在前一篇文章中,有稍微帶過了DataFrames這個package的功能,今天要更進一步介紹如何使用DataFrames來讀取和分析表格式的資料。
Kaggle上的Titanic問題是一個相當適合用來介紹DataFrames的資料集。Titanic問題也是kaggle上其中一個被歸類在101的問題。這個題目包含了一個training set和一個test set。training set包含了一些旅客的登錄資料以及他們是否生還,而題目要問的就是要根據這個training set找出登錄資料和生還者之間的關係,接著預測test set裡面的旅客是否生還。這組資料不大不小,欄位不多,但是包含了不同的資料型態,很適合拿來學習用。
這個資料集可以從這個頁面下載,下載了之後就開始分析這個資料集。
第一件是當然是把資料讀進來。還沒安裝DataFrames這個套件的話可以在julia的環境底下用Pkg.add()來安裝
julia>Pkg.add("DataFrames")
接著就可以用readtable來把資料讀進來:
using DataFrames
df=readtable("train.csv")
readtable()會傳回一個資料結果DataFrame,我們可以用typeof來檢驗
julia> typeof(df)
DataFrame (constructor with 22 methods)
直接在julia環境底下鍵入df或是在julia檔案裡輸入println(df)就會出現以下的畫面,我的顯示器剛好可以裝下全部的欄位:
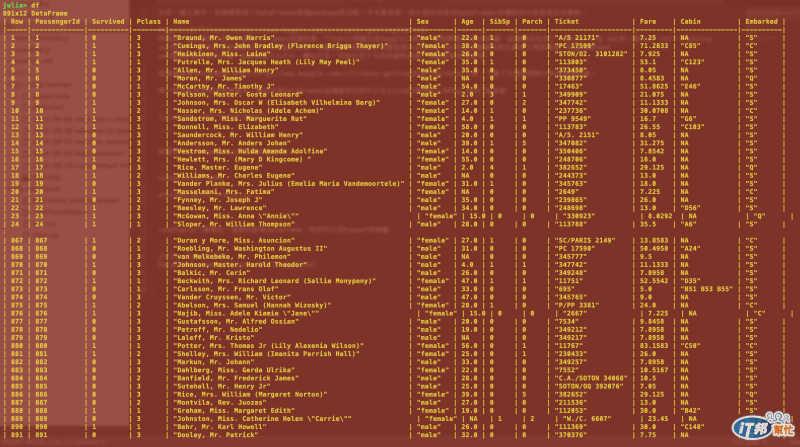
也可以用head(df)或是tail(df)來顯示前幾筆或是最後幾筆的資料。這幾個指令都是很常用來快速顯示資料片段的指令。
另一個很好用的指令是describe(),它類似R的summary,可以用來看看每個欄位(column)的資料型態和大致情況:
julia> describe(df)
PassengerId
Min 1.0
1st Qu. 223.5
Median 446.0
Mean 446.0
3rd Qu. 668.5
Max 891.0
NAs 0
NA% 0.0%
Survived
Min 0.0
1st Qu. 0.0
Median 0.0
Mean 0.3838383838383838
3rd Qu. 1.0
Max 1.0
NAs 0
NA% 0.0%
Pclass
Min 1.0
1st Qu. 2.0
Median 3.0
Mean 2.308641975308642
3rd Qu. 3.0
Max 3.0
NAs 0
NA% 0.0%
.......
NA是用來表示資料裡頭的「從缺」的值,作用和R或是Matlab裡的Nan是一樣的。但是julia有一個非常特殊的設計: NA在julia是一個資料型別,而且任何數字和NA做數值運算之後也會變成NA。例如:
julia> typeof(NA)
NAtype (constructor with 1 method)
julia> 1+NA
NA
julia> 1*NA
NA
也就是說,julia的NA具有會「擴散」的特性,舉個例子:我們先用@data來建立一個純數值的DataFrame:
julia> dm = @data([NA 0.0; 0.0 1.0])
2x2 DataArray{Float64,2}:
NA 0.0
0.0 1.0
把dm作矩陣相乘之後可以發現只要碰到NA的數字也都NA了。
julia> dm*dm
2x2 DataArray{Float64,2}:
NA NA
NA 1.0
DataFrame完全可以當作julia的內建Array來使用。比方說我們可以取出任意一列:
julia> df[1,:]
1x12 DataFrame
| Row | PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|-----|-------------|----------|--------|---------------------------|--------|------|-------|-------|-------------|------|-------|----------|
| 1 | 1 | 0 | 3 | "Braund, Mr. Owen Harris" | "male" | 22.0 | 1 | 0 | "A/5 21171" | 7.25 | NA | "S" |
或是是任意一行的資料
julia> df[:,4]
891-element DataArray{UTF8String,1}:
"Braund, Mr. Owen Harris"
"Cumings, Mrs. John Bradley (Florence Briggs Thayer)"
"Heikkinen, Miss. Laina"
"Futrelle, Mrs. Jacques Heath (Lily May Peel)"
⋮
"Behr, Mr. Karl Howell"
"Dooley, Mr. Patrick"
要注意的是,這會傳回一個型別為DataArray的值:
julia> typeof(df[:,4])
DataArray{UTF8String,1} (constructor with 1 method)
我們也可以直接用欄位的名稱來做這件事:
julia> df[:,"Name"]
891-element DataArray{UTF8String,1}:
"Braund, Mr. Owen Harris"
"Cumings, Mrs. John Bradley (Florence Briggs Thayer)"
"Heikkinen, Miss. Laina"
"Futrelle, Mrs. Jacques Heath (Lily May Peel)"
⋮
"Behr, Mr. Karl Howell"
"Dooley, Mr. Patrick"
或是
julia> df[:,:Name]
它們的作用都是一樣的,可以視情況選用適合的呼叫方法。
另外也可以過濾出符合條件的資料,例如
julia> newdf=df[df[:Sex].=="female",:]
newdf就會包含所有女性乘客的資料。
如果你有使用R或是pandas的經驗的話,就會覺得這些語法都似曾相識,很容易就可以上手。在下一篇我們會進一步分析這些個資料,同時介紹更多有關於DataFrame和julia的功能。

