如題目表示...
我使用pandas 整理表格,想找出max() 最大値,我使用了df.groupby('建物型態').max()['單價元平方公尺'] 感覺出來結果有點奇怪,於是我用下列程式去看:
bond=pd.read_csv('/content/drive/MyDrive/test/datahistory/c.csv',index_col='建物型態')
a=bond.loc['公寓']
aMax=a.sort_values(['單價元平方公尺'],ascending=False)
aMax
結果資料排序在萬分位 和十萬分位的地方出現問題: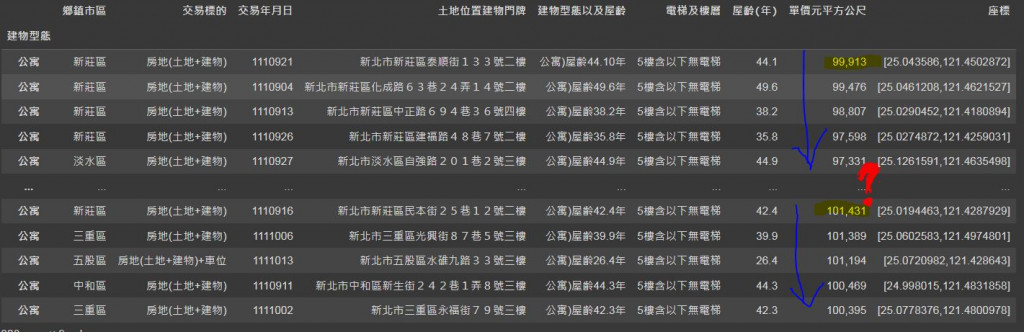
新增程式如下(回覆討論):
bond=pd.read_csv('/content/drive/MyDrive/test/datahistory/c.csv',index_col='建物型態')
bond1=bond['單價元平方公尺'].str.replace(',','').astype('float')
a=bond1.loc['公寓']
a.sort_values()
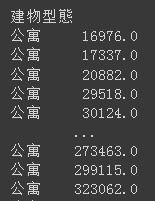
結果:
已邀請的邦友 {{ invite_list.length }}/5
試試看
加大欄寬(例:pd.set_option('display.width', None))
有點像是筆數過多的「略」的符號
呃..我資料欄位是string沒錯... 謝謝兩位前輩回覆!!我做了一些修改,但結果仍不如預期顯示,可能資料格式觀念不是很熟悉,想請板上前輩們指出盲點:
df.單價元平方公尺 = pd.to_numeric(df.單價元平方公尺, errors='coerce')
df[df["建物型態"] == "公寓"]["單價元平方公尺"].max()
訊息結果:
Nan
參考這篇
加個 replace
把,換掉
pd.to_numeric(df.str.replace(',',''), errors='coerce')
結果成功執行! 感謝您的耐心回覆~
