各位大大好!我可以請教python讀兩個excel問題!
data.xlsx是學生成績單:
分別是學號、國文、英文、數學、理化成績的分數
照片如下: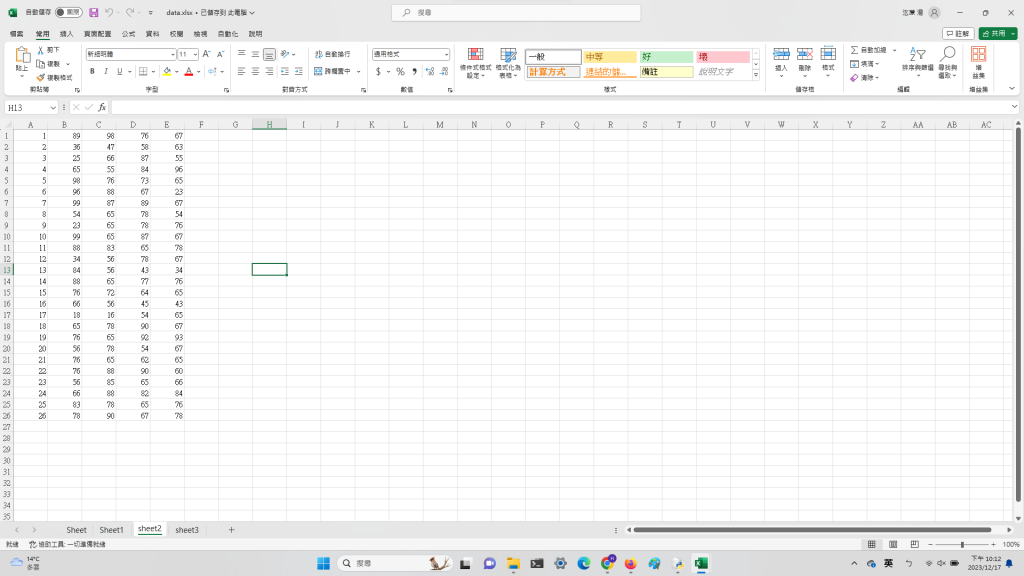
data2.xlsx是學生成績單:
分別是學號、國文、英文、數學、理化成績的分數
照片如下: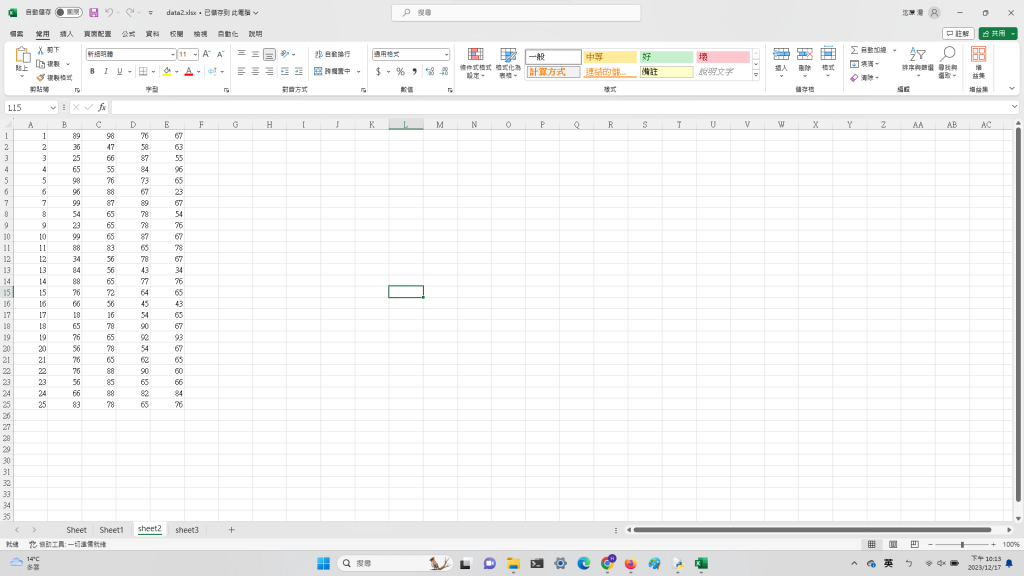
import openpyxl
import pandas as pd
import numpy as np
# 讀取第一個 Excel 檔案
wb1 = openpyxl.load_workbook('data.xlsx')
sheet1 = wb1['sheet2']
# 讀取第二個 Excel 檔案
wb2 = openpyxl.load_workbook('data2.xlsx')
sheet2 = wb2['sheet2']
# 提取兩個工作表的最大行和最大列
max_row = max(sheet1.max_row, sheet2.max_row)
max_column = max(sheet1.max_column, sheet2.max_column)
print("max_row=", max_row, end='\n')
print("max_column=", max_column, end='\n')
# 將 Excel 資料轉換成 Pandas DataFrame
df1 = pd.DataFrame(sheet1.values)
df2 = pd.DataFrame(sheet2.values)
# 使用 NumPy 進行比較,並找出不同的值
mask = df1.ne(df2)
diff_locations = np.where(mask)
# 創建新的工作簿
wb3 = openpyxl.Workbook()
sheet3 = wb3.active
# 創建一個空的 DataFrame
result_df = pd.DataFrame(columns=["學號", "國文成績", "英文成績", "數學成績", "理化成績"])
s1=[]
s2=[]
start = 1
end = 5
while end <= max_row:
for row, col in zip(*diff_locations):
# 檢查索引位置是否有效(針對第一個檔案)
if row < df1.shape[0] and col < df1.shape[1]:
value1 = df1.iloc[row, col]
s1.append(value1)
print("s1=",s1)
sheet3.append(s1)
# 檢查索引位置是否有效(針對第二個檔案)
if row < df2.shape[0] and col < df2.shape[1]:
value2 = df2.iloc[row, col]
s2.append(value2)
print("s2=",s2)
sheet3.append(s2)
start += 5
end += 5
result_df["學號"] = pd.Series(s1)
result_df["國文成績"] = pd.Series(s1)
result_df["英文成績"] = pd.Series(s1)
result_df["數學成績"] = pd.Series(s1)
result_df["理化成績"] = pd.Series(s1)
# 使用 loc[] 逐個元素填充 DataFrame
#result_df.loc[0] = pd.Series(s1)
#result_df.loc[len(result_df)] = pd.Series(s2)
# 如果需要印出 DataFrame,可以使用以下方式
print(result_df)
# 儲存新的 Excel 檔案
wb3.save('data3.xlsx')
# 存儲到 data3.xlsx
result_df.to_excel('data3.xlsx', index=False)
執行完後,data3.xlsx檔內容如下: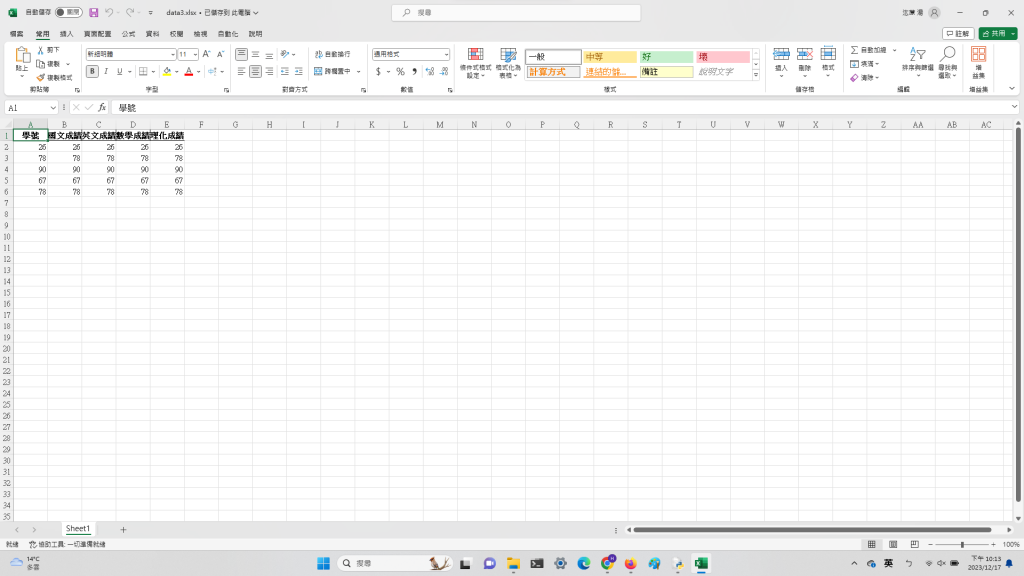
為甚麼data3.xlsx檔內容不是印出結果如下呢?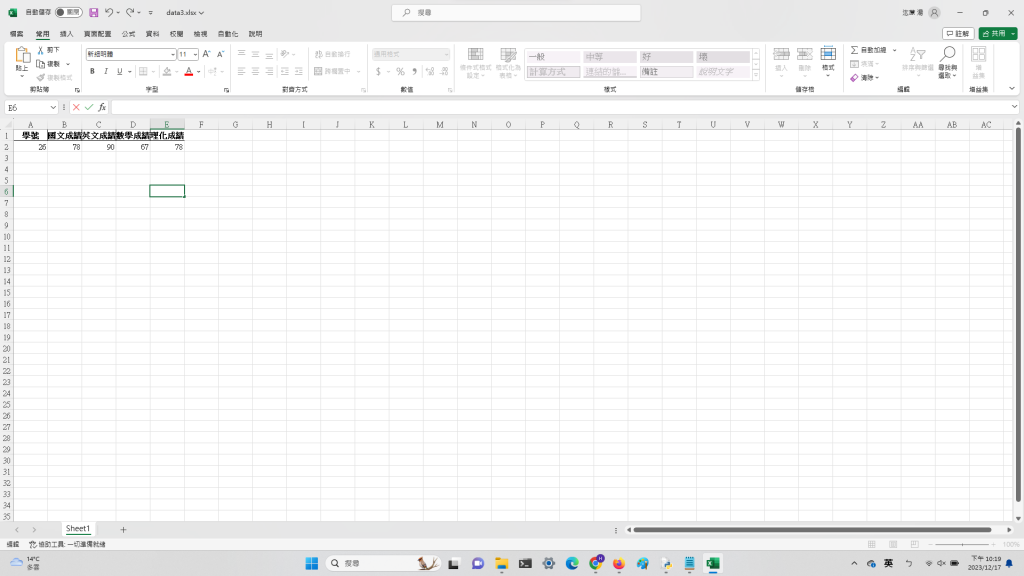
我要怎麼修改上述程式碼呢?
已邀請的邦友 {{ invite_list.length }}/5
看你程式輸出基本上就可以判定是迴圈和欄位跑錯。
但是你沒有具體寫出你真正想輸出的結果,不太好處理。
圖片以外最好還要詳細描述,例如:
想要用python讀取excel,
A欄開始分別是學號、B:國文、C:英文、D:數學、E:理化。
已知excel1 有25筆,excel2欄有26筆,excel1&2前25筆是相同的,
所以需要單獨列出第26筆。
輸出應為A、B、C、D、E
A:26 B:{國文成績}、C:{英文成績}、D:{數學成績}、E:{理化成績}。
但是實際輸出變成
A、B、C、D、E
26、26、26、26、26
{國文成績}、{國文成績}、{國文成績}、{國文成績}、{國文成績}
.
.
.
該如何解決上述錯誤;
一些邏輯錯誤和重複使用相同的資料的問題;但不確定是不是你要的邏輯,
以下是我對程式碼的修改建議:
刪除了使用 pandas 和 numpy 的部分,因為你只需要使用 openpyxl 來處理 Excel 檔案。
使用兩個迴圈來複製前 25 筆資料到新的工作表。
使用另一個迴圈來複製第 26 筆資料到新的工作表。
儲存新的 Excel 檔案。
這些修改將使程式碼能夠正確地處理你所描述的需求,將前 25 筆資料從第一個 Excel 檔案複製到新的工作表,並將第 26 筆資料從第二個 Excel 檔案複製到新的工作表。
import openpyxl
import pandas as pd
# 讀取第一個 Excel 檔案
wb1 = openpyxl.load_workbook('data.xlsx')
sheet1 = wb1['sheet2']
# 讀取第二個 Excel 檔案
wb2 = openpyxl.load_workbook('data2.xlsx')
sheet2 = wb2['sheet2']
# 提取兩個工作表的最大行和最大列
max_row = max(sheet1.max_row, sheet2.max_row)
max_column = max(sheet1.max_column, sheet2.max_column)
print("max_row=", max_row, end='\n')
print("max_column=", max_column, end='\n')
# 創建新的工作簿
wb3 = openpyxl.Workbook()
sheet3 = wb3.active
# 複製前25筆資料
for row in range(1, 26):
for col in range(1, max_column + 1):
value = sheet1.cell(row=row, column=col).value
sheet3.cell(row=row, column=col, value=value)
# 複製第26筆資料
for col in range(2, max_column + 1):
value = sheet2.cell(row=26, column=col).value
sheet3.cell(row=26, column=col, value=value)
# 儲存新的 Excel 檔案
wb3.save('data3.xlsx')
上面是已知的狀況下單獨輸出第26筆,你先測一下是否是對的。
下面是嘗試找到不同的就要輸出,一樣需要你自行驗證後修改。
import openpyxl
# 讀取第一個 Excel 檔案
wb1 = openpyxl.load_workbook('data.xlsx')
sheet1 = wb1['sheet2']
# 讀取第二個 Excel 檔案
wb2 = openpyxl.load_workbook('data2.xlsx')
sheet2 = wb2['sheet2']
# 提取兩個工作表的最大行和最大列
max_row = max(sheet1.max_row, sheet2.max_row)
max_column = max(sheet1.max_column, sheet2.max_column)
print("max_row=", max_row)
print("max_column=", max_column)
# 創建新的工作簿
wb3 = openpyxl.Workbook()
sheet3 = wb3.active
# 比較兩個工作表的資料
different_rows = []
for row in range(1, max_row + 1):
different = False
for col in range(1, max_column + 1):
value1 = sheet1.cell(row=row, column=col).value
value2 = sheet2.cell(row=row, column=col).value
sheet3.cell(row=row, column=col, value=value1)
if value1 != value2:
different = True
if different:
different_rows.append(row)
# 在新的工作表中輸出不同的資料
wb4 = openpyxl.Workbook()
sheet4 = wb4.active
for row in different_rows:
for col in range(1, max_column + 1):
value = sheet2.cell(row=row, column=col).value
sheet4.cell(row=row, column=col, value=value)
# 儲存新的 Excel 檔案
wb3.save('data3.xlsx')
wb4.save('different_data.xlsx')
看你同樣的事情,發了4篇.給你一些建議.
測試資料不要變來變去.
截圖方式要考慮到有效資訊的範圍,例如你這篇,一大堆空白,一堆數字很小,是不是調整一下較好.
你之前也有一篇,好像是2吧,只有一個數字不同,但是你的cursor 沒放到那裡,變成要幫你找.
你最好把測試資料統一,整理好,這裡可以上傳檔案的,用壓縮的,放不下時也可以找其他地方,
例如一些雲端服務.不然要別人還要自己打開excel,看著一堆小小的字,慢慢打.
Python的主力工作馬是List, List 跟 List 是可以比較的.
Python讀Excel, Cell 可以轉 List, 然後善用 List.
做這個的目的是什麼? 要先能夠說清楚,不是用Python處理Excel,而是資訊技術有非常多,
目的與手段要能分清楚,這個我時常提到,當然有些人還因為這個會有些神奇的反應,例如說我發言不友善,還要檢舉.希望你不是這樣的人.
另外,我建議你別把Excel 當作處理資料的主力,你看你實際使用時,多麼的不方便,之前也有一個
也是一直用Excel 搭 Python, 大概是市面上有些書或是課程,使用了Excel當例子.
那個也只是例子而已. 然後就沒有什麼人會回答,所以就 喔,又有菜鳥堅持用Excel喔,
那算了....
