該程式利用 Python 開發,結合多個強大的文本處理與翻譯工具,為用戶提供了一個從 PDF 論文到翻譯後 Word 文檔的全自動流程。主要適用於需要快速掌握大量英文資料、文獻或技術報告的場景,特別是學術研究者、專業技術人員或需要跨語言工作的從業者。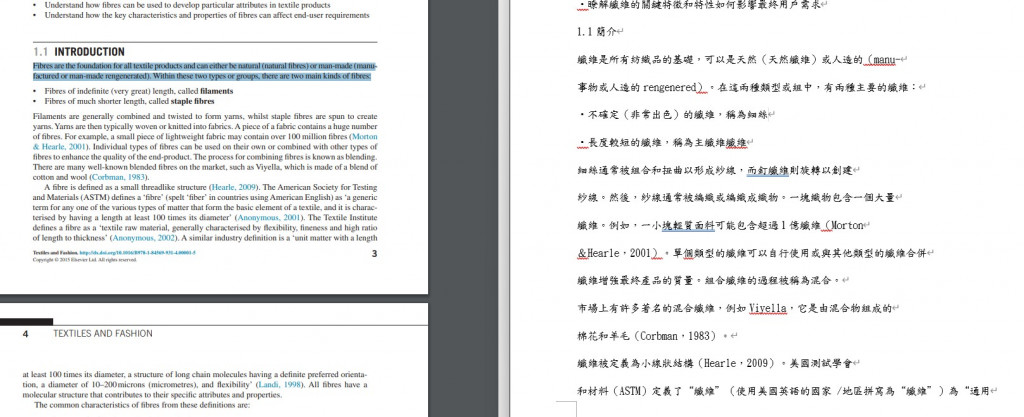
C:/Program Files/Python312/python.exe" -m pip install googletrans==4.0.0-rc1
C:/Program Files/Python312/python.exe" -m pip install opencc-python-reimplemented
C:/Program Files/Python312/python.exe" -m pip install python-docx
C:/Program Files/Python312/python.exe" -m pip install pdfplumber
PDF 文字擷取
import pdfplumber
翻譯
from googletrans import Translator
from opencc import OpenCC
Word 文件處理
from docx import Document
將長字串分割成多個小段的函式。適用於將大段文字分割成較小的部分,避免一次翻譯過多字元而導致翻譯工具失敗。
def chunk_text(text, chunk_size=3000):
翻譯單段文字的函式。支援多次重試與簡繁體轉換,保證翻譯結果的準確性和穩定性。
def translate_chunk(chunk, translator, opencc, max_retry=3, wait_secs=2):
提取 PDF 文件文字內容的函式。通過 pdfplumber 從 PDF 文件的每一頁提取文字,並將其合併為一個完整的文本。
def read_pdf_text(pdf_path):
將翻譯後的文字內容保存為 Word 文件的函式。每一行文字將作為 Word 文件中的一段。
def save_translated_to_word(translated_text, output_word_path):
完整的 PDF 翻譯至 Word 文件的流程。包含提取文本、分段翻譯、簡繁轉換,以及生成翻譯後的 Word 文件。
def translate_pdf_to_word(pdf_path, output_word_path, translator, opencc):
主程式入口。設定資料夾路徑,初始化翻譯工具,並遍歷資料夾內的所有 PDF 文件,執行翻譯與保存流程。
def main():
import os
import time
import pdfplumber
from googletrans import Translator
from opencc import OpenCC
from docx import Document
def chunk_text(text, chunk_size=3000):
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunks.append(text[start:end])
start = end
return chunks
def translate_chunk(chunk, translator, opencc, max_retry=3, wait_secs=2):
for attempt in range(max_retry):
try:
result = translator.translate(chunk, src='en', dest='zh-TW')
translated_text = result.text
translated_text = opencc.convert(translated_text)
return translated_text
except Exception as e:
print(f"翻譯失敗: {e}")
if attempt < max_retry - 1:
print(f"稍等 {wait_secs} 秒後重試...")
time.sleep(wait_secs)
else:
print("多次嘗試仍失敗,保留原文。")
return chunk
def read_pdf_text(pdf_path):
all_text_list = []
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
page_text = page.extract_text()
if page_text:
all_text_list.append(page_text)
entire_text = "\n".join(all_text_list)
return entire_text
def save_translated_to_word(translated_text, output_word_path):
doc = Document()
for line in translated_text.split("\n"):
doc.add_paragraph(line)
doc.save(output_word_path)
def translate_pdf_to_word(pdf_path, output_word_path, translator, opencc):
entire_text = read_pdf_text(pdf_path)
print(f"[DEBUG] 原文長度: {len(entire_text)}")
text_chunks = chunk_text(entire_text, 3000)
translated_results = []
for chunk in text_chunks:
t_chunk = translate_chunk(chunk, translator, opencc)
translated_results.append(t_chunk)
final_text = "\n".join(translated_results)
print(f"[DEBUG] 翻譯後長度: {len(final_text)}")
save_translated_to_word(final_text, output_word_path)
def main():
en_pdf_folder = r"C:\Users\chenchen\Desktop\chenchen_code\pdf_file_translation\englishpdf"
cn_word_folder = r"C:\Users\chenchen\Desktop\chenchen_code\pdf_file_translation\cn"
if not os.path.exists(cn_word_folder):
os.makedirs(cn_word_folder)
translator = Translator()
opencc = OpenCC('s2t')
for filename in os.listdir(en_pdf_folder):
if filename.endswith(".pdf"):
pdf_path = os.path.join(en_pdf_folder, filename)
word_filename = os.path.splitext(filename)[0] + ".docx"
output_word_path = os.path.join(cn_word_folder, word_filename)
print(f"正在處理: {filename}")
try:
translate_pdf_to_word(pdf_path, output_word_path, translator, opencc)
print(f"翻譯完成,保存至: {output_word_path}")
except Exception as e:
print(f"處理失敗: {filename}, 錯誤: {e}")
if __name__ == "__main__":
main()
 xiangcheng
xiangcheng
