經大神指點後,練習組合網址,但嘗試好幾天的都無法解決,爬文也找不到相關的,字串印出會越來越少,再麻煩各位抽空指教
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.support.ui import Select
import re
path = "D:\python pratice/chromedriver.exe"
driver = webdriver.Chrome(path)
driver.get("https://www.comicabc.com/html/103.html")
soup = BeautifulSoup(driver.page_source,'lxml')
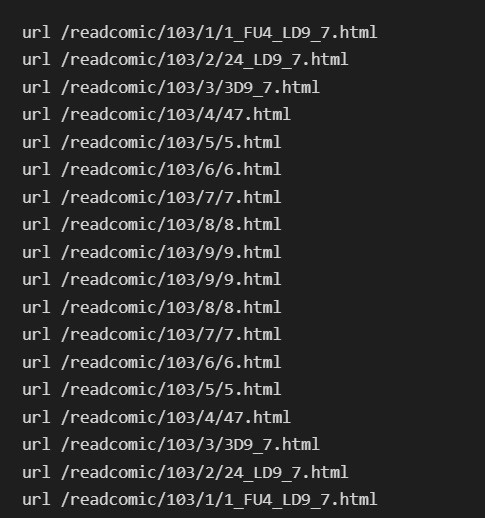
rc="__R_FU4_LD9_7_3_Q_atq24_0rG73tIH1661__2K_z88vR_14Lu109nkcW6o1609JAHi9o_rD9A0_55_19NN_40RO2n32365_97K"
for x in soup.find_all('a'):
try:
if re.match('cview',x['onclick']):
k= x['onclick']
ranurl='/readcomic/'
mid=k.split('-')[0][7:10]
cch=k.split('-')[1][0:6]
chn=str(cch.replace('.html',''))
ru=ranurl
url=ru+mid+'/'+chn+'/'+chn+(rc+rc)[((3*int(chn))%(len(rc))):13] +'.html'
# print(len(rc))
# print(cch)
# print(chn)
# print(k)
# print(x['onclick'])
# print("url",url)
except:pass
已邀請的邦友 {{ invite_list.length }}/5
樓主要不要先說明,你原本想做到什麼事情?
https://ithelp.ithome.com.tw/questions/10210641
提取每一卷的網址,想用看看大神建議的方式試試看

 iThome鐵人賽
iThome鐵人賽