請教各位前輩
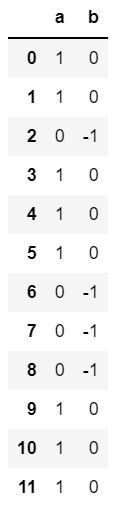
資料長相如下
a = pd.Series([1,1,0,1,1,1,0,0,0,1,1,1])
b = pd.Series([0,0,-1,0,0,0,-1,-1,-1,0,0,0])
c = pd.DataFrame({'a':a, 'b':b})
c
若最終結果只保留a與b欄位第一筆不同狀態的值,如下圖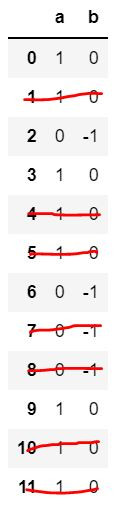
該如何撰寫邏輯
感謝各位大神
※嘗試使用for loop但還不太熟悉TT
已邀請的邦友 {{ invite_list.length }}/5
如果你有上億筆資料,建議用built-in function來操作,效能上可能會有數百倍的提升。
import pandas as pd
a = pd.Series([1,1,0,1,1,1,0,0,0,1,1,1])
b = pd.Series([0,0,-1,0,0,0,-1,-1,-1,0,0,0])
df = pd.DataFrame({'a':a, 'b':b})
# 先合併a與b的data用來做比較
df['ab'] = df['a'].astype(str) + df['b'].astype(str)
# 檢查下一筆與當筆是否相同,相同為0不同為1
df['check'] = df['ab'].ne(df['ab'].shift().bfill()).astype(int)
# 第一筆沒有前一筆,所以會為0,要改為1
df.loc[df.index==0, 'check'] = 1
# 篩選出結果
result = df[df['check']==1]
這個解法太神了,也不用變換df的型式,感謝 Peter
lsta = [1,1,0,1,1,1,0,0,0,1,1,1]
lstb = [0,0,-1,0,0,0,-1,-1,-1,0,0,0]
lstc = list(zip(lsta, lstb))
lastval = lstc[0]
newlst = [lastval]
for v in lstc[1:]:
if v != lastval:
newlst.append(v)
lastval = v
#
print(newlst)
result:
[(1, 0), (0, -1), (1, 0), (0, -1), (1, 0)]
剛才看完您的敘述,我的理解是按照找出第一筆a, b不同狀態的值,如果有誤解,還請提出建議,謝謝~
※ 更新,後續有看懂您的問題了,雖然已經有1F的解答了,還是提供給您參考~ 也順便當作讓自己練習的機會,謝謝~
import pandas as pd
def main():
a = pd.Series([1,1,0,1,1,1,0,0,0,1,1,1])
b = pd.Series([0,0,-1,0,0,0,-1,-1,-1,0,0,0])
c = pd.DataFrame({'a':a, 'b':b})
lst = []
length = (len(c) - 1)
i = 0
while i <= length:
# for迴圈尋找下一個相異值(中斷點)
for j in range(1, (len(c) - i)):
if ((c.at[i, 'a'], c.at[i, 'b']) != (c.at[(i + j), 'a'], c.at[(i + j), 'b'])):
break
# 把第一個重複出現的數值加入list
lst.append((c.at[i, 'a'], c.at[i, 'b']))
if j == 1:
i += 1 # 代表j = 0
elif (i + j) == length:
break # 循環結束,跳出迴圈
else:
i += j # i+j等於下一個新的起始點
print(lst)
if __name__ == "__main__":
main()
