各位前輩們好,想請教關於請教Python程式語言當中關於機器學習預測的方向!
我手邊有一份類似下圖的資料,初步是希望透過類似鳶尾花的模型去做預測~
但是比起鳶尾花的機器學習範例,手邊數據還多了日期的資料,因此想請教前輩們:
假設我有4位患者(123、456、789、987、654),其中2為重複就診(123、456),
每位患者依照"不同日期"到院檢查,
檢視身體"健康指標1~6"與疾病診斷"糖尿病、高血壓、肝臟病、高血脂、心臟病",
直到病情嚴重到需要"住院"結束。
我想預測資料集中的患者們,根據檢查結果,誰有可能也會住院(到此為止,類似鳶尾花),此外,在何時或第幾次檢查時,會有住院的可能(這邊加入日期與患者是誰...找不到相關範例)。
查詢網路相關的範例或kaggle資料集似乎都沒有相關的範本可以參照,因此想請前輩們指點方向,該如何著手或可以參考哪個資料集範本做嘗試,再次感謝願意回答的前輩們!
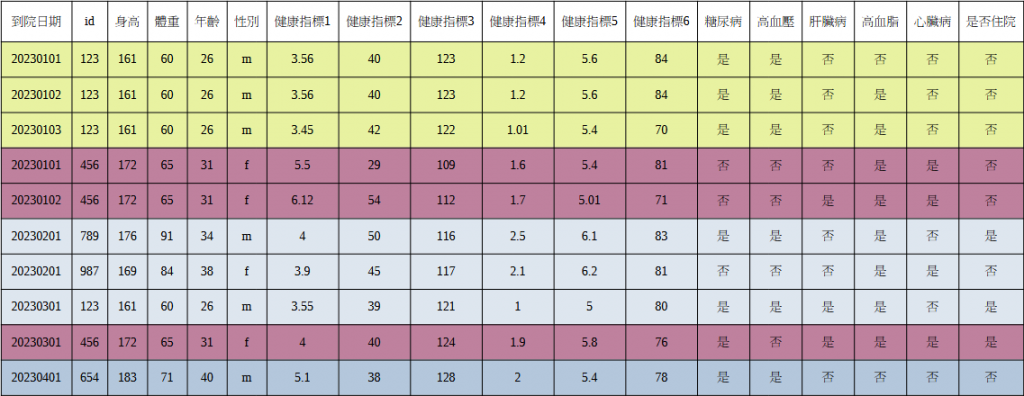
到院日期 id 身高 體重 年齡 性別 健康指標1 健康指標2 健康指標3 健康指標4 健康指標5 健康指標6 糖尿病 高血壓 肝臟病 高血脂 心臟病 是否住院
20230101 123 161 60 26 m 3.56 40 123 1.2 5.6 84 是 是 否 否 否 否
20230102 123 161 60 26 m 3.56 40 123 1.2 5.6 84 是 是 否 是 否 否
20230103 123 161 60 26 m 3.45 42 122 1.01 5.4 70 是 是 否 是 否 否
20230101 456 172 65 31 f 5.5 29 109 1.6 5.4 81 否 否 否 是 是 否
20230102 456 172 65 31 f 6.12 54 112 1.7 5.01 71 否 否 是 是 是 否
20230201 789 176 91 34 m 4 50 116 2.5 6.1 83 是 是 否 是 否 是
20230201 987 169 84 38 f 3.9 45 117 2.1 6.2 81 否 否 否 是 是 否
20230301 123 161 60 26 m 3.55 39 121 1 5 80 是 是 是 是 否 是
20230301 456 172 65 31 f 4 40 124 1.9 5.8 76 是 否 是 是 是 是
20230401 654 183 71 40 m 5.1 38 128 2 5.4 78 是 是 否 否 否 否
已邀請的邦友 {{ invite_list.length }}/5
只要可以做 Binary Classification,使用哪種模型不重要。
你需要的是更多的資料處理,尤其是針對時間尺度的變量,比如說:
Again,模型不重要,如果數據處理得夠詳盡確實,使用 Logistic Regression 就可以達成理想的效果了。
