請教一個問題 AWS Load Balance 的問題
這樣的架構 如果公有子網1的web (簡稱A伺服器) 與 公有子網2的web (簡稱B伺服器)
同時對同一筆資料 進行了修改
(只有一台RDS)
有沒有可能發生以下情況
A伺服器 先得到修改 Row1:name=2 的request
B伺服器 然後得到修改 Row1:name=3 的request
但是A伺服器跑 修改name=2 的functionA 程式比較多 跑得比較慢
B伺服器跑 修改name=3 的functionB 程式比較少 跑得比較快
最後導致結果先執行name=3 再執行 name=2
會有這種情況嗎?
有的話該如何解決?
或者有什麼網路架構可以避免這種情況
可以的話可以幫我畫一下就更好了(包括 EC2 RDS S3 EBS) 謝謝大神
已邀請的邦友 {{ invite_list.length }}/5
多工使用當然會遇到這個現象, 這就是 DB 的 Race Condition.
通常是負責設計資料庫的 DBA (資料庫管理師) 要出面解決.
他跟有沒有:負載平衡, 有沒有上雲, 有幾台主機...等等都沒有關係,
並不是 Infra 用了甚麼神奇的網路架構, 就會自動解決掉這個問題.
就只是多人存取資料庫的時候, 需要用到的交易設計規劃與處理技巧,
所以才說是 DBA 要出面來解決, 因為這是 DBA 職務的日常工作之一.
(大學的資訊相關科系, 應該都會在學程中講授這個 DB 問題與解法)
其成因與解決方法可先參考別人的筆記:
https://hackmd.io/@Burgess/SkDnHKMNr
詳細整理:
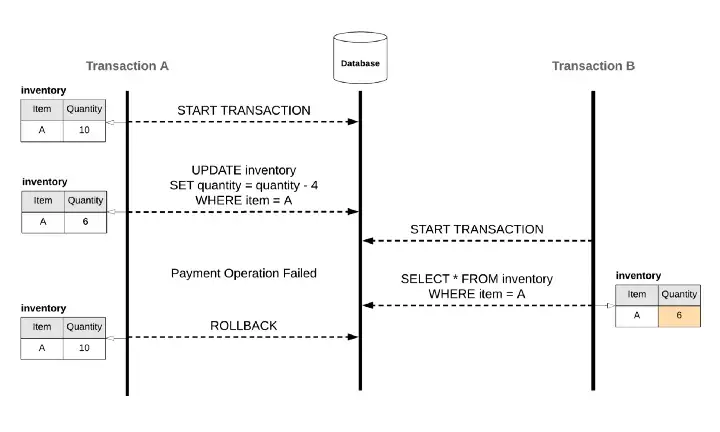
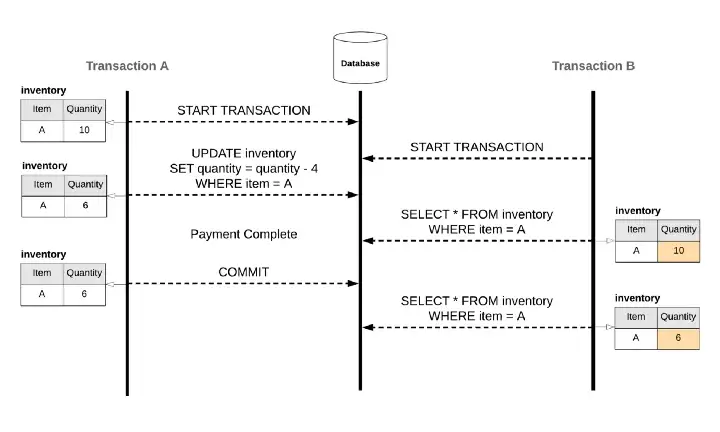
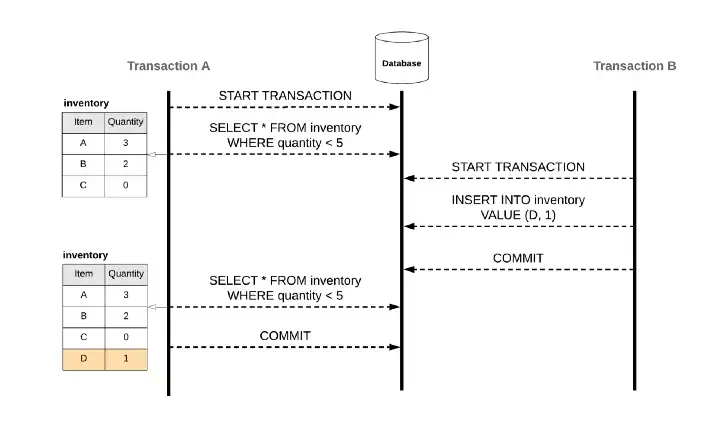
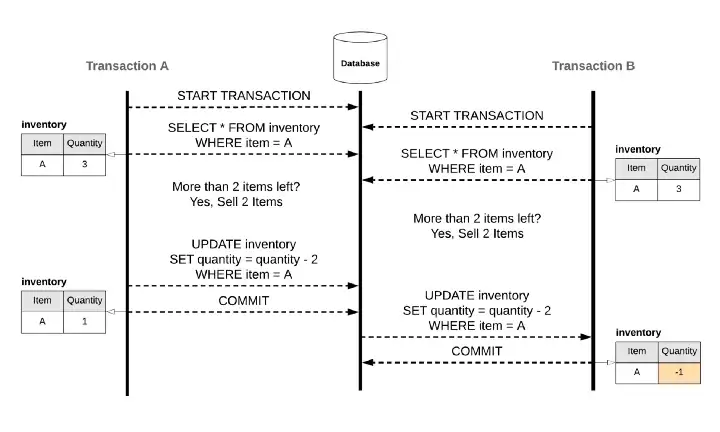
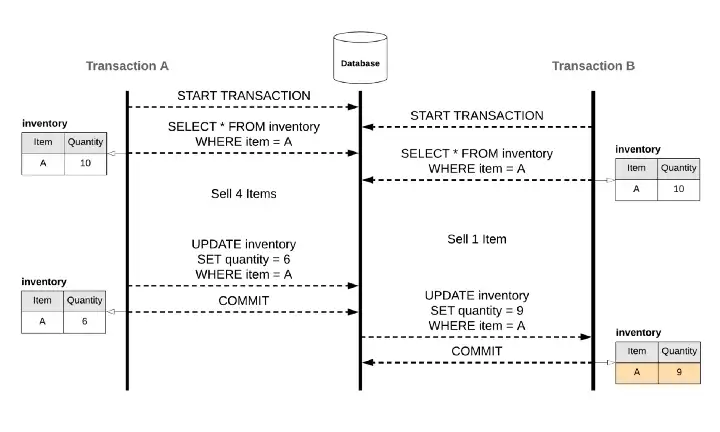
要解決以上的 Race Condition, 會因為 DBMS (資料庫管理系統) 的 Isolation Level 而有不同的解法, 萬一你用的 DB Engine 沒辦法解掉你的應用情境, 就要自己在程式裡面寫排隊機制去排解:
Isolation Levels 有四種等級,各家資料庫皆會宣稱支援到何種等級? 一般需要 transaction 情境至少會要求到 Repeatable Read 的等級。
DBA 在規劃選擇 DB System 時, 要考量其支援的 Isolation Levels 能否解決應用情境? 否則就要自行用程式處理 race condition 問題。
1.Read Uncommitted:
代表 transaction 可以讀到別的 transaction 尚未 commit 的資料,在這個等級中 race condition 所有問題都沒有被解決。
2.Read Committed:
代表 transaction 只能讀到別的 transaction 已經 commit 的資料,沒有 commit 的話就不會讀到,在這個等級解決了 Dirty Read 的問題,但是其他四個現象還是有可能發生。
3.Repeatable Read:
代表每次 transaction 要讀取特定欄位的資料時,只要 query 條件相同,讀取到的資料內容就會相同。在這個等級解決了 Non-repeatable reads 的問題。依照實作的方法不同,有的 Repeatable Read Isolation 還可以避免 Lost Update 或 Phantom 現象。
4.Serializable:
代表在多個 transaction 同時執行時,只要 transaction 的順序相同時,得到的結果一定相同。比如說 Transaction A 先執行了,接下來再執行 Transaction B,在同樣的條件下,每次執行都會得到一樣的結果。在這個等級下連同 Phantom reads 也會一併被解決。
這四種 Isolation 對應以上五種 Race Condition 的解決程度 (綠底代表安全解決):
註(1): 其他三個 Isolation Level 我們都可以很清楚的知道,它們分別避免哪些 Race Conditions,唯獨 Repeatable Read Isolation 的行為,則依照每個資料庫廠商的實作方式不同, 而有各別差異。
註(2): Serializable 通常被認為是最嚴格的 Isolation Level,可以避免上述全部五種現象,但是因為必須犧牲一些 Concurrency,導致效能較差。
以 MYSQL 的 InnoDB Engine 為例
(MySQL 在 Create Table 時可以選擇: MyISAM 或 InnoDB...等不同的引擎):
InnoDB 預設 Isolation Level 為 Repeatable Read (MySQL InnoDB 只能避免 Phantom Read,UPDATE 和 DELETE 等 DML 的寫入的操作則無法避免 Phantom 現象, 也無法避免 Lost Update)
但若換成 PostgreSQL 的話:
PostgreSQL 預設是 Read Committed 的 isolation level (PostgreSQL 可以完全避免 Phantom 和 Lost Update)
而 AWS 的 DynamoDB 則是:
遇 race condition 情形會直接拋回 TransactionConflictException 的例外錯誤, 可能要視情況, 自行在應用程式內實作出 auto-retries 機制
這裡有一個用 PostgreSQL 實作的 Race Condition 展示:
https://blog.kennycoder.io/2020/03/06/RDBMS-%E4%B8%8D%E5%90%8C%E7%9A%84Isolation-Level-Race-Condition%E7%A4%BA%E7%AF%84/
這是 RoR 寫的概念驗證:
https://riverye.medium.com/day22-ruby-on-rails-%E4%B8%AD%E7%9A%84-race-condition-645a838a0174
這是 PHP Laravel 的展示:
https://blog.scottchayaa.com/post/2019/01/09/how-to-handle-the-high-concurrency-on-laravel/
後記: 因樓主只說用了 AWS RDS, 卻沒講是用了 RDS 裡面的哪一種 DB Engine, 所以請自行查閱所選的 DB Engine, 才能得知你目前所使用的 Isolation 種類.
