想請問各位大大,小弟想將一csv檔中的資料取出,裡面資料分為兩列,第一列為IP,第二列為port位,目前抓到的資料為一個列表中的值會以逗號分別隔開,但我想將兩列中的資料合併為123.123.123.123:8080類似這樣該如何做比較適合
目前的程式如下:
import csv
from csv import reader
with open('D:\Roger\work\ShodanRay.csv', 'r') as csvfile:
csvfile = reader(csvfile)
rows = [row for row in csvfile]
print(rows)
已邀請的邦友 {{ invite_list.length }}/5
假設 ShodanRay.csv 內容為:
192.168.0.1,192.168.31.1
8000,8080
程式範例:
import csv
with open('ShodanRay.csv', newline='') as csvfile:
spamreader = csv.reader(csvfile, delimiter=',')
ls = [row for row in spamreader]
print(ls)
new_ls = [ls[0][i]+':'+ls[1][i] for i in range(0,len(ls[0]))]
print(new_ls)
輸出結果:
[['192.168.0.1', '192.168.31.1'], ['8000', '8080']]
['192.168.0.1:8000', '192.168.31.1:8080']
補充 force 大大 加點的使用 zip 函式範例:
import csv
with open('ShodanRay.csv', newline='') as csvfile:
ls = [ row for row in csv.reader(csvfile, delimiter=',') ]
new_ls= list(map(lambda x:x[0]+':'+x[1],list(zip(ls[0],ls[1]))))
print(ls)
print(new_ls)
輸出結果:
[['192.168.0.1', '192.168.31.1'], ['8000', '8080']]
['192.168.0.1:8000', '192.168.31.1:8080']
補充一個不用任何模組的範例:
ls = [line.split(',') for line in open('ShodanRay.csv','r').readlines()]
new_ls= list(map(lambda x:(x[0]+':'+x[1]).replace('\n',''),list(zip(ls[0],ls[1]))))
print(ls)
print(new_ls)
輸出結果:
[['192.168.0.1', '192.168.31.1'], ['8000', '8080']]
['192.168.0.1:8000', '192.168.31.1:8080']
import pandas as pd
df = pd.read_csv('example.csv', header=None)
df
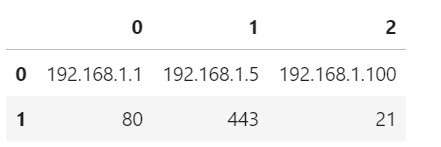
result = [(i + ":" + j) for i, j in zip(df.iloc[0], df.iloc[1])]
result

