問題是這樣的
最近需要採集中國政府的標案數據
主要需要爬取:
不過麻煩來了,由於招標訊息是來自各省份與各單位,因此公告格式都不同 (看起來是不同省份單位,都有自己的格式),除格式以外,裡面的得標金額單位、分錄也不同,即有些會寫總額,有些會依細則項目分開寫。
大概如下圖:
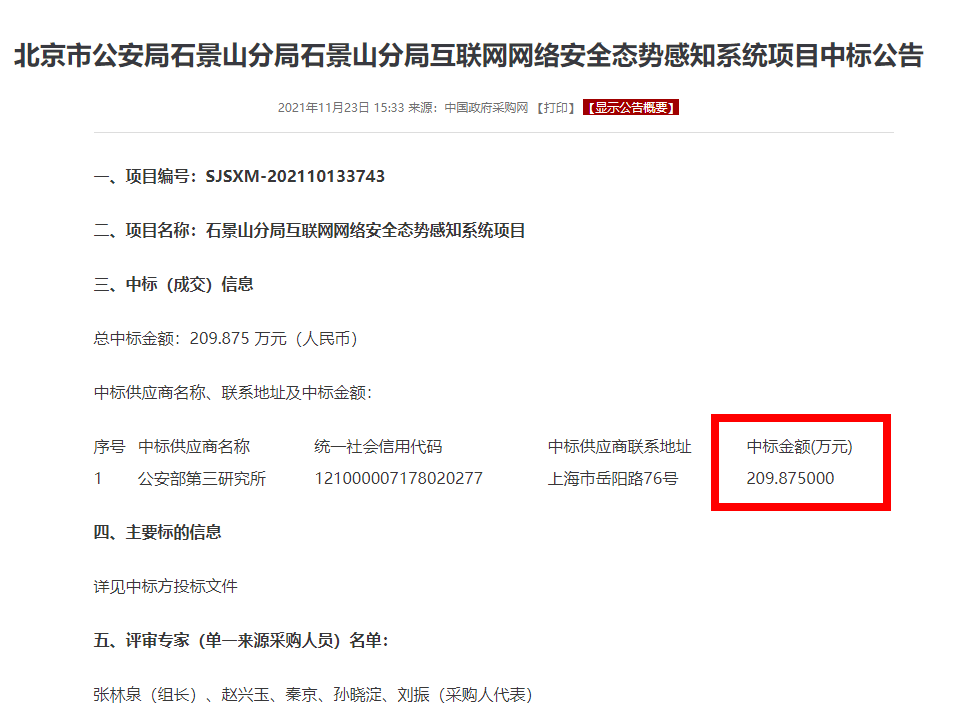
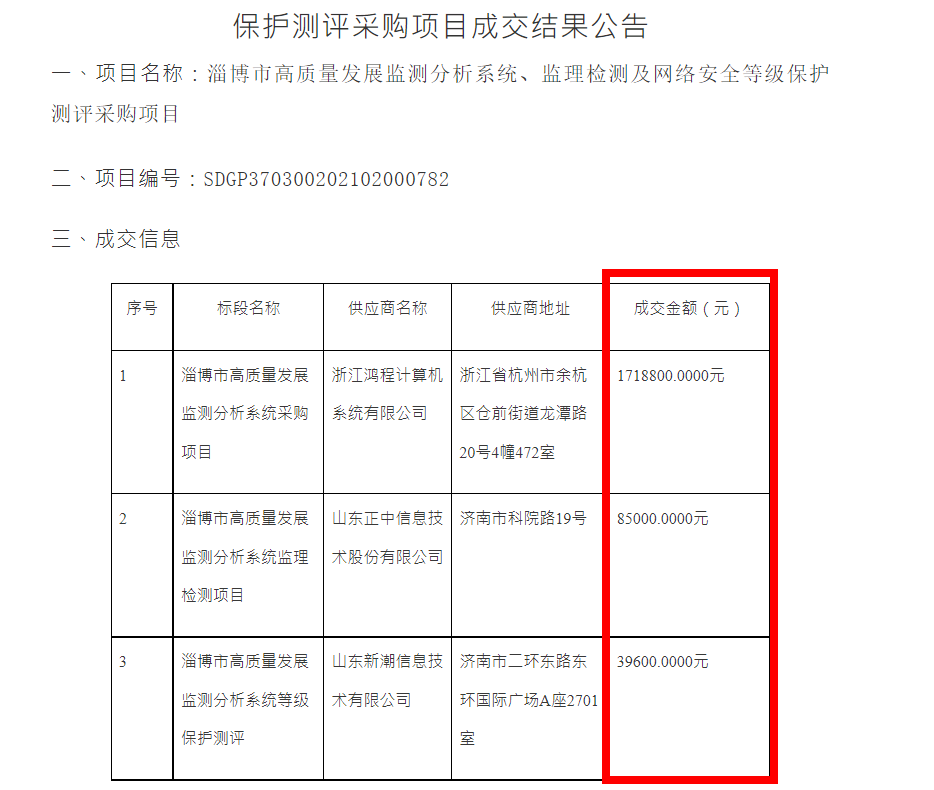
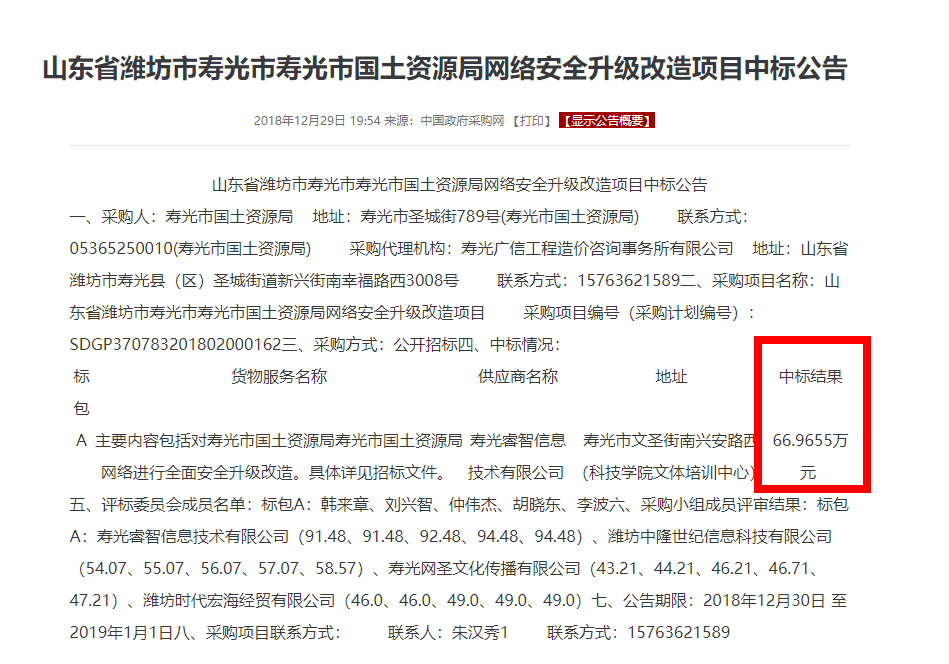


想請問各位熟悉文本分析、資料探勘的大大們,這樣的情境下應該如何解會比較好?
謝謝各位
已邀請的邦友 {{ invite_list.length }}/5
一般來說,我會使用 PG 的 text datatype,存放 raw data.
因為 text 可以存放 1G,而且不用宣告size.
raw data 都抓好存好後,後面再逐次過濾擷取.
PG 可以使用Pl/Python , 把處理方式函數化.
請問 PG 是指 PostgreSQL?
不過自己公司主要是使用 MS SQL
不知道這樣是否造成無差異?
SQL Server , 可以使用 nvarchar(max)
https://docs.microsoft.com/en-us/sql/t-sql/data-types/nchar-and-nvarchar-transact-sql?redirectedfrom=MSDN&view=sql-server-ver15
因為像這類資料,往往會有很多情況,所以先存起來,再慢慢處理.
爬蟲部分就先爬,存起來.
