我參考網路上的教學寫了一個無限滾動式ptt網頁板爬蟲,並且會檢查上一次滾動最尾端的並從那開始繼續爬,不過卻遇到了有機率發生重複寫入同一則文章
有時會突然從某一則開始反覆寫入直到程式滾動次數結束,如圖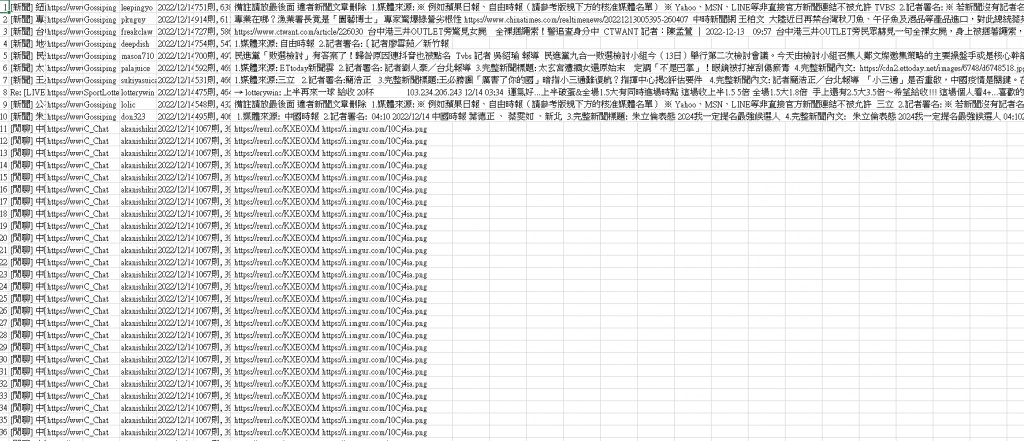
有時會從某則開始連續寫入同則後再繼續跑,然後又從之後的某則再度發生同樣的事情,如圖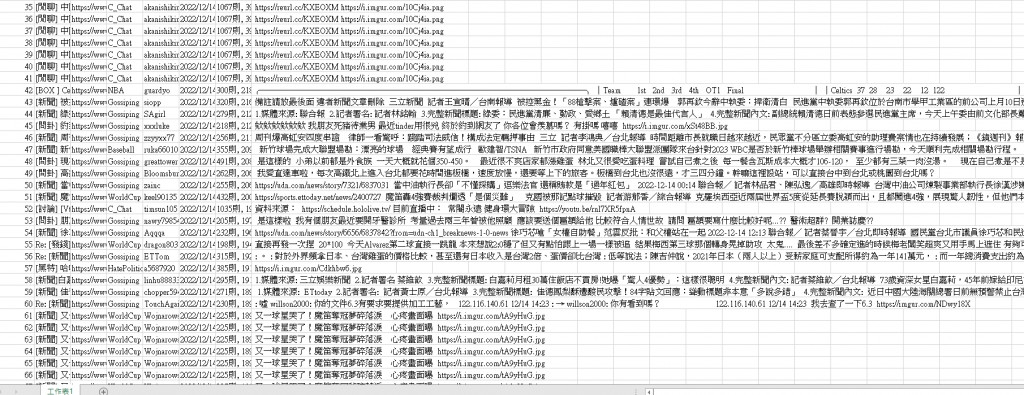
請問各位大大這是什麼原因
以下是我的程式碼:
import urllib.request as req
import requests
import selenium
import schedule
import time
import json
from time import sleep
import json
import openpyxl
import random
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support import expected_conditions as EC
import bs4
pttWeb = openpyxl.load_workbook('pttweb.xlsx')
ws = pttWeb.active
i = 1
scroll_time = int(input("scroll_Times"))
options = Options()
options.chrome_executable_path = "C:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(options = options)
driver = webdriver.Chrome()
sleep(3)
driver.get('https://www.pttweb.cc/hot/all/today')
sleep(5)
prev_ele = None
for now_time in range(1, scroll_time+1):
sleep(2)
eles = driver.find_elements(by=By.CLASS_NAME,value='e7-right.ml-2')
# 若串列中存在上一次的最後一個元素,則擷取上一次的最後一個元素到當前最後一個元素進行爬取
try:
# print(eles)
# print(prev_ele)
eles = eles[eles.index(prev_ele):]
except:
pass
for ele in eles:
try:
titleInfo = ele.find_element(by=By.CLASS_NAME, value = "e7-article-default")
title = titleInfo.text
href = titleInfo.get_attribute('href')
ws.cell(i,1,i)
ws.cell(i,2,title)
ws.cell(i,3,href)
sleep(3)
inner =req.Request(href, headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"
})
with req.urlopen(inner) as innerRespomse:
articleData = innerRespomse.read().decode("utf-8")
articleRoot = bs4.BeautifulSoup(articleData, "html.parser")
main_content = articleRoot.find("div", itemprop="articleBody")
boardInfo= articleRoot.find("span", class_="e7-board-name-standalone")
authorInfo = articleRoot.find("span", itemprop="name")
timeInfo = articleRoot.find("time", itemprop="datePublished")
countInfo = articleRoot.find_all("span", class_="e7-head-content")
board = boardInfo.text
author = authorInfo.text
Time = timeInfo.text
count = countInfo[4].text
allContent = main_content.text
pre_text = allContent.split('--')[0]
ws.cell(i,4,board)
ws.cell(i,5,author)
ws.cell(i,6,Time)
ws.cell(i,7,count)
ws.cell(i,8,pre_text)
pttWeb.save('pttweb.xlsx')
sleep(random.uniform(5,20))
i = i+1
except:
pass
prev_ele = eles[-1]
print(f"now scroll {now_time}/{scroll_time}")
js = "window.scrollTo(0, document.body.scrollHeight);"
driver.execute_script(js)
sleep(5)
driver.quit()
已邀請的邦友 {{ invite_list.length }}/5
driver = webdriver.Chrome(options = options)
driver = webdriver.Chrome()
for now_time in range(1, scroll_time+1): loop 內的 eles = eles[eles.index(prev_ele):] 與 prev_ele = eles[-1],會形成「上次 list 的最後一個成為下次 list 的第一個。」。以上,後續程式碼我就沒看下去了,畢竟你要的是「重複寫入同一則文章」的原因。
另,發問的 Markdown 語法,程式碼區塊部分,前三個連續倒引號(backquote)後面可跟著語言名,以利系統辨識。
(不然有時 ithelp 這裡的系統會辨識成其他語言;例如你的程式碼就被識別為 vim 的語法。)
例如:
```python
print('hello, world')
(如不確認系統有否正確辨識,可於[預覽]後,用瀏覽器 DevTool 看其樣式類別)
請問一下動態網頁內容沒更新通常是因為什麼原因,因為像上圖第10則就不再更新,但網頁明顯就還沒到底,是我給他的sleep不夠久導致來不及加載嗎?
動態網頁內容更新情形要看伺服器的回應(包含網路狀況等)、 client (亦或 Sv)端的程式設計等。例如:有些網頁放很久,移動頁面到底部時以取得新的內容,會看到部分重複的項目,這是在 client (亦或 Sv)端的程式設計不嚴謹(或為降載等考量)上偶有的現象 (原因細節我就不說了)。
而在爬網頁上,還要追加考量 webdriver 使用引擎的狀況(例如,渲染(rendering)結果)等各樣情形。
例如,在 rendering 上,這裡 能看到一些討論。
(我對 Selenium 很陌生,我若是簡單抓資料時幾乎在用 Playwright。各有優缺~)
所以你說「是我給他的sleep不夠久導致來不及加載嗎?」,我很難確定;畢竟能出問題的因素太多,我是寧願確認 render 的現況內容來控制程式流程(還是會搭配 sleep 之類的,不然出意外會被 Sv 端開擋……)。
在除錯上,除了設計除錯方法外,你可用 non-headless 模式,或 save_screenshot 來觀察瀏覽器的狀況。
另,你可以試著在記錄檔加上 Loop count 等除錯用資訊以推敲狀況(例如,那一堆重複的項目是從哪邊出現的),不然你用 except: pass 無視錯誤也不 輸出/顯示 錯誤資訊,很難意識到異常並找出問題。(不是不能用,而是要確定沒問題或風險可接受才能用)

 iThome鐵人賽
iThome鐵人賽