小弟目前只學習了基本的python語法,其他套件都還沒完全學會(有開始看pandas用法了)
雖然組長有簡單指導我方向(用for迴圈取值)然後用pandas來做更動,但實在還是不太有頭緒
希望可以請教各位大大我該怎麼做比較好QQ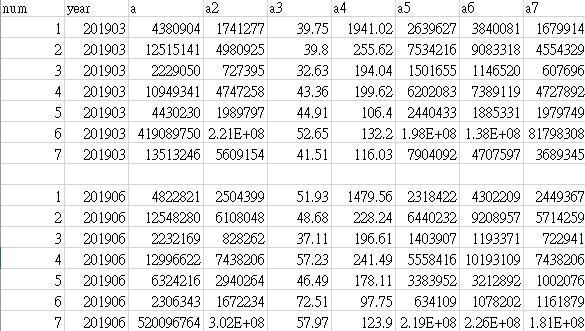
這是要處理的csv檔的長相,資料分為ID、年分、a~a7這幾項
每筆資料都是某機構在某年某季的資料,組長希望我重新將資料整理成為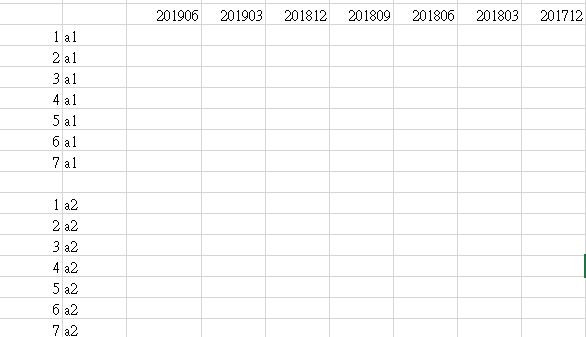
改成某機構在a的資料以時間排序 接著在做a2、a3、a4......
目前只想的到可以用isin去抓各個機構在每一季的所有資料然後再慢慢的把它改成組長要的規
格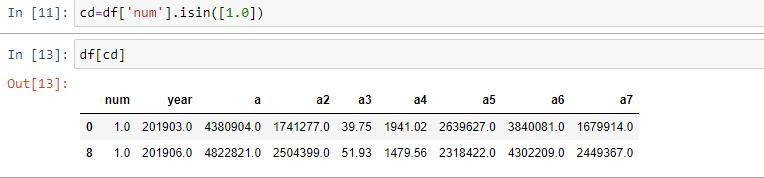
但資料其實不是只有短短的這幾筆,如果真的這樣做完大概要花上好幾天...
現在會取出a1和年份了 不知道這樣做正不正確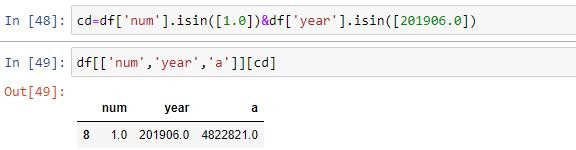
希望大家能指點迷津QQ....
已邀請的邦友 {{ invite_list.length }}/5
data = {
"id": ["1", "2", "3", "4"],
"year": ["201903", "201903", "201904", "201905"],
"a1": [123, 456, 789, 165165],
"a2": ["abc", "cde", "ttt", "7414"],
}
import pandas as pd
df = pd.DataFrame(data)
t = df.pivot("id", columns="year", values=["a1", "a2"])
a1 = t.loc[:, "a1"]
a1.loc[:,"type"] = "a1"
a2 = t.loc[:, "a2"]
a2.loc[:,"type"] = "a2"
pd.concat([a1,a2])
估計a1, a2....,a7 可以用stack之類的拉出來,
但我懶得想了所以你直接寫個fun撈吧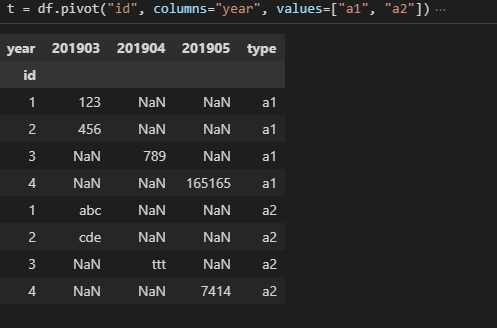
幫你寫好了,自己研究看看這些方法是做啥的吧df.pivot df.reset_index df.drop df.fillna df.rename df.append df.keys pd.Series pd.concat
import pandas as pd
df_before = pd.DataFrame({
'num': ['1', '2', '3', '4', '5', '6', '7', '', '1', '2', '3', '4', '5', '6', '7'],
'year': ['201903', '201903', '201903', '201903', '201903', '201903', '201903', '', '201906', '201906', '201906', '201906', '201906', '201906', '201906'],
'a1': [1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1, '', 1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1],
'a2': [1.2, 2.2, 3.2, 4.2, 5.2, 6.2, 7.2, '', 1.2, 2.2, 3.2, 4.2, 5.2, 6.2, 7.2],
'a3': [1.3, 2.3, 3.3, 4.3, 5.3, 6.3, 7.3, '', 1.3, 2.3, 3.3, 4.3, 5.3, 6.3, 7.3],
})
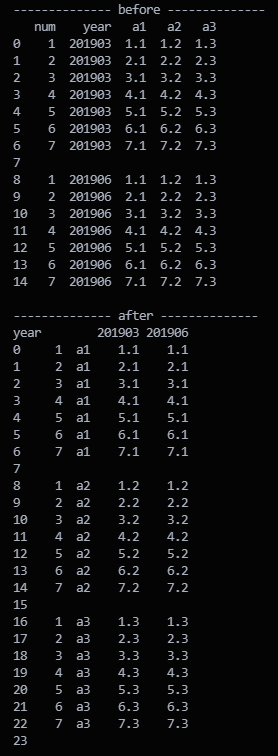
print("-------------- before --------------")
print(df_before)
print()
# 修改 row 和 column
df_pivot = df_before.pivot(index='num', columns='year')
# 做點整理
df_list = [df_pivot[key].reset_index(drop=True).drop([0]).fillna(key).rename(columns={'year': ''}).reset_index().append(pd.Series(dtype='float'), ignore_index=True).fillna('') for key in df_before.drop(['num', 'year'], axis=1).keys()]
# 組合
df_after = pd.concat(df_list).reset_index(drop=True).rename(columns={'index': ''})
# 儲存
df_after.to_csv('Result.csv', index=False)
print("-------------- after --------------")
print(df_after)
print()
先用Python 把要填入的值都用print生成出來
然後再Pandas取出對的位置
這樣就可以把值填入到xlsx內
