圖片來源: https://pixabay.com/en/books-spine-colors-pastel-1099067/ 和 https://pixabay.com/en/math-blackboard-education-classroom-1547018/
上一篇([09]了解Hadoop裡的MapReduce到底是什麼?)了解了什麼是MapReduce,並且了解了怎麼用Java寫一個MapReduce的Hello World程式:WordCount。
馬上會想到的一個問題是,難道只有Java可以寫MapReduce的程式嗎?
這篇將會介紹Hadoop的Streaming服務,讓任何語言只要透過Standard Input和Standard Output就可以寫出MapReduce程式。 將會使用最熟悉的語言,.Net Core來完成這個事情。
在這篇也會介紹另外一種測試Hadoop的方式,使用Docker來測試。
這篇的範例程式碼在github:alantsai/blog-data-science-series 裡面的 src/chapter-10-dotnet-mapreduce
同步發表於我的部落格:http://blog.alantsai.net/2017/12/data-science-series-10-hadoop-streaming-intro-use-net-core-for-MapReduce.html (部落格的格式會漂亮一些,ithome不支援html好不方便)
當一個MapReduce的程式被執行的時候,會先被切割成為一個一個的Task,然後由那台的DataNode用Java執行那個Task。
所以整個執行類似下圖,整個MapReduce都在JVM的環境下:
JVM的MapReduce
不過Hadoop考量到如果外部需要執行MapReduce要怎麼辦,因此建立了一個叫做Streaming的功能。
基本上,只要那台DataNode可以Run的起來都可以跑。
Hadoop Streaming透過Standard Input/Output/Error 3個管道 來和被Run起來的程式溝通。
MapReduce的程式只需要從Standard Input讀進來,做處理,然後在寫到Output。如果有錯誤訊息可以記錄在Error裡面。
整個概念大概是:
Hadoop Streaming
還記得整個MapReduce基本上就是在每個階段做過處理之後,會產生一個key value pair。Hadoop用tab來切割Key 和 Value。
有了這個概念之後來看實際程式,以下使用的是.Net Core的console來開發,分幾個階段:
由於是透過Standard Input/Output,因此console非常適合,所以會建立一個Mapper的.Net Core Console程式。
在Mapper的階段,內容會是一行一行讀進來,所以把讀進來的內容做文字切割, 每找到一個word,就寫到output,word是key,1是value(代表找到一筆)
會一直迴圈的讀,直到沒有任何檔案為止。如果把這個和之前java比照會發現邏輯一樣。
class Program
{
static void Main(string[] args)
{
string line;
while ((line = Console.ReadLine()) != null)
{
// 用文字切割
var words = Regex.Matches(line, @"[\w]+");
foreach (var word in words)
{
// 每一個找到的算1筆 - keyvalue用tab切割
Console.WriteLine("{0}\t1", word);
}
}
}
}
會在建立另外一個專案用來放Reducer的程式。
Reducer一樣是讀Input然後寫到output。由於這次讀到的內容是從Mapper來的,所以會先用tab做切割,key是word,value就是筆數(也都是1)。
在這邊,有建立一個words dictionary,這個是因為在Mapper階段其實沒有管word有沒有重複,反正出現就是+1。
不過在Reducer因為要加總,因此用了words dictionary作為一個暫存的空間。
最後把所有結果寫到output - 也是 key value pair,key一樣是word,不過value就是word出現的總數。
static void Main(string[] args)
{
// 用來儲存已經出現過的字 - java版本會自動處理,不過這個stream需要手動記錄
Dictionary<string, int> words = new Dictionary<string, int>();
string line;
while ((line = Console.ReadLine()) != null)
{
// 傳過來的key value用tab分割(Mapper也是用tab切割key和value)
var keyValuePair = line.Split('\t');
string word = keyValuePair[0];
int count = Convert.ToInt32(keyValuePair[1]);
// 如果已經有這個word,和字典的加總,不然就建立新的
if (words.ContainsKey(word))
{
words[word] += count;
}
else
{
words.Add(word, count);
}
}
// 把所有結果寫出來
foreach (var word in words)
{
Console.WriteLine("{0}\t{1}", word.Key, word.Value);
}
和Java的版本不同,java版本會自動幫忙把key一樣組成一個list比較好操作,但是透過streaming需要自己手動操作。
當整個程式準備好了之後,接下來就可以對這個程式做測試了。
在接下來將會用一個docker版本的hadoop做測試 - 希望透過docker方式也可以了解用docker做測試有多方便。
接下來的測試都是在powershell可以直接執行。
如果對docker不熟悉,那麼下面做不了。要跑docker基本上要Windows 10 Professional以上或者linux,並且有裝docker。
裡面用到的docker image是一個linux的container。
下面也可以直接在之前建立的Ubuntu環境裡面執行,不過需要先:
安裝.net core 2.0
跳過前面的步奏,知道後面呼叫hadoop Streaming那段即可
接下來的指令操作都是在從github clone下來的專案裡面src\chapter-10-dotnet-mapreduce的資料夾下面執行。
完整的指令是:
git clone https://github.com/alantsai/blog-data-science-series.git
cd .\blog-data-science-series\src\chapter-10-dotnet-mapreduce
在powershell執行指令:dotnet publish -o ${pwd}\dotnetmapreduce .\DotNetMapReduceWordCount\DotNetMapReduceWordCount.sln
把hadoop用docker compose啟動
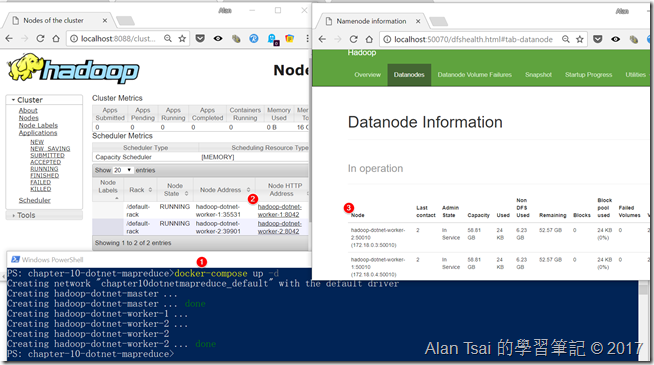
使用指令把hadoop啟動:docker-compose up -d。 會看到:
執行完有1個master 2個worker啟動
在YARN的web節點看到有兩個Node
在DataNode看到有兩個節點
可以看到啟動成功並且有兩個節點
把.Net core程式複製到master的hadoop節點裡面
把剛剛發佈出來的.Net core程式複製到master裡面,並且進入到master裡面的bash並且可以看到有copy進去的內容
docker cp dotnetmapreduce hadoop-dotnet-master:/dotnetmapreduce
docker exec -it hadoop-dotnet-master bash
ls
ls /dotnetmapreduce
進入到master的bash並且檢查copy是否成功
把要計算的檔案放到hadoop的HDFS
透過下面指令把檔案放到hadoop的HDFS的input資料夾並且檢查:
hadoop fs -mkdir -p /input
hadoop fs -copyFromLocal /dotnetmapreduce/jane_austen.txt /input
hadoop fs -ls /input
複製檔案到HDFS
用hadoop Streaming執行net core mapreduce
用hadoop的streaming執行:
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.7.2.jar \
-files "/dotnetmapreduce" \
-mapper "dotnet dotnetmapreduce/DotNetMapReduceWordCount.Mapper.dll" \
-reducer "dotnet dotnetmapreduce/DotNetMapReduceWordCount.Reducer.dll" \
-input /input/* -output /output
和之前執行map reduce的log一樣
執行完了之後,可以看到計算的每個字出現次數
hadoop fs -ls /output
hadoop fs -cat /output/part-00000
執行結果
會注意到這邊的結果和java版本有點不同,因為判斷字的邏輯不同導致。
如果docker不需要了,可以用docker-compose down把整個hadoop關掉。
在這篇介紹了透過Hadoop Streaming達到在hadoop用.Net core 2.0的console程式做MapReduce如何。
這篇也改成使用docker來做hadoop測試而不是用一直以來建立的VM。用docker和VM比較會發現到docker其實做這種事情非常方便,如果對docker不熟悉,可以考慮花點時間做些學習(之後我的部落格也會有個系列介紹docker使用,有興趣的話請持續關注)。
在這個系列的後面,之前建立的VM還會用到 - 用來和R做結合。所以如果對後面操作有興趣,VM還是先保留。
在這個系列的Hadoop介紹也到了一個尾聲,在下一篇將會對目前hadoop有介紹的部分做一個總結,介紹hadoop的ecosystem,和還有什麼部分是應該繼續關注下去。
工商服務
今年的團隊機制不知不覺就集合了10位隊(坑)友 - 大家幫忙多多關注別不小心我們就gg了 XD
** 一群技術愛好者與一名物理治療師的故事 提醒著我們 千萬不要放棄治療 **
沉浸於.Net世界的後端工程師,樂於分享,現任台中Study4成員之一。除了程式以外,就愛看小說。
歡迎有任何問題或者建議都可以告訴我,可以再以下找到我:
部落格:Alan Tsai的學習筆記
我的Linkedin
我的粉絲頁
我的github
我的Slideshare
我的Twitter