在大數據的環境下,數據當然是重要的;為了拿到數據,常得使用爬蟲技術來取得一些具規則性的數據,也才有後續的演算與延伸分析的可能性。
根據網路爬蟲-MBA智庫百科 網路爬蟲又名“網路蜘蛛”,是通過網頁的鏈接地址來尋找網頁,從網站某一個頁面開始,讀取網頁的內容,找到在網頁中的其它鏈接地址,然後通過這些鏈接地址尋找下一個網頁,這樣一直迴圈下去,直到按照某種策略把互聯網上所有的網頁都抓取完為止的技術。
對於我們撈取既定資料來說,範圍可能就在定義得更窄一點,僅取專案所需的人事時地物的資料。
舉本專案為例,公共政策網路參與平台,得先確定所需分析的資料,分別有:
所謂爬蟲的技巧,主要重點就是放在觀察,與確認尋找所需的資料有無所謂的規則。
常有站台.節點.分頁等資料各自呈現,需進行加工才能對應出正確的網址
Step1. 將游標停在所需的資料上,滑鼠右鍵按下檢查或是F12,進入開發人員工具模式。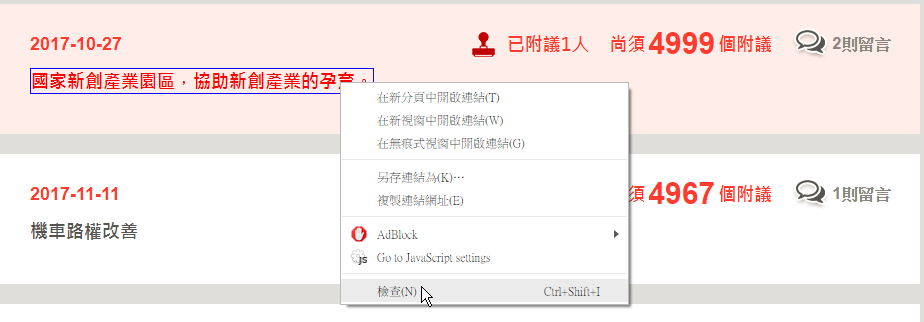
Step2.根據觀察,得出下列結果:

Step3.在該需要的欄位,滑鼠右鍵按出Copy的第三個Copy XPath選項,複製該筆XPath。
利用[Xpath Helper]工具,反覆驗證規則,再觀察。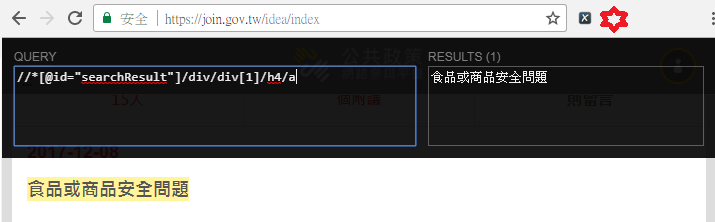
這部分作業,就是反覆的點選網頁與網址,並確認比較與先前得出的規則,有無差異,藉此確保規則的正確。
正所謂"砍樹前,得先把斧頭磨利",爬蟲作業開工之前的規劃與準備的工作,甚至還比開發爬蟲本身還要來的重要。
最終,紀錄下所需欄位的各項資料,就可著手開發程式了!
*這部分,真心覺得是整個爬蟲作業的主軸啊!!
想起了句名言 : "Do No Harm!"
寫個爬蟲容易,但不代表可以不顧及對方伺服器的負擔狀況,大肆高頻的撈取資料。如果不按規矩來,也許下一步就是被列入黑名單,成為拒絕往來戶。
觀察該網站根目錄下的robot.txt資料,確保不要有違對方管理的規則。
這部分,也是在實作過程,務必要注意的重要事項。



 iThome鐵人賽
iThome鐵人賽