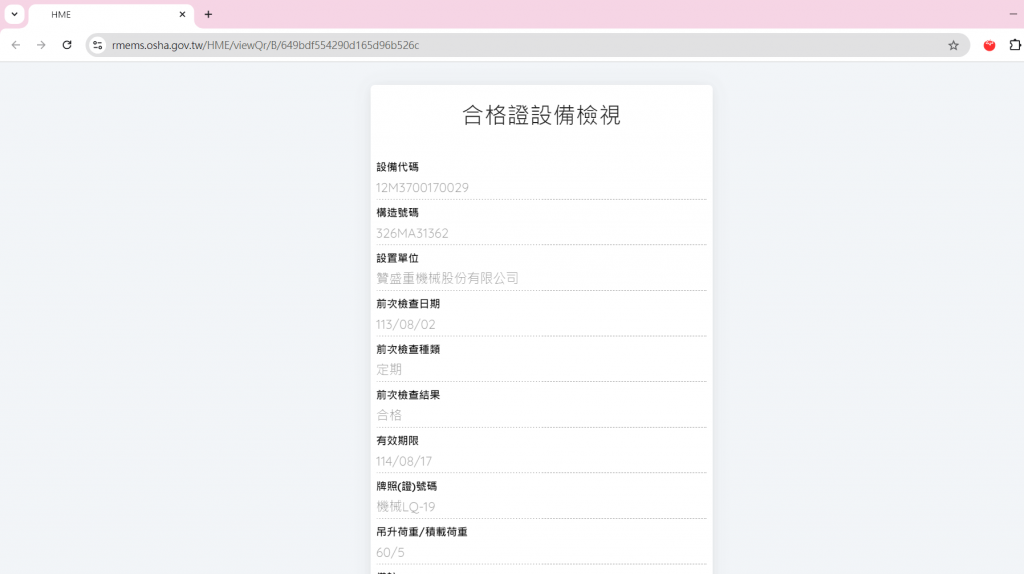
想使用爬蟲,但遇到一個網站,完全看不到裡面相應的內容
請問一下該如何處理?麻煩高手提供一下方向,謝謝
https://rmems.osha.gov.tw/HME/viewQr/B/649bdf554290d165d96b526c
已邀請的邦友 {{ invite_list.length }}/5
這個是網頁下載回來之後瀏覽器才執行其中的 JavsScript 去取得真正的資料, 可以透過按 F12 開啟網頁開發者工具觀察, 像是這樣:
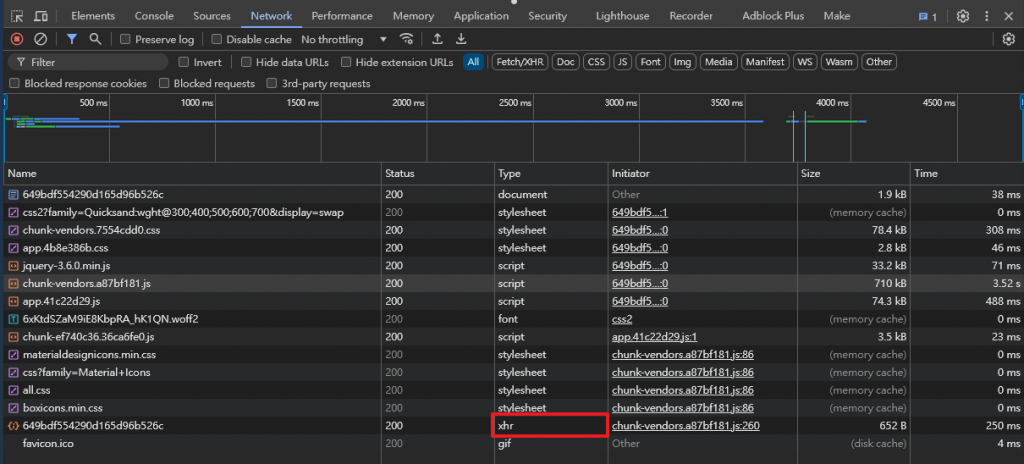
切換到 Network 頁次, 按重新載入, 等所有傳輸完畢, 標示為 XHR 的就是網頁中的 JavaScript 程式碼執行的下載工作, 按一下這一筆工作, 就會看到詳細的結果:
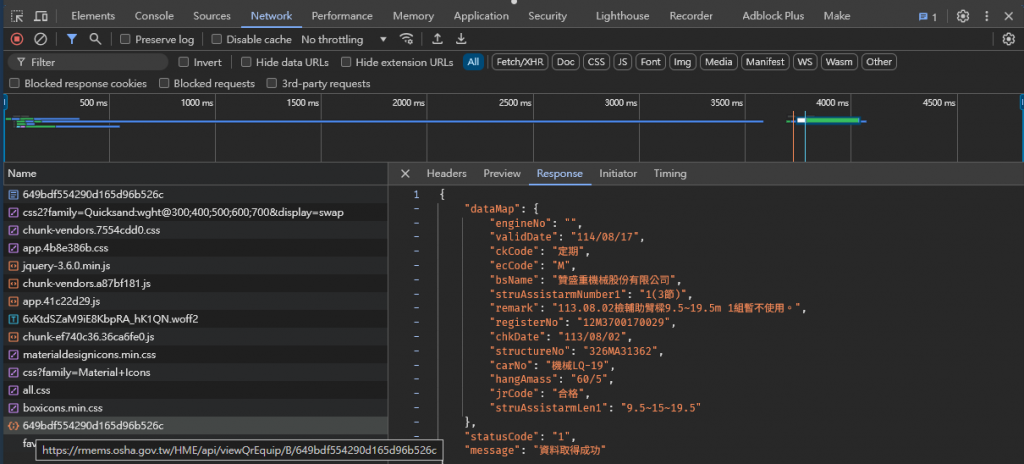
就可以看到實際上這些資料的下載網址, 以及下載回來的資料內容。所以你只要透過一樣的網址就可以取得 JSON 格式的資料, 程式就可以直接處理了。