這是我自己寫的正則
i=""
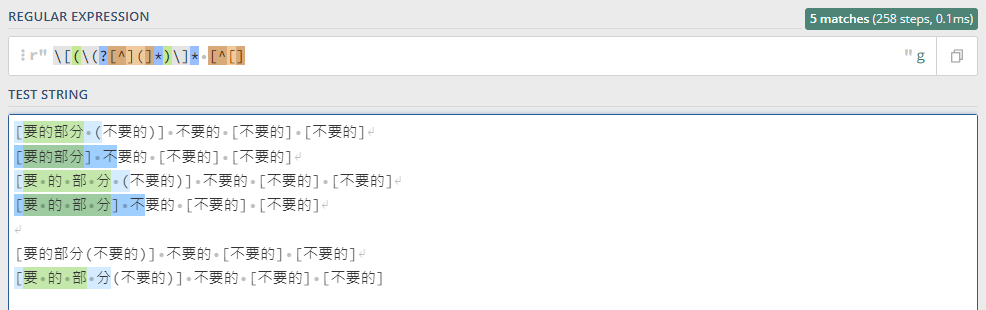
it = re.search('\[(\(?[^](]*)\]* [^[]',i)
print(it.group(1),"\n")
目前確認可以匹配
[要的部分 (不要的)] 不要的 [不要的] [不要的]
[要的部分] 不要的 [不要的] [不要的]
[要 的 部 分 (不要的)] 不要的 [不要的] [不要的]
[要 的 部 分] 不要的 [不要的] [不要的]
但是偶爾會出現這種無法匹配的
或缺少的
有方法改良嗎?
[要的部分(不要的)] 不要的 [不要的] [不要的]
[要 的 部 分(不要的)] 不要的 [不要的] [不要的]
已邀請的邦友 {{ invite_list.length }}/5
\[(.+?) ?(?:\(.+?\))?\](?= [^[])
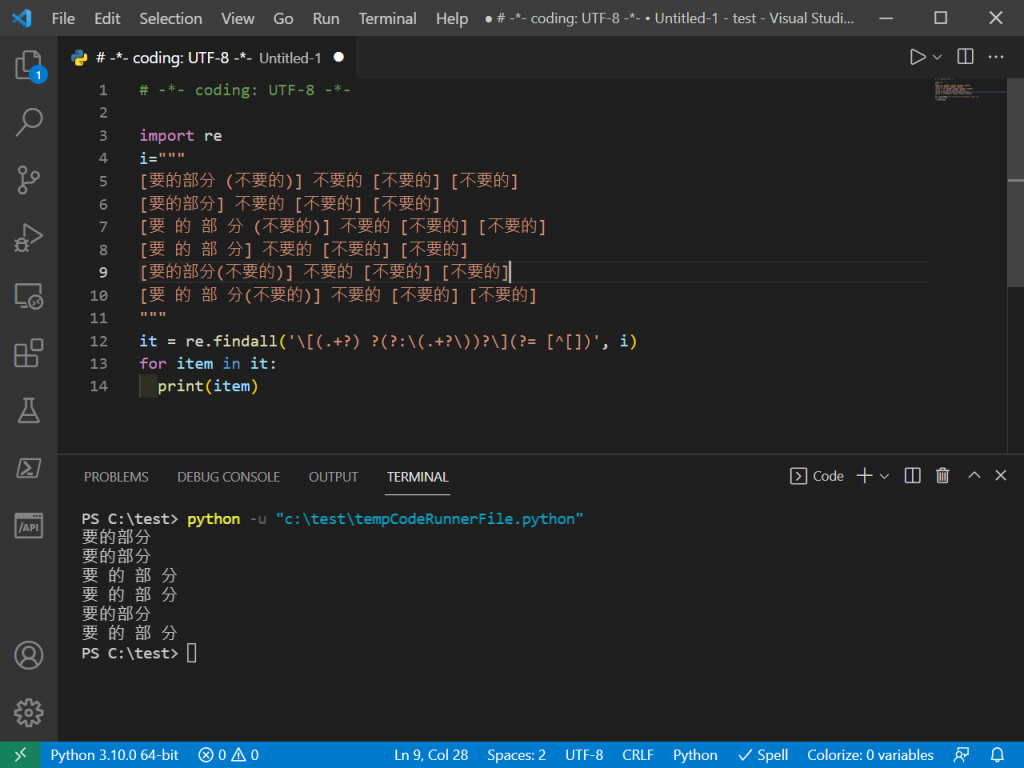
範例資料的 pattern 可能要再完整一點
否則就用這樣就可以了



 iThome鐵人賽
iThome鐵人賽