您好:
語法大致如下
;with a as(
),b as(
),c as(
處理A
)select * from c
left join (
....資料查詢J01
) j01 on ...
left join (
....資料查詢J02
) j02 on...
只要我用join J02 這一段,原來篩選時間由1秒內 慢到5秒
而我講 ....資料查詢J02 , 放到CTE 內一個查詢 ,他很快
, j02_CTE (
....資料查詢J02
)
但是 我在將
select * from c
left join J02_CTE
也是變慢
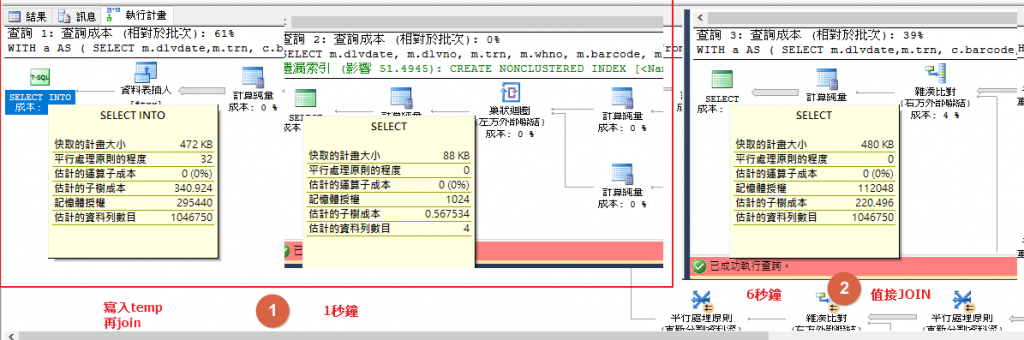
最後,我只能間原來的查詢,先寫到 #temp
再用#temp join left join (
....資料查詢J02
) j02 on...
結果一下子就出來了
這要如何找出問題
另外,原本有一個日期轉換的func,若再原來的語法下,轉換也是整個拖慢
若我用#temp 再來轉換,也是一下子就出來。
請問有什麼方式可以找到問題
執行計畫,也沒有出現遺漏索引要處理
已邀請的邦友 {{ invite_list.length }}/5
變慢主要原因都是未充分運用最佳索引,建議仔細檢視執行計畫,每一段是否都用到最佳的索引,也可以比較查詢很快的SQL與很慢的SQL執行計畫之間的差異。
你這種情況我有聽前輩分享過
SQL會自己判斷最佳的執行計畫,
但要是你加入的表越多那此執行計畫可能越不準確
要解決此問題有三種方法
1.建立索引
2.強制使用索引
3.建立臨時表(讓執行計畫重新判斷
所以你使用#temp 速度反而會變快
然後前輩推薦第3種,因為建立索引會花費內存,除非是必要否則不會去建立
要使用JOIN滿以下有幾點要特別的注意
1.ON的條件式,兩邊的表一定要使用有索引的欄位。
2.不要使用運算式的方式處理。
3.能不要用到 GROUP 就不要用,(當然,我了解有些情況是沒辦法)
4.不需要 ORDER
5.大資料量的不要用JOIN。如真的要用,最好搭配子查尋再處理。
認真來說,我現在已經是偏好使用資料關連容器的做法。也就是ORM。
JOIN的方式已經很少用了。
您好:盡量去配合這些注意事項
所以我有先子查詢好在去JOIN,但就變慢了....
且神奇的是, 沒有加入這一個變慢的join時,單獨用一個FUNCTION去計算日期,結果也變慢...
請問您說的「資料關連容器的做法」是?這是是用於 類似C# 與 SERVER端的做法嗎?
目前都是用報表,鎖已會件PROC 寫出結果,呈現
謝謝
「單獨用一個FUNCTION去計算日期,結果也變慢...」
其實這個動作就是我說的第2點了。
當然也不是說不要用。只是要很小心使用。但能不用就不用。
因為很容易一個沒處理好就會造成全表搜尋而變慢。
ORM全名是叫 Object Relational Mapping
簡單來說,就是將資料庫轉成一種物件使用的概念。
在關聯的部份來說。一般SQL語法都是用JOIN。
而在ORM是各自SELECT資料後,再進行組合。
簡單說個例子好了。
像是一個SQL是
SELECT * FROM db1
LEFT JOIN db2 ON (db2.id=db1.id)
WHERE id IN (1,2,3,4,5)
在ORM則會先
SELECT * FROM db1 WHERE id IN (1,2,3,4,5)
SELECT * FROM db2 WHERE id IN (db1拿到的對應ID值)
然後再組合到一個物件內如
[
{
"id":1
"db2:{
id:1
data:""
}
},
{
"id":2
"db2:{
id:2
data:""
}
},
....................
]
上面只是簡單的例子,但實際上應用的範圍很廣。
不過ORM也不是萬能的就是了。
因為建立了物件處理的關係。
它有機會會使用比較大量的記憶體。
如果應用的不好的情況下。
