Spark Streaming裡面的API操作主要分為兩大類:
Stateless StreamingStateFul StreamingStateless的意思可以想像成Spark每次關注的目標就是這一個批次之中的資料,之前批次的勒?不理他,過了就過了,而StateFul則會關注其他批次之中的資料。今天先說說我認為比較單純的Stateless吧:
想看比較多的資料,用上一篇的nc會累死XD,所以今天會用到OpenSource的資料檔與小腳本。
可以到GitHub Link或是我的Google Drive Link去下載。
今天需要用到的是:
orders.txt:測試文字檔案(股票交易紀錄)。splitAndSend:將orders檔案拆成小檔,然後每過幾秒丟到HDFS某個指定目錄的小程式,模擬串流慢慢流進HDFS的現象。splitAndSend將檔案傳入:joechh@joechh:~$ hdfs hdfs -mkdir sparkDir
joechh@joechh:~$ hdfs dfs -ls
Found 2 items
drwxr-xr-x - joechh supergroup 0 2017-01-05 01:14 sparkDir
-rw-r--r-- 1 joechh supergroup 1366 2017-01-03 11:21 testfile
orders.txt與splitAndSend放在兩個同一個資料夾內,然後將splitAndSend.sh改個權限比較好用:$ chmod 775 splitAndSend.sh
splitAndSend.sh,後面跟目標HDFS目錄(範例中用sparkDir)./splitAndSend.sh sparkDir
4.會開始將order切成小檔案跟上傳HDFS,檢查看看HDFS的sparkDir吧:
joechh@joechh:~$ hdfs dfs -ls sparkDir
Found 25 items
`-rw-r--r-- 1 joechh supergroup 437626 2017-01-05 04:13 sparkDir/ordersaa.ordtmp`
-rw-r--r-- 1 joechh supergroup 448647 2017-01-05 04:13 sparkDir/ordersab.ordtmp
-rw-r--r-- 1 joechh supergroup 448605 2017-01-05 04:13 sparkDir/ordersac.ordtmp
-rw-r--r-- 1 joechh supergroup 448794 2017-01-05 04:13 sparkDir/ordersad.ordtmp
-rw-r--r-- 1 joechh supergroup 448624 2017-01-05 04:13 sparkDir/ordersae.ordtmp
....
另外,隨時要中斷splitAndSend.sh可以用CTRL+C中斷(只想上傳一些就中斷時好用),但再次執行時會說HDFS已經有相同資料了,
joechh@joechh:~/Scala/sparkIronMan/Spark/src/main/resources/day20$ ./splitAndSend.sh sparkDir
copyFromLocal: `sparkDir/ordersaa.ordtmp': File exists
copyFromLocal: `sparkDir/ordersab.ordtmp': File exists
copyFromLocal: `sparkDir/ordersac.ordtmp': File exists
可以用HDFS指令把HDFS上的資料清掉,以便下次玩耍:
hdfs dfs -rm sparkDir/*.ordtmp
設定好了,看一下orders.txt資料到底是啥吧:
$head -n 10 orders.txt
2016-03-22 20:25:28,1,80,EPE,710,51.00,B
2016-03-22 20:25:28,2,70,NFLX,158,8.00,B
2016-03-22 20:25:28,3,53,VALE,284,5.00,B
2016-03-22 20:25:28,4,14,SRPT,183,34.00,B
2016-03-22 20:25:28,5,62,BP,241,36.00,S
2016-03-22 20:25:28,6,52,MNKD,296,28.00,S
2016-03-22 20:25:28,7,65,CHK,791,60.00,B
2016-03-22 20:25:28,8,51,Z,620,21.00,B
2016-03-22 20:25:28,9,98,CHK,533,38.00,S
2016-03-22 20:25:28,10,97,AU,456,37.00,B
Schema依序為:
計算每秒買/賣的次數,只看買/賣
OK,拆解問題一下吧
case class Order(time: java.sql.Timestamp, orderId: Long, clientId: Long, symbol: String, amount: Int, price: Double, buy: Boolean)
TimeStamp格式來玩玩,或是要用Java8的時間類別也OKBoolean
2.有了Order物件之後就要把吃進來的的每筆event切開,所以會用到split+
3 切開之後放到某個陣列變數中,然後讀取對應的欄位塞入 new Order建立物件
4.所以現在的StreamingRDD上面每個元素都變成類似Order物件了,再來個WordCount連續技吧XD
5.這次的Word只有兩個,不是買就是賣的boolean值~也就是boolean也能夠當reduceByKey的Key唷
那Code到底長啥樣子勒:
package SparkIronMan
/**
* Created by joechh on 2016/12/6.
*/
import java.sql.Timestamp
import java.text.SimpleDateFormat
import org.apache.spark._
import org.apache.spark.streaming._
object Day20_FileStreaming extends App {
val conf = new SparkConf().setMaster("local[4]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1)) ①
val fileStream = ssc.textFileStream("hdfs://localhost:9000/user/joechh/sparkDir") ②
val orders = fileStream.flatMap(line => { ③
val dateFormat = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss") ④
val words = line.split(",") ⑤
try {
assert(words(6) == "B" || words(6) == "S") ⑥
List(Order(new Timestamp(dateFormat.parse(words(0)).getTime), ⑦
words(1).toLong,
words(2).toLong,
words(3),
words(4).toInt,
words(5).toDouble,
words(6) == "B"
))
}
catch { ⑧
case e: Throwable => println("wrong line format(" + e + "):" + line)
List()
}
})
val numPerType = orders.map(o => (o.buy, 1L)).reduceByKey(_ + _) ⑨
numPerType.print()
ssc.start()
ssc.awaitTermination()
}
case class Order(time: java.sql.Timestamp, orderId: Long, clientId: Long,
symbol: String, amount: Int, price: Double, buy: Boolean)
好好看看這段程式碼吧:
①建立ssc,批次為1秒
②透過ssc建立textFileStream,來源為HDFS的sparkDir目錄
③⑤ flatMap跟split搭配的,拆解後每行Array處理後會變成一個List,處理後再攤平。
④建立一個SimpleDateFormat解析TimeStamp用
⑥示範Assert寫法,若不是這兩者則噴Execption
⑦建立Order物件,包成List
⑧若噴Exception,則回傳空List
⑨處理完後就成為DStream[Order],再搭配mapReduce。先將Order物件轉成pairRDD(買/賣,1),然後reduceByKey對值的部份疊加即可得buy/sell的個別次數。
執行結果: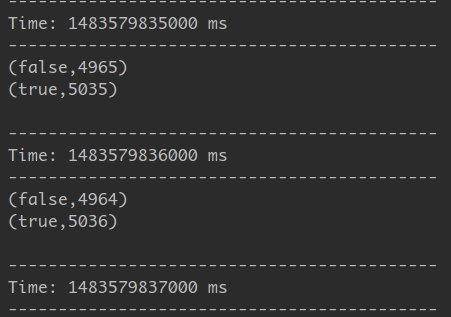
若感覺有幾秒沒有資料,那是因為splitAndSend.sh預設會三秒執行一次HDFS的put指令,可以把sleep 3降低即可
如果想要把結果寫回HDFS,不想要print出來就沒了該怎麼做?
把numPerType.print()換成如下
numPerType.repartition(1).saveAsTextFiles("hdfs://localhost:9000/user/joechh/sparkDir/output/", "txt")
動作很簡單,saveAsTextFiles寫回HDFS,比較特別的是因為我們知道輸出很小,所以我們將對partition執行repartition降為1,(還記得預設partition的數量怎麼來的嗎?沒設定就是核心數啦!)


