」Excepteur sint」
「Hello World「
」foobar「
「Hello」Lorem ipsum dolor sit amet「World」
期望
「Excepteur sint」
「Hello World」
「foobar」
「Hello」Lorem ipsum dolor sit amet「World」
感謝 @Han,@海綿寶寶 的回答。(因為我等級不夠,無法在底下回應。)
@Han再透過索引檢查第一個是不是 「 就可以決定是否替換
最後一個也一樣道理,提供給你參考
Hmm,不一定要只用 regex 來替換嘛
import regex
text = "」Excepteur sint」, 「Hello」Lorem ipsum dolor sit amet「World」"
for match in regex.finditer("[「」].*?[「」]", text):
quotes_text = match.group()
if not regex.search("「.*?」", quotes_text):
quotes_text = f"「{quotes_text[1:-1]}」"
text = text.replace(text[match.start():match.end()], quotes_text)
print(text)
# result -> 「Excepteur sint」, 「Hello」Lorem ipsum dolor sit amet「World」
# 但是如果 text = "「foo「Hello」bar」"
# result -> 「foo」Hello「bar」
感謝 @海綿寶寶 寫的 pattern
新的期望
input: 「foo「Hello」bar」
output: 「foo「Hello」bar」
已邀請的邦友 {{ invite_list.length }}/5
我會先透過 regex 鎖定 被引號包起來的字串
import re
re.match(r'[「」].*?[「」]', '」Excepteur sint」')
再透過索引檢查第一個是不是 「 就可以決定是否替換
最後一個也一樣道理,提供給你參考
可以是可以
不過我寫不出一個適用於四種 pattern 的 RE
只寫出三種分開的 RE
而且第3個 RE 會誤判第四種 pattern
等待真正高手來給正解
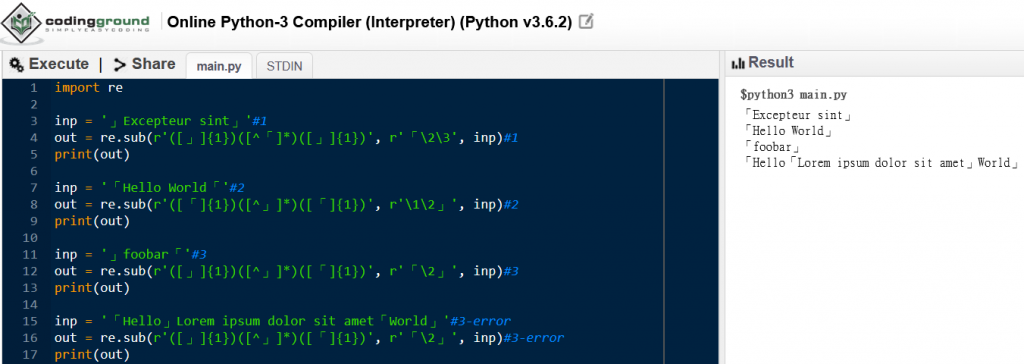
import re
inp = '」Excepteur sint」'#1
out = re.sub(r'([」]{1})([^「]*)([」]{1})', r'「\2\3', inp)#1
print(out)
inp = '「Hello World「'#2
out = re.sub(r'([「]{1})([^」]*)([「]{1})', r'\1\2」', inp)#2
print(out)
inp = '」foobar「'#3
out = re.sub(r'([」]{1})([^」]*)([「]{1})', r'「\2」', inp)#3
print(out)
inp = '「Hello」Lorem ipsum dolor sit amet「World」'#3-error
out = re.sub(r'([」]{1})([^」]*)([「]{1})', r'「\2」', inp)#3-error
print(out)
import re
import unittest
class ContextCorrector(object):
left_symbol: str = '「'
right_symbol: str = '」'
def parse(self, txt: str) -> str:
txt_matches = re.findall('[「」].+?[「」]', txt)
for txt_match in txt_matches:
start_symbol = txt_match[0]
end_symbol = txt_match[1]
if start_symbol != self.left_symbol or end_symbol != self.right_symbol:
txt = re.sub(txt_match, f'{self.left_symbol}{txt_match[1:-1]}{self.right_symbol}', txt)
return txt
class ContextCorrectorTest(unittest.TestCase):
def setUp(self) -> None:
self.corrector = ContextCorrector()
def test_first_case(self) -> None:
self.assertEqual('「Excepteur sint」', self.corrector.parse('」Excepteur sint」'))
def test_second_case(self) -> None:
self.assertEqual('「Hello World」', self.corrector.parse('「Hello World「'))
def test_third_case(self) -> None:
self.assertEqual('「foobar」', self.corrector.parse('」foobar「'))
def test_fourth_case(self) -> None:
self.assertEqual('「Hello」Lorem ipsum dolor sit amet「World」',
self.corrector.parse('「Hello」Lorem ipsum dolor sit amet「World」'))
def test_fifth_case(self) -> None:
self.assertEqual('「foo」Hello「bar」',
self.corrector.parse('「foo「Hello」bar」'))
if __name__ == '__main__':
unittest.main()
