excel中有一個工作表類似長這樣
| 專案名稱 | 專案leader | 參與人員 |
|---|---|---|
| 專案A | K | a |
| b | ||
| c | ||
| 專案B | R | b |
| c | ||
| 專案C | Z | c |
| d | ||
| e | ||
| f | ||
| g | ||
| 專案A | K | a |
| c | ||
| e |
希望可以整理成下表的樣子
| 專案名稱 | 專案leader | 參與人員 |
|---|---|---|
| 專案A | K | a,b,c |
| 專案B | R | b,c |
| 專案C | Z | c,d,e,f,g |
| 專案A | K | a,c,e |
專案名稱及專案leader有可能重複
但實際上是兩個不同時期的專案
成員也不同
依序整理下來沒有問題
但因為資料很多
手動會花很多時間
有沒有什麼方式可以讓他自動整理
謝謝
已邀請的邦友 {{ invite_list.length }}/5
E2:
=IFERROR(INDEX($A$1:$A$14,SUMPRODUCT(LARGE(($A$2:$A$14<>"")*ROW($A$2:$A$14),COUNTA($A$2:$A$14)+2-ROW()))),"")
向下複製到E3:E10。
F2:
=IFERROR(INDEX($B$1:$B$14,SUMPRODUCT(LARGE(($B$2:$B$14<>"")*ROW($B$2:$B$14),COUNTA($B$2:$B$14)+2-ROW()))),"")
向下複製到F3:F10。
G2:
=IFERROR(TEXTJOIN(",",,OFFSET($C$1,SUMPRODUCT(LARGE(($A$2:$A$14<>"")*ROW($A$2:$A$14),COUNTA($A$2:$A$14)+2-ROW()))-1,0,IFERROR(SUMPRODUCT(LARGE(($A$2:$A$14<>"")*ROW($A$2:$A$14),COUNTA($A$2:$A$14)+1-ROW())),COUNTA($C$1:$C$14)+1)-SUMPRODUCT(LARGE(($A$2:$A$14<>"")*ROW($A$2:$A$14),COUNTA($A$2:$A$14)+2-ROW())),1)),"")
向下複製到G3:G10。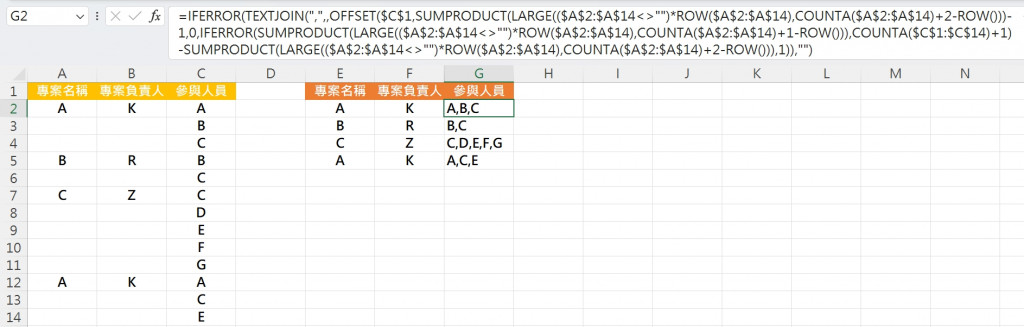
按你的表,假設 "專案名稱" 在 A1.
D2 便放 =IF(A2<>"",A2,D1)
E2 便放 =IF(B2<>"",B2,E1)
F2 便放 =IF(B2<>"",C2,F1&","&C2)
G2 便放 =IF(A2<>"","N",IF(A3<>"","Y","N"))
點選 D2至G2,然後向下拉,完成後只是 G 列最底那個要自己手動加回 "Y",然後篩選 G 列便可
使用python pandas解法,結構比VBA指令單純。
import pandas as pd
# 填補空白
df = pd.read_excel('book1.xlsx')
df = df.fillna(method='ffill')
# 比對
df2 = pd.DataFrame(columns=df.columns)
for i, g in df.groupby([(df['專案名稱'] != df['專案名稱'].shift()).cumsum()]):
df2.loc[i] = {'專案名稱':g['專案名稱'].tolist()[0],
'專案leader':g['專案leader'].tolist()[0],
'參與人員':','.join(g['參與人員'].tolist())}
print(df2)

