我的客戶給了一個難題,他們說前端網頁可能會出現有難字的資料(姓民、地址...),當有難字時RequestBody中的Json會是big5格式;沒有難字會是utf-8。
我原本以為可以無腦.getBytes()->"UTF-8" 就解掉這個問題,但我發現資料進到API時就會被Java轉成utf-8,這樣資料就會直接損毀。
請問有可以同時處裡utf-8、big5編碼的方法嗎?
以下是目前的testCode
@RequestMapping("/Test")
@Operation(summary = "查詢發查資料")
public String big5Test(
@Valid @RequestBody(required = false) Map<String,String> request,
@RequestHeader(value = "app_id", required = false) String app_id,
@RequestHeader(value = "app_key", required = false) String app_key,
@RequestHeader(value = "source_id", required = false) String source_id,
@RequestHeader(value = "api_txno", required = false) String apiTxno) throws Exception{
String str = request.get("custName").toString();
System.out.println("set str: "+str);
byte[] Bytes = str.getBytes();
System.out.println("set Bytes: "+Bytes);
String strToUtf8 = request.get("custName").toString();
strToUtf8 = new String(strToUtf8.getBytes(),"UTF-8");
System.out.println("set strToUtf8: "+strToUtf8);
String strToBig5 = request.get("custName").toString();
strToBig5 = new String(strToBig5.getBytes(),"BIG5");
System.out.println("set strToBig5: "+strToBig5);
return str;
}
目前使用Postman測試
utf-8:
Content-Type:application/json; charset=utf8
Body:
{
"custName": "王曉明"
}
output:
set str: 王曉明
set Bytes: [B@2940f794
set strToUtf8: 王曉明
set strToBig5: ??????
big5:
Content-Type:application/json; charset=big5
Body:
{
"custName": "王曉明"
}
output:
set str: ������
set Bytes: [B@69a3b52
set strToUtf8: ������
set strToBig5: 嚙踝蕭嚙踝蕭嚙踝蕭
新增正式環境,我一樣請客戶打custName="王曉明":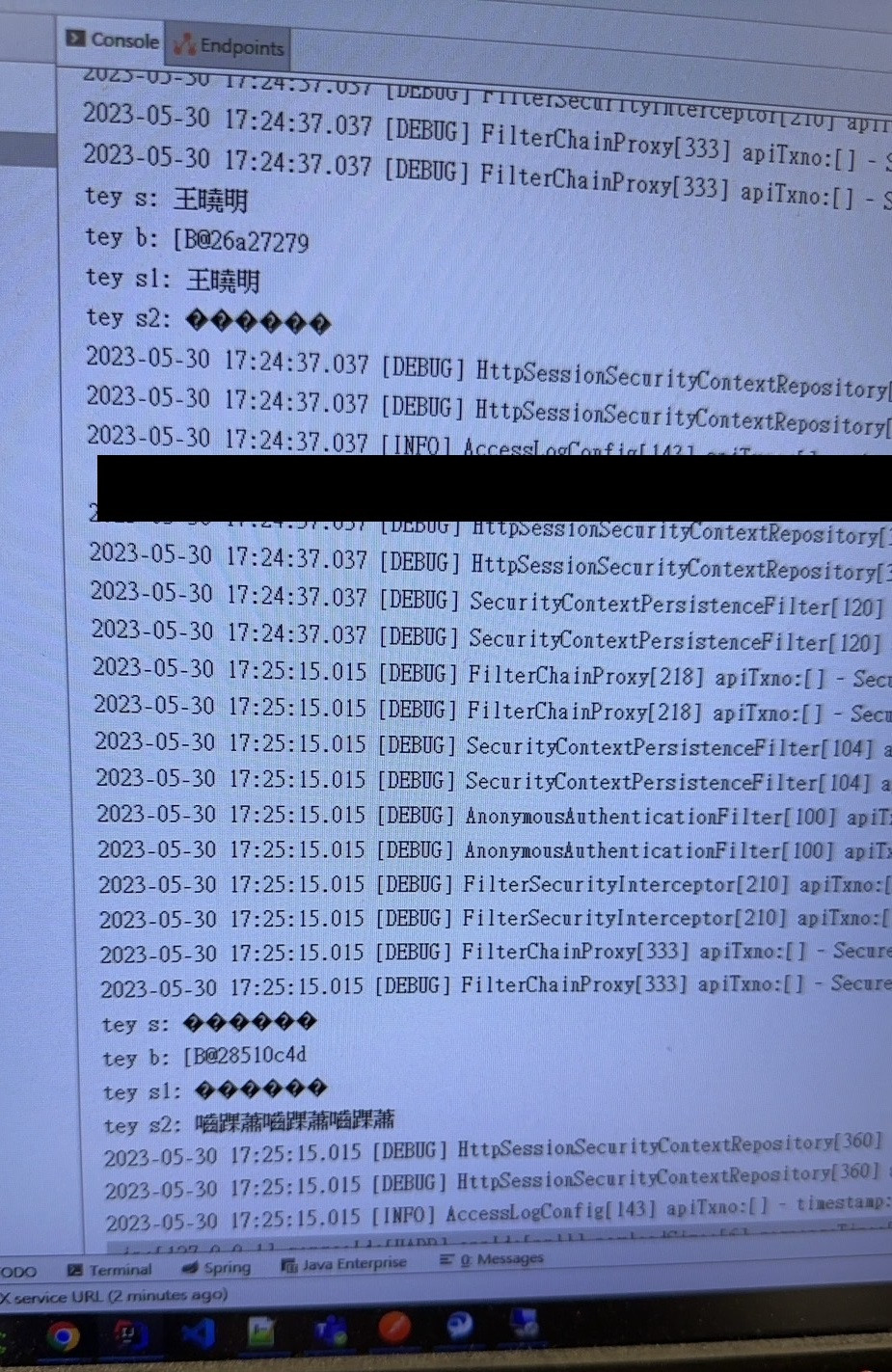
已邀請的邦友 {{ invite_list.length }}/5
我能想到的解是
Body:
{
"custName": "王曉明", // 不管什麼編碼前端全轉escape傳送, 後端直接存之後也直接回傳前端
.......... //其他欄位
}
先說一下,其實我 java 只碰過 Hello World(平常主要用其他語言)
不過針對這問題有一些想法,並查了一下資料,看看下面這些內容是否有用
首先,編碼問題我會去看原始字串的 bytes
會用十六進位的方式印出來
但是目前程式碼印 bytes 的方式似乎不是如此
它印出來的我猜是類似位址或物件 ID 而已
並非十六進位字串
這邊我寫了一個函數可以把 byte[] 轉成十六進位表示的 String
如有需要可以參考使用
// 把 byte[] 轉成 16 進位字串
public static String byteArray2Hex(byte[] byteArray) {
String outStr = "";
for (int i = 0; i < byteArray.length; ++i) {
int x = byteArray[i];
if (x < 0) {
x += 256;
}
outStr += String.format("%02x", x);
}
return outStr;
}
當我繼續去看 getBytes 的函數說明
發現它可以接收參數
把 string 以某種參數轉成 bytes
看到這邊,我會想到:
「request.get("custName").toString(); 拿到的東西是原始 bytes 嗎?還是在這之前已經被解碼過一次了?」
如果先前已經被解碼過一次,那麼 spring 是怎麼選擇解碼的 Encoding 的?
如果發生解碼錯誤,那又會怎麼處理?
如果錯誤的編碼會跳過或是用其他符號代替,那麼資訊有可能會遺失
如此一來,我們再去處理已經遺失的資訊不就無法得到正確的結果?
我再去找關於 Spring 編碼相關的機制(這邊偷懶直接問AI)
它好像會看 request 的 Content-Type 去解碼
也就是說假設 request 的 Content-Type 是正確的
那麼程式應該不用手動處理編碼的問題
假設 request 的 Content-Type 是錯誤或沒有送
那麼應該想辦法拿到原始 body 的資料手動解析
這可能就很麻煩了
以上是我的想法提供參考
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
public class EncodingChecker {
public static void main(String[] args) {
String str = "你好,世界!";
byte[] bytes = str.getBytes(StandardCharsets.ISO_8859_1);
// Check if the byte sequence is valid in Big5 encoding
boolean isBig5 = Charset.forName("Big5").newDecoder().decode(ByteBuffer.wrap(bytes)).toString().equals(str);
// Check if the byte sequence is valid in UTF-8 encoding
boolean isUTF8 = Charset.forName("UTF-8").newDecoder().decode(ByteBuffer.wrap(bytes)).toString().equals(str);
if(isBig5==true){
..........}
else {
..............
}
}
}
因為發問者是透過網路處理別人送來的資料,流程是:
原始送來的資料 => spring 解析 => 開發者處理 spring 解析出來的字串
如果在第 2 步就出問題,那麼第 3 步無論怎麼做都無法取得正確的結果
因為我也沒在寫java,更不用說spring boot了,但我猜第二步一定會有問題。
難字是造字,有難字送big5,造字沒造字表一定會出問題。
所以我才說前端應該送難字看看解不解的出來。
PS.這前端真神,要我像這樣選擇性的送我還真的做不到。
