分享至
板上各位前輩大家好,想請教一個程式錯誤問題!
我透過爬蟲想要抓某賣場的商品資料內容,首先導入資料
再來把資料的原本的英文名稱改為中文方便辨識
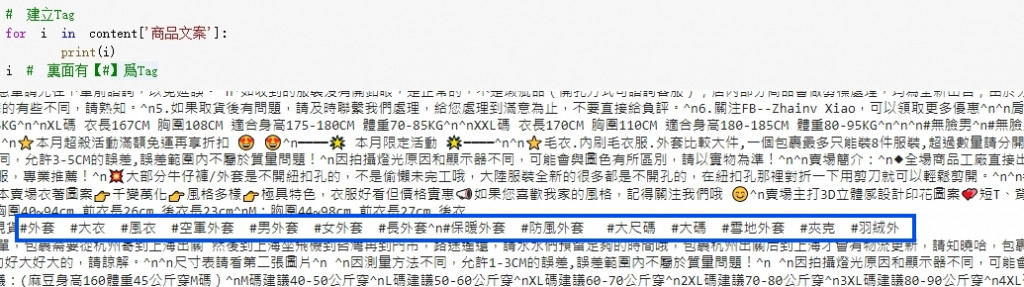
**重點,我想將文章內的 #tag 的標示都抓出來,也確定內容有出現 #xxx 的標籤**
然後就會出錯~
懇請板上的大大,若有任何解決方案可以協助我,感恩!
已邀請的邦友 {{ invite_list.length }}/5
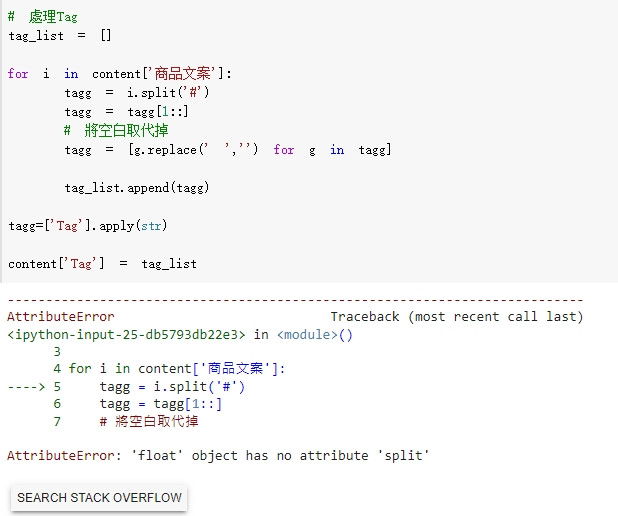
這問題應該是 content['商品文案']有不是string的內容,所以你i.split('#'),假設剛好遇到type float的這個內容就會噴錯失敗。
解法很簡單,加個try...catch...就行了
for i in content['商品文案']: try: tagg = i.split('#') tagg = tagg[1::] ... ... catch: continue
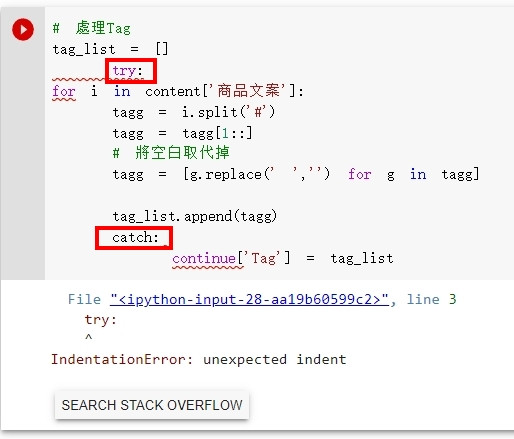
的確如您所說是tagg = i.split('#')的問題!不過嘗試用try還是會報錯,如圖~若是您方便解惑再麻煩您~
try是在for迴圈裡面
IT邦幫忙




 iThome鐵人賽
iThome鐵人賽