import re
pattern = r"<!.+>"
test_string = """
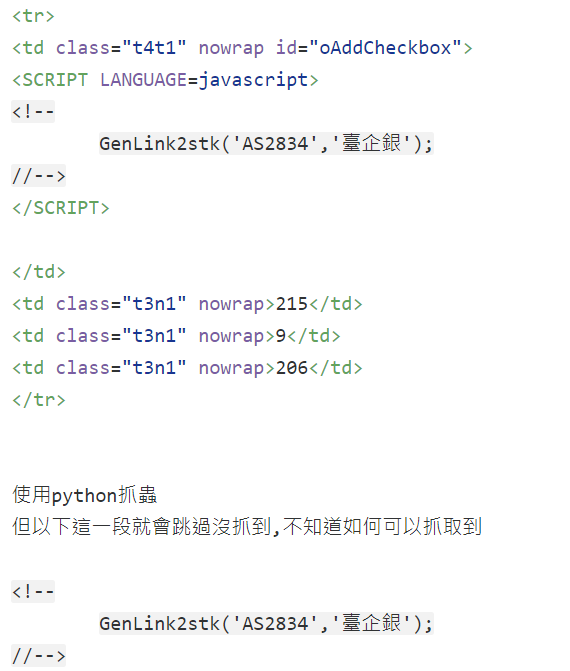
<td class="t4t1" nowrap id="oAddCheckbox">
<SCRIPT LANGUAGE=javascript>
<!--GenLink2stk('AS2834','臺企銀');1/ -->
</SCRIPT>
</td>
<td class="t3n1" nowrap>215</td>
<td class="t3n1" nowrap>9</td>
<td class="t3n1" nowrap>206</td>
</tr>
"""
print(re.search(pattern, test_string).group())
換成實際的網頁之後就會出現錯誤
用你的範例,可以抓出來註解裡面的內容
但我如果替換成實際網址
https://fubon-ebrokerdj.fbs.com.tw/z/zg/zgb/zgb0.djhtm?a=7000&b=0037003000300056&c=E&d=1
他就不會抓出來
註:IT邦幫忙新手&PYTHON新手,說聲抱歉&謝謝你~~
推測你遇到的問題:
轉成字串後的資料: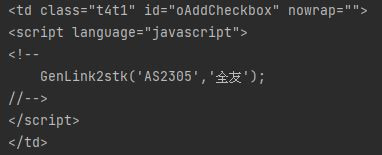
附上成功程式:
import re
import requests
from bs4 import BeautifulSoup
url = "https://fubon-ebrokerdj.fbs.com.tw/z/zg/zgb/zgb0.djhtm?a=7000&b=0037003000300056&c=E&d=1"
res = requests.get(url)
soup = BeautifulSoup(res.text, "lxml")
for item in soup.find_all("td", class_="t4t1"):
pattern = r"GenLink2stk.+"
result = re.search(pattern, str(item))
if result:
print(result.group())
成功程式執行結果: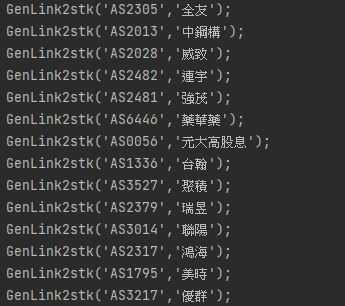
補充:if result 是為了避免 re 抓出來為 None,對 None 做 group() 會產生錯誤
感謝您的協助,,謝謝