorflow
from tensorflow.keras import backend as k
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
from tensorflow.keras.layers import Dropout
import math
import h5py
from keras import optimizers
from keras.callbacks import EarlyStopping
def getDistance(latA, lonA, latB, lonB):
ra = 6378140 # 赤道半徑
rb = 6356755 # 極半徑
flatten = (ra - rb) / ra # Partial rate of the earth
# change angle to radians
radLatA = math.radians(latA)
radLonA = math.radians(lonA)
radLatB = math.radians(latB)
radLonB = math.radians(lonB)
pA = math.atan(rb / ra * math.tan(radLatA))
pB = math.atan(rb / ra * math.tan(radLatB))
x = math.acos(math.sin(pA) * math.sin(pB) + math.cos(pA) * math.cos(pB) * math.cos(radLonA - radLonB))
c1 = (math.sin(x) - x) * (math.sin(pA) + math.sin(pB)) ** 2 / math.cos(x / 2) ** 2
c2 = (math.sin(x) + x) * (math.sin(pA) - math.sin(pB)) ** 2 / math.sin(x / 2) ** 2
dr = flatten / 8 * (c1 - c2)
distance = ra * (x + dr)
distance = round(distance / 1000, 4)
return distance
def mape(act,pred):
diff = abs((act - pred) / (abs(act)))
# print(diff)
return 100. * np.mean(diff)
def rmse(act,pred):
return math.sqrt(np.mean((pred - act)**2))
#def cal_distance(lon1, lat1, lon2, lat2):
# lon1, lat1, lon2, lat2 = map(math.radians, [lon1, lat1, lon2, lat2])
# dlon = lon2-lon1
# dlat = lat2-lat1
# a = math.sin(dlat/2)**2 + math.cos(lat1)*math.cos(lat2)*math.sin(dlon/2)**2
# c = 2*math.asin(math.sqrt(a))
# r = 6371
# return c * r * 1000
dataframe = pd.read_csv(r'C:\Users\Song You Chen\Desktop\vessels\TEST_data.csv')
dataframe = dataframe[["Lon","Lat"]]
dataframe = dataframe.dropna(axis='rows')
dataframe = dataframe.drop_duplicates(keep = 'first' , inplace= False)
dataset = dataframe.values
data = dataframe.values
data_scaler = dataset.astype('float64')
plt.scatter(data[:, 0], data[:, 1], c='r', marker='o', label='pre_true')
train,test = train_test_split(dataset,test_size=0.1,random_state=0)
def create_dataset(dataset, look_back):
dataX, dataY = [], []
for i in range(len(dataset) - look_back - 1):
a = dataset[i:(i + look_back)]
dataX.append(a)
dataY.append(dataset[i + look_back])
return np.array(dataX), np.array(dataY)
#reshape into X = t, Y = t+1 //建立落後期
look_back = 2
trainX, trainY= create_dataset(train, look_back)
testX, testY= create_dataset(test, look_back)
#LSTM網路輸入結構:(資料集, 時間步長, 特徵) 一維
#reshape input to be [sample, time, features]
trainX = np.reshape(trainX, (trainX.shape[0], trainX.shape[1], 2))
testX = np.reshape(testX, (testX.shape[0], testX.shape[1], 2))
model = Sequential() #使用Window Method的堆疊LSTM層
#keras.layers.normalization.BatchNormalization(momentum=0.99, epsilon=0.001, center=True, scale=True, beta_initializer='zeros', gamma_initializer='ones', moving_mean_initializer='zeros', moving_variance_initializer='ones', beta_regularizer=None, gamma_regularizer=None, beta_constraint=None, gamma_constraint=None)
model.add(LSTM(256, input_shape=(look_back, 2),
#activation='relu',
return_sequences=True,
recurrent_activation='relu',
))
# model.add(Conv1D(filters=64, kernel_size=2, activation='relu'))
# model.add(BatchNormalization())
model.add(LSTM(128, activation='relu',
return_sequences=True,
# recurrent_activation='relu',
# kernel_regularizer=keras.regularizers.l1(0.001),
# kernel_regularizer=keras.regularizers.l1(0.001),
dropout = 0.0))
model.add(LSTM(128, activation='relu',
return_sequences=False,
# recurrent_activation='relu',
# kernel_regularizer=keras.regularizers.l1(0.001),
# kernel_regularizer=keras.regularizers.l1(0.001),
dropout = 0.0))
'''
model.add(LSTM(2, activation='relu',
recurrent_activation='tanh',
dropout = 0.2))
'''
#建立全連接層
# model.add(Dense(10, kernel_initializer ='normal', activation='relu'))
# model.add(Flatten())
# model.add(Dense(10))
model.add(Dense(2))
#優化器調參及選擇
# sgd = optimizers.SGD(lr=0.00001, decay=1e-6, momentum=0.9, nesterov=True)
#adam = optimizers.Adam(lr=0.00001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=1e-5)
adam = optimizers.Adam(lr=0.001)
# rmsprop = optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=None, decay=1e-6)
model.compile(loss='mean_squared_error', optimizer = 'adam')
model.summary()
train_history = model.fit(trainX, trainY,
epochs=100,
batch_size=64,
validation_split=0.2,
verbose=2)
#earlystopping建立, 模型訓練
model.save(r'C:\Users\Song You Chen\Desktop\vessels\loss046_049.h5')
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
print("MAPE:",mape(testY,testPredict))
print("RMSE:",rmse(testY,testPredict))
plt.clf()
plt.scatter(testY[:, 0], testY[:, 1], c='g', marker='o', label='true')
plt.scatter(testPredict[:, 0], testPredict[:, 1], c='r', marker='p', label='Predict')
plt.legend(loc='upper right')
plt.grid()
plt.show()
#print("直線距離(KM):",cal_distance(testY[:1,0],testY[:1,1], testPredict[:1,0], testPredict[:1,1]))
number = 0
for i in range(len(testY)):
X = getDistance(testY[i,0],testY[i,1],testPredict[i,0],testPredict[i,1])
number = number + X
score = number / len(testY)
但跑出來的圖卻是背離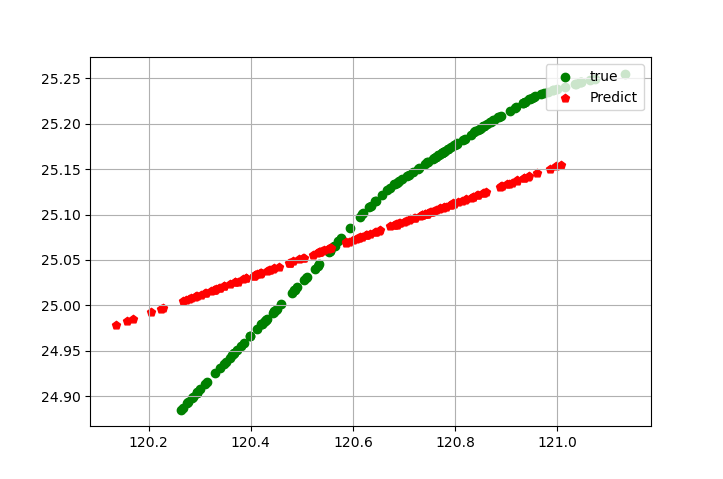
算出來的距離相差了28km 但老師的答案卻只有400m
已邀請的邦友 {{ invite_list.length }}/5
使用LSTM不應該隨機切割。
train,test = train_test_split(dataset,test_size=0.1,random_state=0)
應為
train,test = train_test_split(dataset,test_size=0.1, shuffle=False)
