各位您好:
我第一次寫模型訓練的py,遇到一些問題。
我嘗試使用apscheduler來每15分鐘運行預測程式一次,當我只有一個線程在執行預測程式時,一切都沒有問題。
但我嘗試跑訓練程式(單跑訓練程式,且epochs, batch_size = 10, 128,大約5分鐘就能跑完),每1小時訓練一次時,排程第一次開始,就會出現卡死或是遺失的情形,且執行scheduler.shutdown後,訓練程式卻開始執行了(完全沒有報錯)。而且我看GPU運行情況,在訓練排程開始時,GPU完全沒有被使用,直到關掉排程GPU才開始被使用。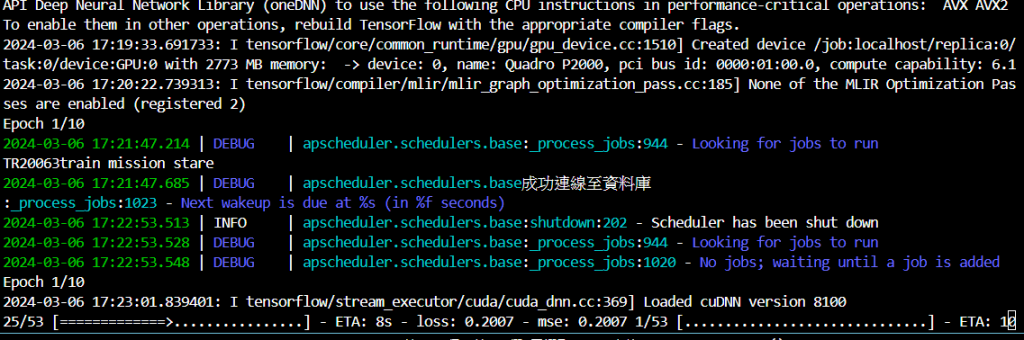
我查了很多網站但大多無果。所以想上來詢問,這是因為什麼原因?
配置:GPU-Quadro P2000 python-3.8 (確認tf相關安裝都正確,不使用apscheduler,只接呼叫func的情況下,訓練程式與預測程式都正常運行也能使用到GPU。)
以下是我懷疑有問題的程式碼,拜託各位賜教了~如有任何問題都勞煩您提出意見了~在此先謝謝各位~
class Main():
def __init__(self):
self.id_list = [("08020","Load"), ("312696","Load")]
self.train_main_dict = {id: Write_SQL_Predict_Data(id, use_load) for id, use_load in self.id_list}
self.predict_main_dict = {id: Write_SQL_Predict_Data(id, use_load) for id, use_load in self.id_list}
def train_main(self, month, time, a, b, c):
for main_name, main_class in self.train_main_dict.items():
print(main_name + "train mission stare")
main_class.creat_now(month)
main_class.get_sql_data(kinds="Train")
main_class.retime()
main_class.warng_df(time)
main_class.creat_data(time)
main_class.Min_Max_Scaler(kinds="Train")
main_class.create_input_output(a, b, c)
main_class.train_model()
def predict_main(self, month, time, a, b, c):
for main_name, main_class in self.predict_main_dict.items():
print(main_name + "predict mission stare")
main_class.creat_now(month)
main_class.get_sql_data(kinds="Predict")
main_class.retime()
main_class.warng_df(time)
main_class.creat_data(time)
main_class.Min_Max_Scaler(kinds="Predict")
main_class.create_input_output(a, b, c)
main_class.get_segment()
main_class.predict_load(b)
main_class.wrang_predict_load(b)
# main_class.write_sql(time)
if __name__ == '__main__':
load_main = Main()
load_main.predict_main(1, "5T", 96, 48, 1)
load_main.predict_main(1, "5T", 96, 48, 1)
#執行到此都沒有錯誤
trace = logger.add('predict_load_hours_run.log', retention="30 days", level='INFO',
format="{time:YYYY-MM-DD HH:mm:ss} {level} From {module}.{function} : {message}")
executors = {'default': ThreadPoolExecutor(4)}
job_defaults = {'coalesce': True, 'max_instances': 3}
scheduler = BackgroundScheduler(
executors=executors, job_defaults=job_defaults, timezone='Asia/Taipei')
scheduler._logger = logger
def listener(event):
if event.exception:
logger.error(
f"Job {event.job_id} encountered an error: {event.exception}")
else:
logger.success(f"Job {event.job_id} executed successfully.")
# Setup logging
scheduler.add_job(load_main.train_main, args=[ 1, "5T", 96, 48, 1], trigger="interval", minutes=3, id="predict_main_4hours")
scheduler.add_listener(listener, EVENT_JOB_EXECUTED | EVENT_JOB_ERROR)
try:
scheduler.start()
scheduler.print_jobs()
jobs = scheduler.get_jobs()
logger.info(jobs)
while True:
pass
except KeyboardInterrupt:
pass
except Exception as e:
print("發生異常:", str(e))
finally:
scheduler.shutdown(wait=False)
logger.remove(trace)
以下為基本我認為不是造成問題的程式碼,如有需要改進的地方也歡迎您提供意見了~
class SQLConnector():
def __init__(self):
config = configparser.ConfigParser()
config.read('config.ini')
self.__server = config.get('DATABASE', 'server')
self.__userid = config.get('DATABASE', 'userid')
self.__password = config.get('DATABASE', 'password')
self.__databasename = config.get('DATABASE', 'databasename')
self.conn = None
def __enter__(self):
self.connect()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.close_connection()
def connect(self):
try:
self.conn = pymssql.connect(server=self.__server, user=self.__userid,
password=self.__password, database=self.__databasename)
print("成功連線至資料庫")
except Exception as e:
print(f"錯誤: {str(e)}")
raise e
def close_connection(self):
try:
if self.conn:
self.conn.close()
# print("連線已關閉")
except Exception as e:
print(f"Error while fetching data from database: {str(e)}")
raise e
class Model(Warng_Data):
def __init__(self, id, Use_Load):
super().__init__(id, Use_Load)
self.scaler = None
self.mse_result = None
self.predict_load_list = None
def predict_load(self,count):
model = tf.keras.models.load_model(r"C:\Users\chanen.pen\MODEL\{}keras_hours_model.h5".format(self.id_str))
# model = tf.keras.models.load_model(r"C:\Users\TF_gpu\Train_model\{}keras_hours_model.h5".format(self.id_str))
y_test = self.data_y.reshape((self.data_y.shape[0], self.data_y.shape[1], 1))
y_test_pred = model.predict(self.data_x)
y_pred = np.squeeze(y_test_pred)
y_test = np.squeeze(y_test)
y_pred = y_pred.flatten()
y_test_pred_1 = np.zeros(shape=(len(y_pred), 7))
y_test_pred_1[:, 1] = y_pred
# plot_y_test_pred = y_test_pred_1[:, 1]
plot_y_test_pred = self.scaler.inverse_transform(y_test_pred_1)[:, 1]
# 最後預測結果/
self.predict_load_list = plot_y_test_pred[-count:]
self.predict_load_list = np.where(self.predict_load_list < 0, 0, self.predict_load_list)
def train_model(self):
path_checkpoint = r"C:\Users\chanen.pen\MODEL\{}model_hours_checkpoint.h5".format(self.id_str)
# path_checkpoint = r"C:\Users\TF_gpu\Train_model\model_checkpoint\{}model_hours_checkpoint.h5".format(self.id_str)
verbose, epochs, batch_size = 1, 10, 128
callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=4)
modelckpt_callback = tf.keras.callbacks.ModelCheckpoint(
monitor="val_loss",
filepath=path_checkpoint,
save_weights_only=True,
save_best_only=True,
)
n_timesteps1, n_features1, n_outputs1 = self.data_x.shape[1], self.data_x.shape[2], self.data_y.shape[1]
self.data_y = self.data_y.reshape((self.data_y.shape[0], self.data_y.shape[1], 1))
model = tf.keras.Sequential()
main_input = tf.keras.Input(shape=(n_timesteps1, n_features1), name='main_input')
con1 = tf.keras.layers.Bidirectional(tf.keras.layers.GRU(128, activation='tanh', return_sequences=True))(main_input)
x1 = tf.keras.layers.Bidirectional(tf.keras.layers.GRU(200, activation='tanh', return_sequences=True))(con1)
x1 = tf.keras.layers.Bidirectional(tf.keras.layers.GRU(200, activation='tanh', return_sequences=True))(x1)
x3 = tf.keras.layers.Bidirectional(tf.keras.layers.GRU(128, activation='tanh', return_sequences=True))(x1)
x = tf.keras.layers.MaxPooling1D(pool_size=3, padding='same')(x3)
x = tf.keras.layers.Dense(64, activation='linear')(x)
x = tf.keras.layers.Dense(16, activation='linear')(x)
x = tf.keras.layers.Dense(1, activation='linear')(x)
model = tf.keras.Model(main_input, x)
Adam_opti = tf.keras.optimizers.Adamax(learning_rate=0.001)
model.compile(loss="mse", optimizer=Adam_opti, metrics="mse")
history = model.fit(self.data_x, self.data_y, epochs=epochs, batch_size=batch_size,
validation_split=0.2, verbose=verbose, callbacks=[ modelckpt_callback])
self.mse_result = history.history['val_mse'][-1]
# model.save(r"C:\Users\TF_gpu\Train_model\{}keras_hours_model.h5".format(self.id_str))
model.save(r"C:\Users\chanen.pen\MODEL\{}keras_hours_model.h5".format(self.id_str))
已邀請的邦友 {{ invite_list.length }}/5
