練習爬蟲抓取Pressplay所有的課程資料,最後將資料轉存至excel檔
但是最後課程資訊的迴圈說找不到檔案,請問問題是?
以下是我的code (抱歉,之前網址放錯了)
import requests
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
index = ["name","author","type","description","price","sold"]
ws.append(index)
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36",
"cookie":"PHPSESSID=tcsn9k3lq3b9qu9qssiou2nmlr; salt=17c563002ae65-0561a5018abc3c-b7a1b38-144000-17c563002af627; _gcl_au=1.1.1241047029.1633533560; __asc=39103bac17c563004f470c17189; __auc=39103bac17c563004f470c17189; _ga=GA1.2.186048344.1633533560; _gid=GA1.2.2061645999.1633533560; _gat_gtag_UA_73798928_1=1; cto_bundle=1NQF619wbDhuaDVDcmdqQ1o4OHU3UkllZU9TbU9IR1dTJTJCOFpxZzFTJTJCTXJlUUJ2ZWdad2xrMCUyQmJ6dCUyRkdoamU2UGJRUEclMkJrcnc2U3B3Z2FrZnMyeUluNEdSVUtqVWN6UFpCQnN4cURqYTZNQnRsVnQ1OXVXRlZyTW5QJTJCVGJ0JTJGbzdYRGo0; __zlcmid=16QkNvV5RtCBnju",
}
for page in range(66):
url = "https://www.pressplay.cc/project?page="
url = url + str(page)
print(url)
r = requests.get(url,headers=headers)
print(r)
courses = r.json()
for project in courses['data']:
list=[]
list.append(project["project_title"])
list.append(project["owner"]["nickname"])
list.append(project["type_name"])
list.append(project["project_short_desc"])
list.append(project["offers"]["min"])
list.append(project["purchase_num"])
ws.append(list)
wb.save("pressplay.xlsx")
已邀請的邦友 {{ invite_list.length }}/5
這個錯誤意思是你取回來的JSON沒有這個KEY
我請求你提供的網址是出現這個JSON
{"message":"Some parameters are missing."}
你可能要檢查你請求的網址是否正確
問題是「因為程式寫錯,所以沒有抓到資料」
先 print r 看看抓到什麼結果
我抓到的只有這個
{
"message" : "Some parameters are missing."
}
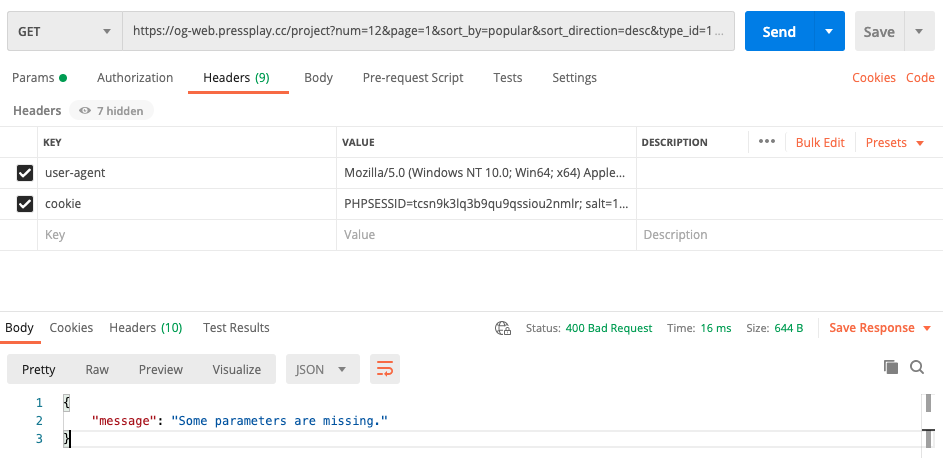
另外
for page in range(1,66):
url = "https://og-web.pressplay.cc/project?num=12&page=1&sort_by=popular&sort_direction=desc&type_id="
url = url + str(page)
這裡看是想要「抓第1頁到第66頁的資料」
可是裡面的 page=1 固定,變成「抓 66 次第1頁的資料」
而 url = url + str(page)
只是變成最後的 type_id=1 到 type_id=66
我是不知道這有沒有什麼用意
