之前寫了簡單的parser,用來取得pptx中各個檔的關聯性。
現在就開始進一步發展這個parser,讓它可以把我們需要的資料從main.json中抽出。不過首先還是來看一下怎麼組織程式,以及怎樣實際進行。
目前想到的做法其實很直覺,就是不同種的資料需求,就寫一個模組來做,這個模組最初可能只是一個函數,如果更複雜的話,就多寫幾個把功能做出來。
函數的參數本來想統一,不過檔案關連性的資料,也會需要傳給個模組處理,所以實際取出資料的函數,會多使用一個參數。
另外,雖然不知道後面會不會需要,在取得各個xml檔關連性後,也根據檔案的類別(presentation, slide, slideLayout, slideMaster, theme等),比這類別下的檔案整理在一起。
整個目錄結構大致上像這樣:
Feng-Hsu-Pingteki-MacBook-Pro:node-pptx-parser fillano$ tree
.
├── LICENSE
├── README.md
├── index.js
├── lib
│ ├── presentationParser.js
│ ├── relationParser.js
│ └── typeParser.js
├── package.json
└── test
├── main.json
└── presentationTest.js
2 directories, 9 files
個別的parser放在lib目錄中,test目錄中就是測試用的檔案。
另外一個比較大的變動,原本他是一個簡單的console工具,但是因為後面會給node-pptx使用,所以把它改成模組,但是這樣沒辦法直接執行...後面會改成類似TDD的方式來開發,因為這樣才能針對資料做測試及開發。
由於資料已經全部轉成json,所以處理很簡單,就依照樹狀結構把我們要的資料抓出來,然後放到最後想使用的物件結構中。
程式本身其實很簡單,就是一路取值取下去...例如取ppt/presentation.xml資料的程式,對我們來說需要的資料主要是:
程式長這樣:
module.exports = presentationParser;
function presentationParser(entries, pptx, relations) {
let presentation = {};
let root = pptx['ppt/presentation.xml']['p:presentation'];
presentation['slideMasterIdList'] = [];
root['p:sldMasterIdLst'][0]['p:sldMasterId'].forEach(a => {
let rid = a.$['r:id'];
let target = relations['ppt/presentation.xml'][rid];
presentation['slideMasterIdList'].push({id: a.$.id, rid: rid, target: target});
});
presentation['slideIdList'] = [];
root['p:sldIdLst'][0]['p:sldId'].forEach(b => {
let rid = b.$['r:id'];
let target = relations['ppt/presentation.xml'][rid];
presentation['slideIdList'].push({id: b.$.id, rid: rid, target: target});
});
presentation['slideSize'] = {
type: root['p:sldSz'][0].$.type,
cx: root['p:sldSz'][0].$.cx,
cy: root['p:sldSz'][0].$.cy
};
let ts = root['p:defaultTextStyle'][0];
presentation['defaultTextStyle'] = {};
presentation['defaultTextStyle']['defaultParagraphStyle'] = {};
presentation['defaultTextStyle']['defaultParagraphStyle']['defaultRunProperty'] = {
lang: ts['a:defPPr'][0]['a:defRPr'][0].$.lang
};
for(let i=1; i<10; i++) {
presentation['defaultTextStyle']['level' + i + 'ParagraphProperty'] = {
marL: ts['a:lvl' + i + 'pPr'][0].$.marL,
algn: ts['a:lvl' + i + 'pPr'][0].$.algn,
defTabSz: ts['a:lvl' + i + 'pPr'][0].$.defTabSz,
rtl: ts['a:lvl' + i + 'pPr'][0].$.rtl,
eaLnBrk: ts['a:lvl' + i + 'pPr'][0].$.eaLnBrk,
latinLnBrk: ts['a:lvl' + i + 'pPr'][0].$.latinLnBrk,
hangingPunct: ts['a:lvl' + i + 'pPr'][0].$.hangingPunct
};
let drp = ts['a:lvl' + i + 'pPr'][0]['a:defRPr'][0];
presentation['defaultTextStyle']['level' + i + 'ParagraphProperty'].defaultRunProperty = {
size: drp.$.sz,
kern: drp.$.kern,
color: drp['a:solidFill'][0]['a:schemeClr'][0].$.val
};
}
return presentation;
}
基本上就是很dirty...
測試就只是幾個工具的組合:
測試透過Mocha來架構及驅動,使用Chai來做assertion,另外透過Istanbul同時檢測覆蓋率。
由於目前只做了取出ppt/presentation.xml的資料的部份,所以測試還很簡單:
const assert = require('chai').assert;
const fs = require('fs');
const parser = require('../index');
describe('ppt/presentation.xml parsing test', () => {
let data = '';
before(done => {
fs.readFile('./test/main.json', {encoding: 'utf-8'}, (err, d) => {
if(!!err) throw err;
data = d;
done();
});
});
describe('test slide size setting', () => {
it('type, cx, cy should matched.', done => {
let pptx = parser(data);
assert.equal(pptx.presentation.slideSize.type, 'screen4x3');
assert.equal(pptx.presentation.slideSize.cx, '9144000');
assert.equal(pptx.presentation.slideSize.cy, '6858000');
done();
});
});
describe('test slideMasterIdList', () => {
it('only one slideMaster in the list.', done => {
let pptx = parser(data);
assert.lengthOf(pptx.presentation.slideMasterIdList, 1);
done();
});
it('id, rid, target should matched.', done => {
let pptx = parser(data);
assert.equal(pptx.presentation.slideMasterIdList[0].id, '2147483660');
assert.equal(pptx.presentation.slideMasterIdList[0].rid, 'rId1');
assert.equal(pptx.presentation.slideMasterIdList[0].target, 'ppt/slideMasters/slideMaster1.xml');
done();
});
});
describe('test slideIdList', () => {
it('four slides in the list.', done => {
let pptx = parser(data);
assert.lengthOf(pptx.presentation.slideIdList, 4);
done();
});
it('id, rid target should matched for each.', done => {
let pptx = parser(data);
let slide1 = pptx.presentation.slideIdList[0];
assert.equal(slide1.id, '256');
assert.equal(slide1.rid, 'rId2');
assert.equal(slide1.target, 'ppt/slides/slide1.xml');
let slide2 = pptx.presentation.slideIdList[1];
assert.equal(slide2.id, '257');
assert.equal(slide2.rid, 'rId3');
assert.equal(slide2.target, 'ppt/slides/slide2.xml');
let slide3 = pptx.presentation.slideIdList[2];
assert.equal(slide3.id, '258');
assert.equal(slide3.rid, 'rId4');
assert.equal(slide3.target, 'ppt/slides/slide3.xml');
let slide4 = pptx.presentation.slideIdList[3];
assert.equal(slide4.id, '259');
assert.equal(slide4.rid, 'rId5');
assert.equal(slide4.target, 'ppt/slides/slide4.xml');
done();
});
});
});
不過defaultTextStyle又臭又長,所以測試還沒寫XD(主要是定義Level1~Level9的列表文字樣式...大部分雷同)
測試結果像這樣:
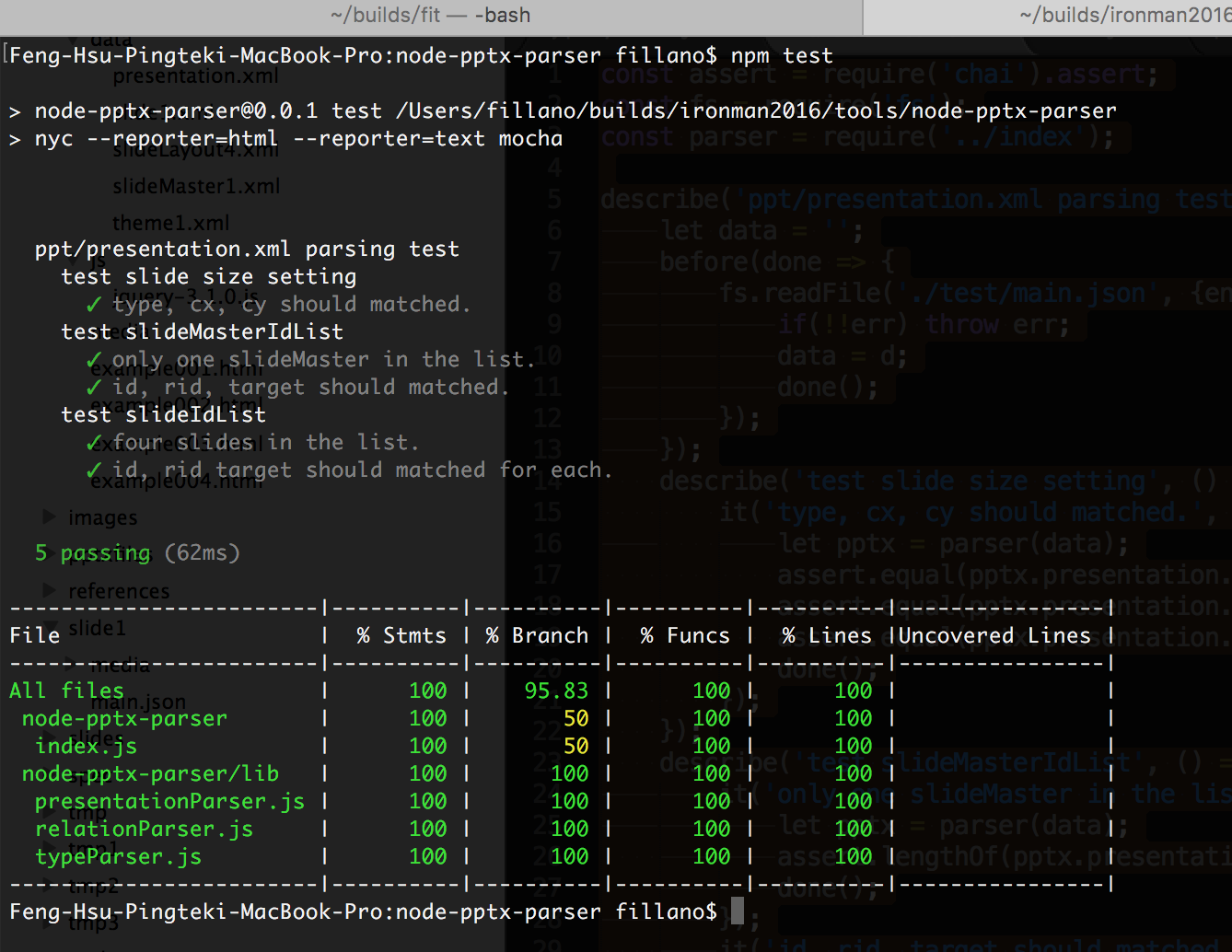
Istanbul會產出漂亮的覆蓋率報告,可以看看上面的index.js覆蓋率為什麼只有50%:
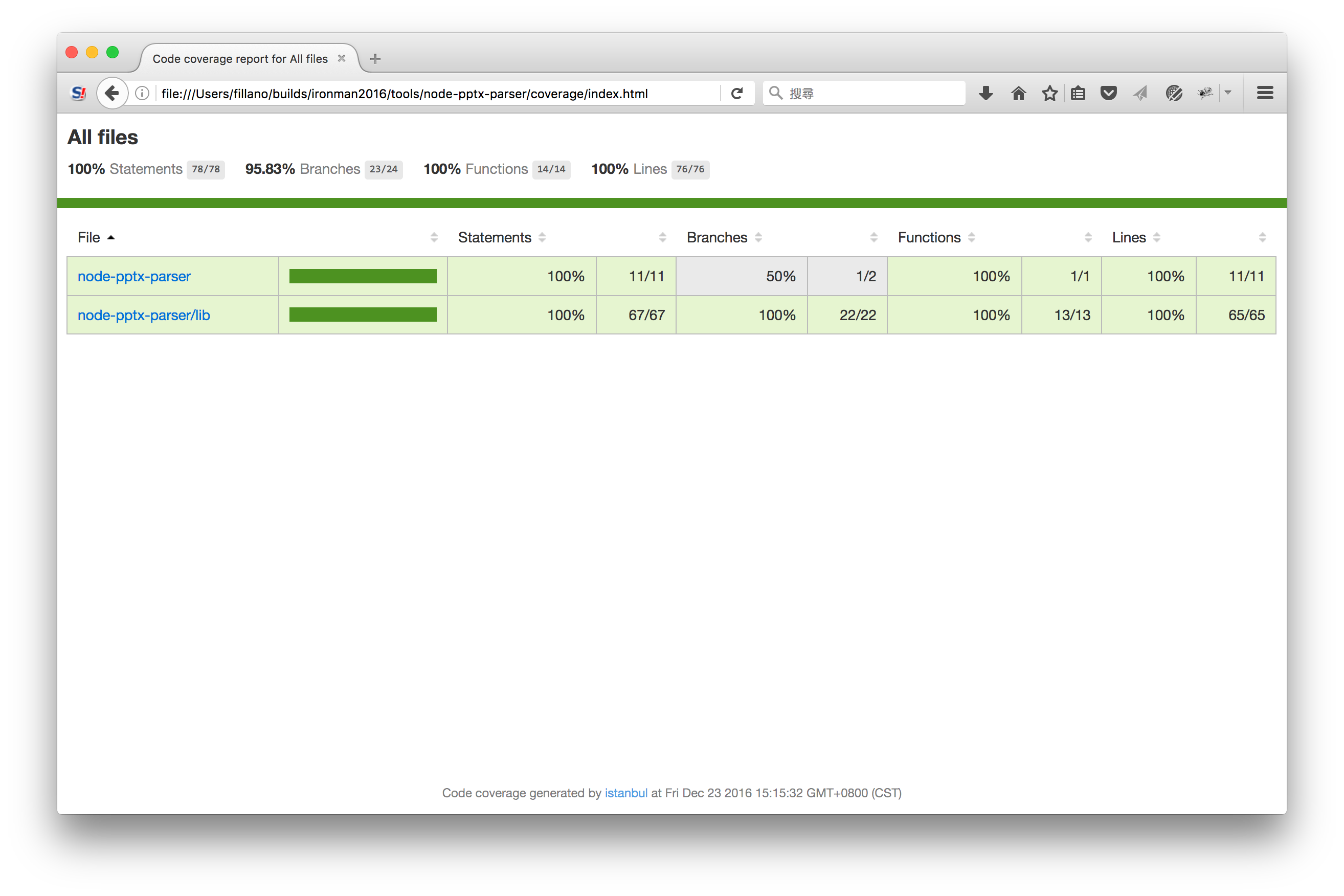
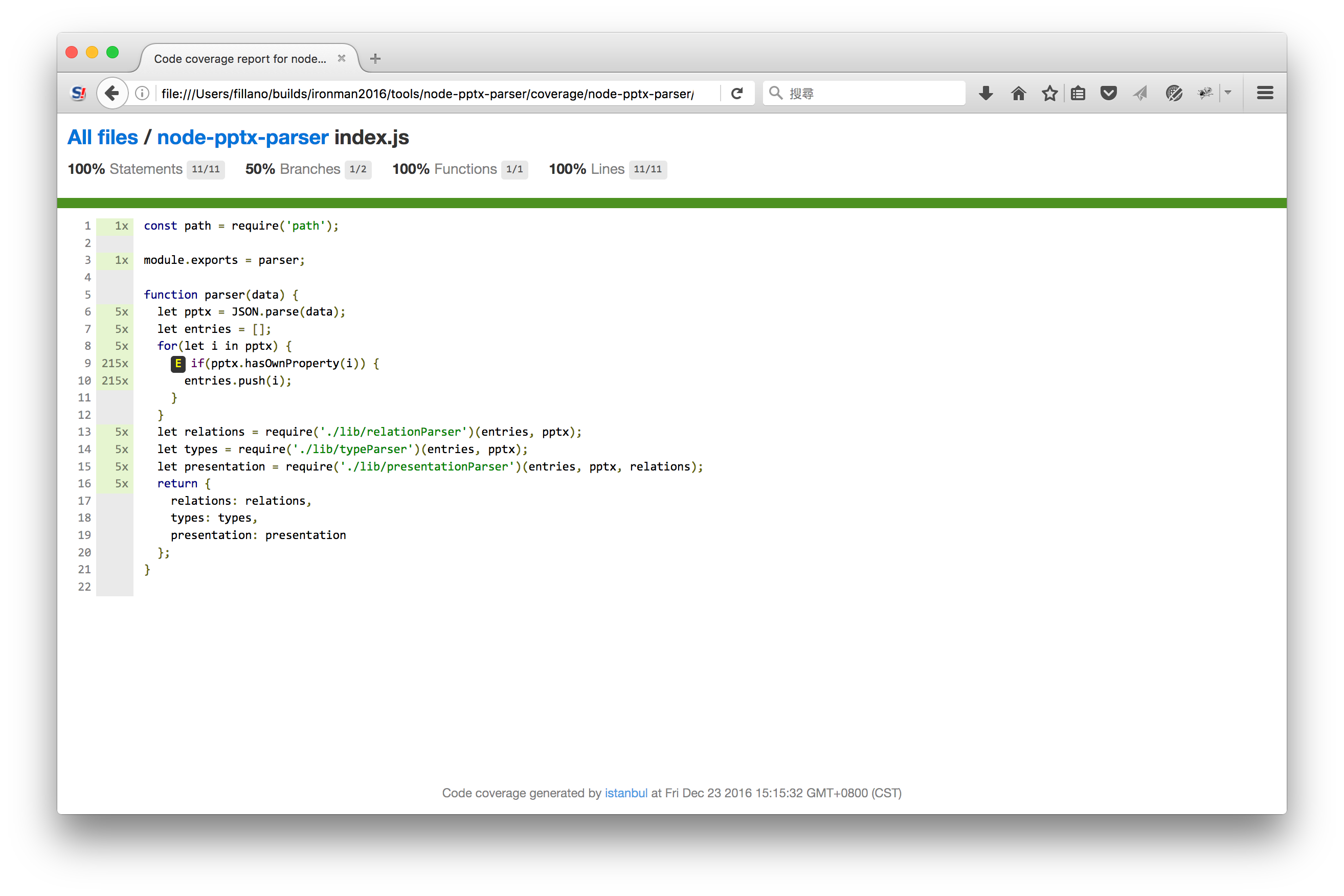
...嗯,原來index.js只有一個Branch Point...
明天週末,先來挑戰轉場特效好了。不過...ECMA-376裡面定義了大約21種轉場特效,只能挑幾種來做。(一天做一種其實就撐完鐵人賽了XD)
如果對程式有興趣,可以到github看看:



 iThome鐵人賽
iThome鐵人賽