嘗試將多個csv檔案concatenate在一起,其中一個字串欄位含有RE或沒有RE,想嘗試擷取日期和時間。使用IF-ELSE敘述 但兩者substring的結果是一樣位置的字串,想請問我的IF-ELSE敘述哪裡寫錯了,請幫忙指證,謝謝! 目前輸出的結果如下圖所示。
import pandas as pd
import numpy as np
import os
path_dataset = r'C:\Users\test'
def get_file(path_dataset):
files = os.listdir(path_dataset) #check file list
files.sort() #sort file
file_list = []
for file in files:
path = path_dataset + "\\" + file
if (file.startswith("test")) and (file.endswith(".csv")):
file_list.append(path)
return (file_list)
read_columns = ['NAME']
read_files = get_file(path_dataset)
all_df = []
for file in read_files:
df = pd.read_csv(file, usecols = read_columns)
if (str(df['NAME'].astype(str).str[23:25]) == 'RE-'):
df['DATE_TIME'] = df['NAME'].astype(str).str[26:40]
else:
df['DATE_TIME'] = df['NAME'].astype(str).str[22:37]
all_df.append(df)
Concat_table = pd.concat(all_df, axis=0)
Concat_table = Concat_table.sort_values(['DATE_TIME'])
Concat_table.head()
Concat_table.to_csv(os.path.join(path_dataset, 'Concate_all.csv'), index=False)
執行以上程式碼的結果:
預期跑出的結果: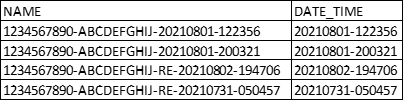
已邀請的邦友 {{ invite_list.length }}/5
Python 的範圍是含開始不含結束,[23:25] ==> 只取23、24,不含25。
if (str(df['NAME'].astype(str).str[23:25]) == 'RE-'):
df['DATE_TIME'] = df['NAME'].astype(str).str[26:40]
else:
df['DATE_TIME'] = df['NAME'].astype(str).str[22:37]
用正則表達式re,犯不著一堆if判斷中間有出現-RE- (一堆RE是怎樣...)
把你的程式改成這樣
import re
#.............中間省略你的程式1001字
matches = re.search(r'(\d+)-\d+\s*$',df['NAME'])
if matches is not None :
df['DATE_TIME'] = matches.group(1)
上面那個規則是以最後兩個-都是全數字,所以用\d+,如果長度完全固定,可以改用\d{8}代表日期那段,後面那段不明長度所以用\d+,如果會出現英文字母且大小寫不一定的話,可以改成 [a-zA-Z0-9]+
matches = re.search(r'(\d{8})-[a-zA-Z0-9]+\s*$',df['NAME'])
後面跟著\s*的意思是......可能會夾白在尾端,資料庫匯入時常常會有的狀況
至於錢字號$ 是指字串的尾巴
謝謝教學使用正則表達式,但我套入兩種matches的寫法都會出現error。
請問是這樣寫嗎?
for file in read_files:
df = pd.read_csv(file, usecols = read_columns)
matches = re.search(r'(\d+)-\d+\s*$',df['NAME'])
if matches is not None :
df['DATE_TIME'] = matches.group(1)
all_df.append(df)
出現如下error code:
TypeError: expected string or bytes-like object
df["NAME"] 是 byte
幫他穿個decode的外套
matches = re.search(r'(\d+)-\d+\s*$',df['NAME'].decode("utf-8"))
