你原本的查詢變成子查詢,以下是隨手寫的,不見得是正確的,你參考看看
select keyword, cnt, rank() over(order by cnt desc)
from (select keyword, count(*) as cnt
from tbl
group by keyword) a;
CREATE TABLE webkeyword (
keyword varchar(20));
INSERT INTO webkeyword (keyword)
VALUES
('BB'),
('BB'),
('BB'),
('CC'),
('CC'),
('CC'),
('CC'),
('AA'),
('AA'),
('AA'),
('AA'),
('AA'),
('DD');
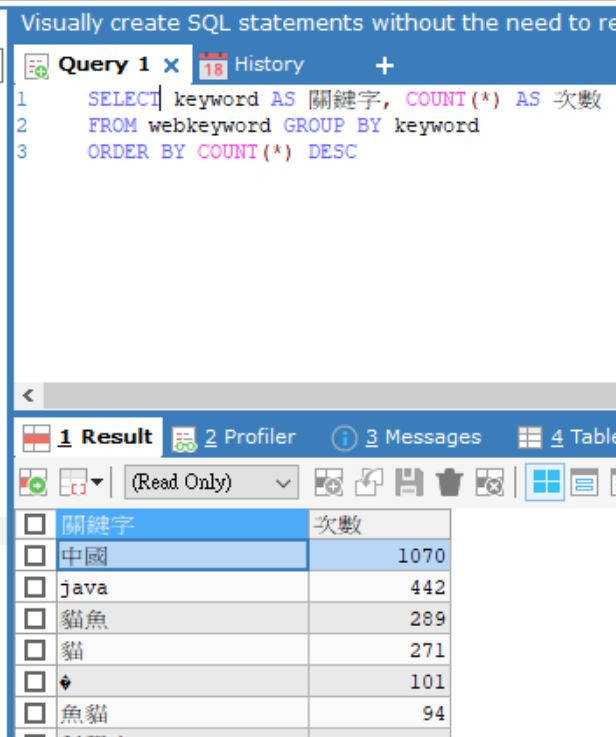
SELECT RANK() OVER (ORDER BY COUNT(1) DESC) AS '排名',
keyword AS '關鍵字',COUNT(1) AS '次數'
FROM webkeyword
GROUP BY keyword
1.參考這篇
2.之前問的問題,如果已解決的話,選個最佳解答以結案
我也來插一腳(逃...
declare @Tmp table(
Str nvarchar(50)
)
insert into @Tmp
values(N'中囯')
,(N'中囯')
,(N'中囯')
,(N'中囯')
,(N'中囯')
,(N'中囯')
,(N'Java')
,(N'Java')
,(N'Java')
,(N'貓魚')
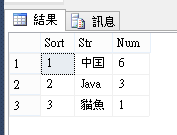
select Row_Number()Over(order by count(0) desc) Sort
,Str
,count(0) Num
from @Tmp
group by Str
可以使用下面程式碼
SELECT RANK() OVER (ORDER BY COUNT(1) DESC) AS '排名',
keyword AS '關鍵字',COUNT(1) AS '次數'
FROM webkeyword
GROUP BY keyword
Rank() over-> 透過什麼排名。
rank函數用於返回結果集的分區內每行的排名, 行的排名是相關行之前的排名數加一。簡單來說rank函數就是對查詢出來的記錄進行排名。
可參考這篇
https://www.cnblogs.com/52xf/p/4209211.html
COUNT(1)
他類似count(*),只是效能上的差別,所以別把Select Count(1)裡的數字,當做是欄位第一個。
可參考這篇
https://dotblogs.com.tw/jeff-yeh/2011/01/12/20767
GROUP BY
意思就是說,欄位內的資料若有不只一筆名稱相同的資料的話,就會把它們作為群組
可參考這篇
https://ithelp.ithome.com.tw/articles/10218537