如果想要享受HBase飛快的查詢速度,與避免read/write的hotspot,好的RowKey Design是很重要的。
HBase的資料是儲存於Region Server並且以RowKey當作各Region分區的界線。由於RowKey是使用字典排序,當RowKey為連續字串時會導致資料傾斜,資料過度集中於某個region server。當這狀況發生時,如果有多個使用者同時對這個table發出請求(讀/寫),這個region server會無法接受過多的請求數量而過於忙碌,這時候(讀/寫)的效能就會下降,嚴重的會導致該region server被認定已經crash,觸發HBase容錯機制而讓整個HBase叢集更為忙碌...
假設有個RowKey的結構長成這樣:
<userId>-<date>-<messageId>-<attachementId>
前面有介紹過HBase在使用RoeKey當作filter時,使用Scan查詢速度最快可以到毫秒等級。一般使用者會搭配已模糊查詢的方式來查資料,而HBase的RowKey在模糊查詢上就會有個限制,就是只支援後面字串的模糊查詢。以上面的RowKey結構為例,在查詢時就只能使用這四種方式:
1. <userId>
2. <userId>-<date>
3. <userId>-<date>-<messageId>
4. <userId>-<date>-<messageId>-<attachementId>
接下來會介紹下列四種RowKey設計方法:
如果使用Sequential/Time-serial key當作RowKey,資料會被寫入同一個region,此設計不適用於頻繁寫入的使用情境。
| 員工編號 | 簡寫 |
|---|---|
| A0001 | 0001 |
| A0002 | 0002 |
| A0003 | 0003 |
| A0004 | 0004 |
yyyy-mmdd-hhmmssss-productionId
| 訂單記錄 | 代號 |
|---|---|
| 2010-0101-11562366-prdId1 | prdId1 |
| 2010-0101-23332187-prdId2 | prdId2 |
| 2010-0103-14224378-prdId1 | prdId1 |
| ··· | ··· |
| 2010-0301-08262299-prdId5 | prdId5 |
| 2010-0302-17260101-prdId7 | prdId7 |
| ··· | ··· |
| 2010-0801-11562377-prdId5 | prdId5 |
| ··· | ··· |
俗稱的灑鹽巴。使用演算法對RowKey加工,讓資料平均散佈到各個Region Server。
以員工編號為例
| 員工編號 | 簡寫 |
|---|---|
| A0001 | 0001 |
| A0002 | 0002 |
| A0003 | 0003 |
| A0004 | 0004 |
使用String rowkey = id.reverse()方法灑完鹽巴後就會成這樣:
| 員工編號 | 簡寫 |
|---|---|
| 1000A | 0001 |
| 2000A | 0002 |
| 3000A | 0003 |
| 4000A | 0004 |
假設RowKey的格式是這樣<date>-<userId>,Swap方式就是把這兩個欄位位置交換:
<date>-<userId> -> <userId>-<date>
而Promotion意指將某個cf:qualifier的值提升至RowKey的位置,與原來的RowKey形成一個新的複合RowKey:


Random Key,顧名思義就是隨機分布的RowKey,這種設計可以降低在寫入的情境發生hotspot的狀況。
例如可以使用MD5對timestamp加密後產生一組隨機的RowKey:
byte[] rowkey = MD5(timestamp)
由下面的圖可以了解這幾種RowKey適用的情境與效能:
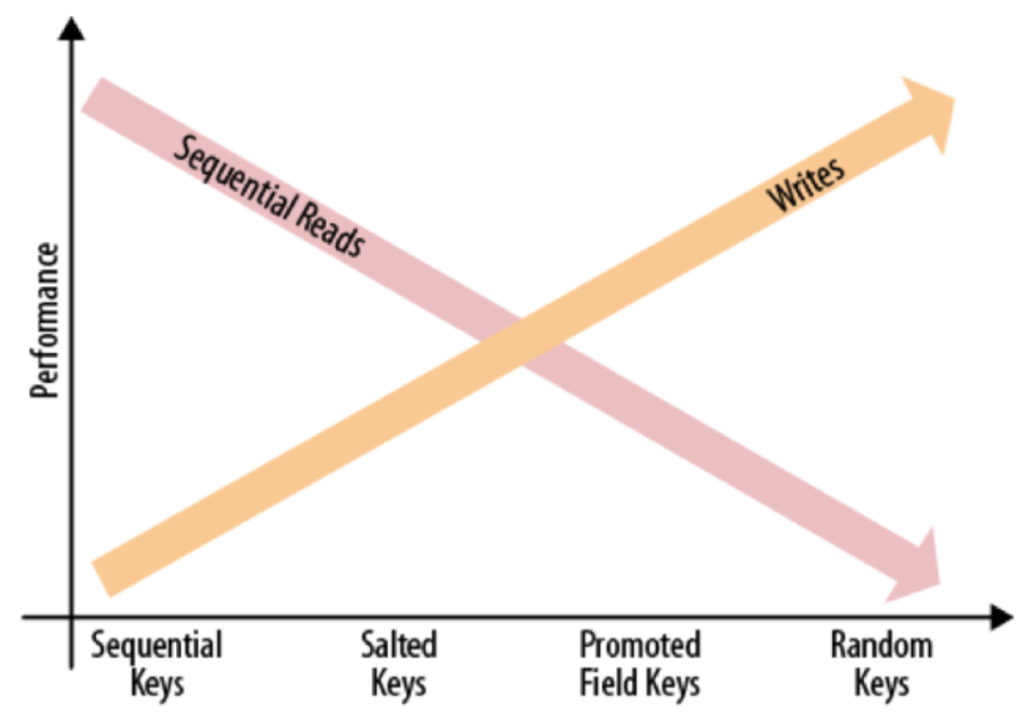
From HBase: The Definitive Guide
任何一種的RowKey設計沒有絕對好或是不好的分別,要看使用情境再決定要挑選哪種設定方式。
介紹完了RowKey設計後,接下來要來介紹HBase hello world api。


