各位大大第一次發問如有不好之處可以指出來
各位大大我在做最簡單的爬蟲問題的時候遇到了一些狀況,上網找了一下發現很少人跟我的狀況一樣,找不到答案所以發文請各位大大幫忙
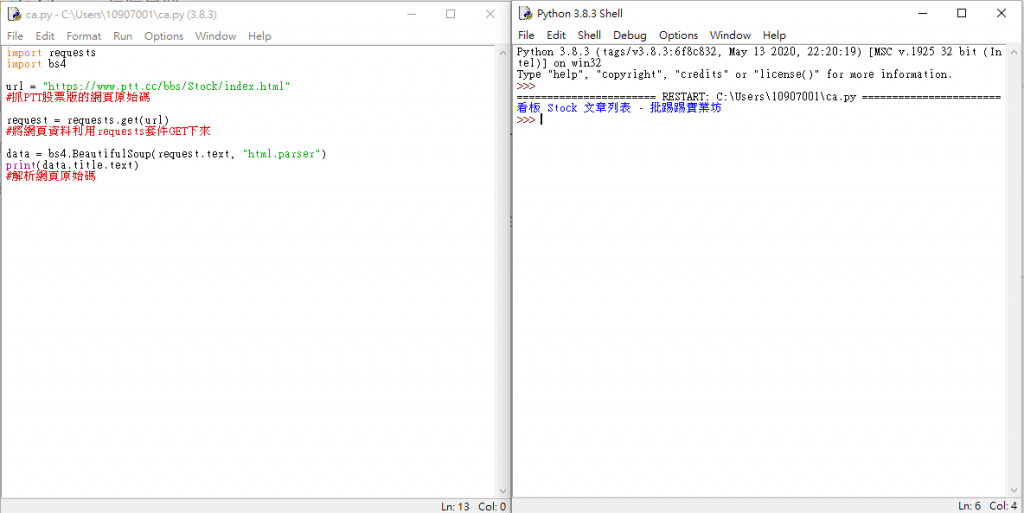
import requests
import bs4
url = "https://www.ptt.cc/bbs/Stock/index.html"
#抓PTT股票版的網頁原始碼
request = requests.get(url)
#將網頁資料利用requests套件GET下來
data = bs4.BeautifulSoup(request.text, "html.parser")
print(data.title.text)
#解析網頁原始碼
看網路上的教學正常來說應該是只有這串文字<看板Stock文章列表>跑出來連標籤都不會有
但是我跑出來後是以下的狀況網頁全部被印出來了而且排版也跑掉了(不知道為甚麼?)


請各位大大幫幫忙!!
回一樓大大 我跟你打的是一樣的但是跑出來是整個頁面 正常來說應該是跑出像大大那樣是只有標頭才對 但是我的像是這樣
回一樓大大
大大好像沒有跑錯檔案
但是我重開電腦就好了(我也不知道為甚麼) 本來重開vsc也沒用
但還是感謝大大
回一樓大大 我有確實的把python的套件都裝好,大大說的路徑不同 我先研究看看為什麼會這樣
謝謝大大
已邀請的邦友 {{ invite_list.length }}/5
不太清楚你的問題點在哪
整個程式碼照貼執行是沒問題的
你如果是只寫print(data)的話是會把整個頁面上的html全部印出來唷
補充回覆:
想問一下你是不是在執行的時候執行到錯誤的檔案
我看你檔案好像放在E槽裡面
但你在執行python的時候是執行C槽的檔案
