各位前輩晚上好,小弟在嘗試爬蟲取網頁資料的時候,有成功取到資料,
但唯獨少了< section > 的部分。
目標資料: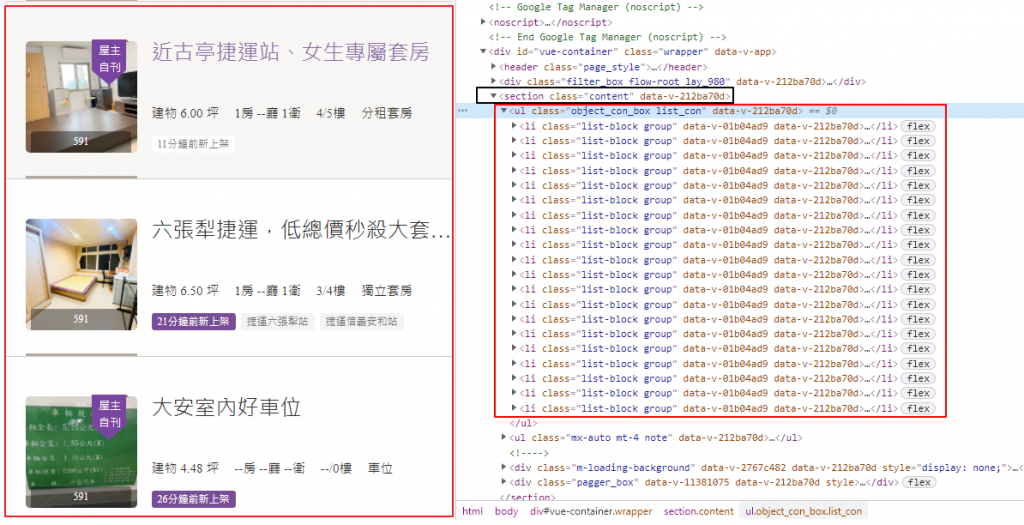
程式碼:
import requests
from bs4 import BeautifulSoup
url = 'https://rent.houseprice.tw/'
res = requests.get(url, headers=headers)
html_doc = res.text
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup)
結果: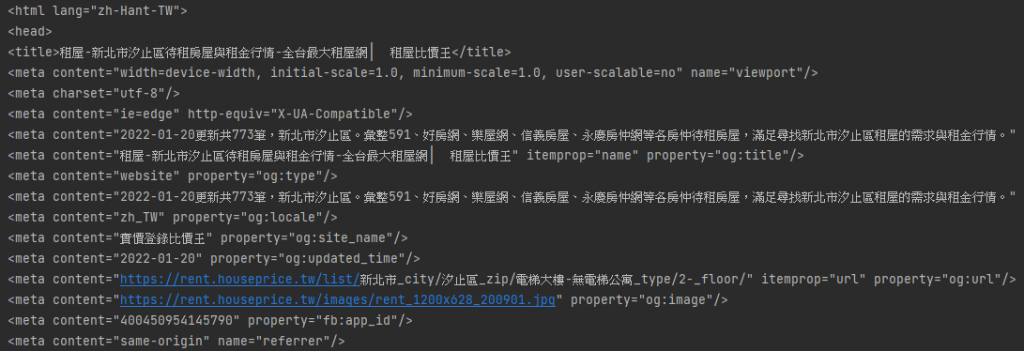
已邀請的邦友 {{ invite_list.length }}/5
等個幾秒,再送出request即可。
import requests
from bs4 import BeautifulSoup
s = requests.Session()
url = 'https://rent.houseprice.tw/'
headers={'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"}
res = s.get(url, headers=headers)
html_doc = res.text
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup)
import time
time.sleep(3)
url = 'https://rent.houseprice.tw/ws/list/'
res = s.get(url, headers=headers)
html_doc = res.text
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup)
