Hadoop 是一個集儲存、運算、資源管理於一身的分散式 Big Data 處理平臺,分別為三大模組提供服務:
HDFS為 Hadoop Distributed File System 的縮寫,分散式檔案系統。
大家可以想像一下,有一個超大檔案容量為1TB,該台機器的硬碟大小只剩下500GB,該如何把這檔案儲存起來?
如果只是單純儲存,以上的方法的確是選項之一,但若主機的硬碟已經無法再擴充時,這時候就頭大了!
一般而言現行的儲存架構會考量故碟故障發生時,降低損害資料的完整性,通常會使用磁碟陣列 (RAID),但是在容量擴充上就受到限制。
使用HDFS就可以輕易的解決上面的問題。HDFS是個可擴充(scalable)且可靠(reliable)的分散式檔案系統,由一台NameNode與至少一台的DataNode所組成。
儲存檔案到HDFS前,檔案會被拆開成數等分小區塊,稱之block,並且會將同一個block複製成數等分(replication, 預設值是3份)再將這些block分散儲存到各個DataNode,同時會產生一份清單,記載著這份檔案所屬的block與散落在哪幾台DataNode,這份清單會被記錄在NameNode上,而相同的block不會同時存在於同一個DataNode上。當某個Hadoop client需要讀取這個檔案時,會先跟NameNode發出請求,NameNode會根據這份清單回覆檔案的block位於哪幾台DataNode,Hadoop client再根據這份清單將各個block讀取出來,還原成一個完整個檔案。
由以上的流程可以了解NameNode與DataNode的用途:
用圖書館的藏書來比喻,如果有一種藏書機制,新進一本書要加入館藏時,會先將這本書拆成10份後再拿去影印成3份(這例子只是比喻,未必與實際案例相同,最後請注重智慧財產權),最後在館藏筆記本內紀錄這30份的內容分別放在哪些書櫃,而且相同的部分不可放在同一個書櫃上。如果要查詢某本書,就要先到館藏筆記本查詢書本的block位於哪個書櫃,載到個書櫃把block取出組成一本完整的書。
在上述的例子中,書櫃的角色等同於DataNode,館藏筆記本等同於NameNode,當某個書櫃已經無法裝任何書時,只要再新增一個書櫃就可以繼續裝書,也不用重新整理舊書櫃的書或是重新歸檔。假若不幸某個書櫃都被白蟻吃光,書本資料可以由其他的影印的副本還原成一本完整的書籍。新增書櫃就是一種可擴充性(scalable),而副本機制就是可靠性(reliable)。
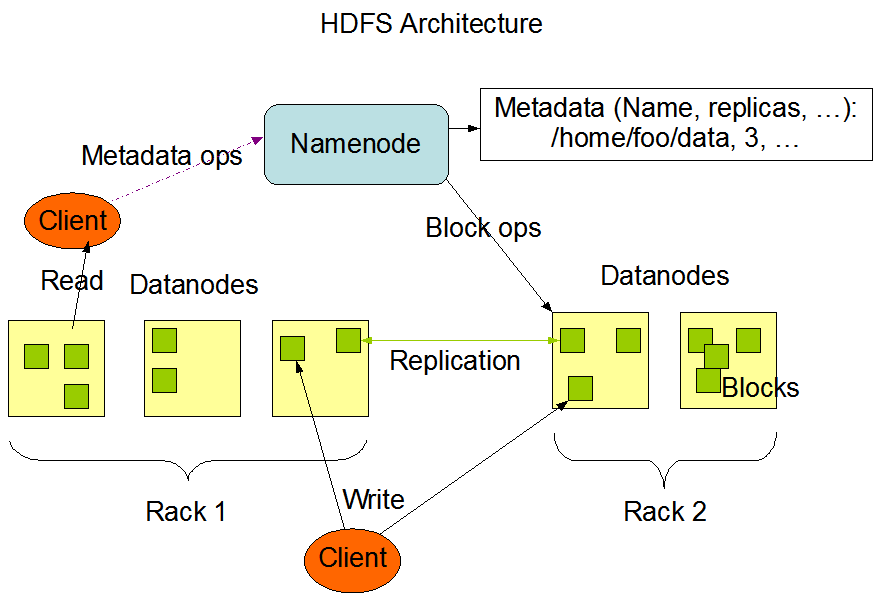
From:https://hadoop.apache.org/docs/r2.8.2/hadoop-project-dist/hadoop-hdfs/images/hdfsarchitecture.png
Yarn為 Yet Another Resource Negotiator 的縮寫,是一個資源管理系統,用來管理各種分散式運算應用程式所使用的資源,在Hadoop平台上執行MapReduce的應用程式,必須藉由Yarn監控與分配資源來確保Job可正常運作完畢。
Yarn主要由兩大service組成:
每個Hadoop叢集內具有一個ResourceManager,與一台或以上的NodeManager,數量預設會與DataNode相同。ResourceManager主要是用來管理與裁決Hadoop叢集內資源的使用權,而NodeManager是負責監控Hadoop叢集內每台機器的資源使用情況,例如memory, cpu, disk, network等,並且將資訊回報給ResourceManager。
當某個分散式運算的Job/Application 被submit至Yarn上面運行時,這個Job/Application會被拆成數個tasks並且產生一個ApplicationMaster (AM),AM會負責與ResourceManager請求需要運算的資源,這時候ResourceManager會根據NodeManager回報的消息,告知AM哪幾台機器有空閑的資源可以使用,此時這些tasks會以一種抽象的資源概念:Container 被分配到這些機器上進行運算。
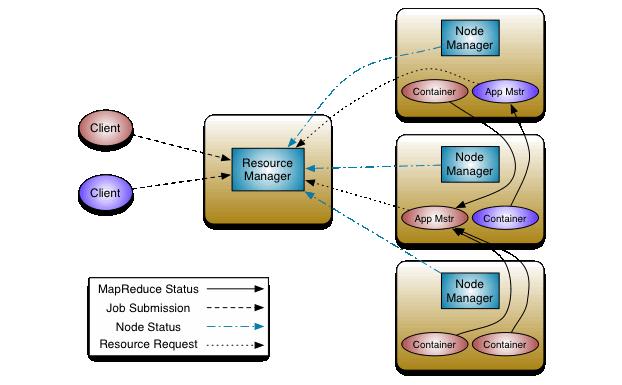
From:https://hadoop.apache.org/docs/r2.8.2/hadoop-yarn/hadoop-yarn-site/yarn_architecture.gif
MapReduce是用來在撰寫分散式計算大量資料的 framework,主要分為Map與Reduce兩個步驟。Map工作階段會把需要運算的資料拆分為多個獨立區塊(chunk),平行運算完後第一階段的運算結果儲存於檔案系統上(通常會是在HDFS內),進入Reduce階段會把Map運算的結果進行第二次的運算,運算出最後的結果。並非所有的MapReduce都會經歷過Map與Reduce這兩階段的步驟,有些Job只有Map,而有些只有Reduce,端看運算的邏輯為何。
由於MapReduce所有運算的過程都會讀寫檔案,運算效能相較之下就比較慢。運算的功能慢慢的被後起之秀Apache Spark所取代,但目前並非所有的運算情景都可使用Spark執行,故MapReduce還有其存在的價值!
介紹完了Hadoop後,下一篇接著要來介紹如何安裝Hadoop囉!
請問 Hadoop Client 指的是使用 Hadoop 的使用者嗎 ?
Hi
這文章內提到的Hadoop Client泛指透過hadoop api與hadoop cluster 進行溝通的任何端點。
原來如此! 感謝您 


