先說明一下,為什麼突然跳到安裝函式庫這個單元呢?
當然我們要開始進入真正的寫程式的階段了,前面的介紹只是介紹了最簡單的程式語法與運算的介紹
不過這樣會覺得寫程式非常的無聊,所以我建議想學程式的人就直接找個題目方向來練習吧
如果你要往網路爬蟲的方向去做學習,你可以選擇到外面買本書來專研,但是真正想當上程式設計師,你一定要學會
看得懂文件.
因為等到台灣翻譯成繁體中文書,你早就已經跟不上這個世界了,你可以選擇簡體書,中國那有很多不錯的書籍
可以參閱.但是總而言之你要學會看文件
我先介紹一個簡單的網站,(https://www.crummy.com/software/BeautifulSoup/bs4/doc/ )此網址內是BeautifulSoup函式庫的文件.
沒錯,裡面全部都是英文,當然也有人已經將全部內容翻譯成中文了,但是我要洗腦你,要學著去看英文學習
這個函式庫主要是讓我們來解析HTML原始碼,讓我們取得HTML中元素中我們要的數據.
但是這樣並不能完成一個爬蟲程式的
1.了解什麼是HTML
2.學會HTTP傳輸協定如何運作原理(如果你拿這個做專題,這是教授必考題)
3.學會工具來對你要的數據!做分析
4.學會Python的流程控制與決策判斷(挑出我們要的數據)
上述所說的只是我們的第一步
為什麼我只說是我們第一部呢?
請去思考,你拿到了數據你要怎麼處理他們?
你可以將這些蒐集來的數據做資料分析(Data Analysis),最後實現數據視覺化呈現在圖片,網頁等頁面上
當然還可以做其他的事情.
首先我們要學如何去安裝第三方的函式庫
上方選單點選Menu->展開Project:PycharmProjects->Project Interpreter
如下圖: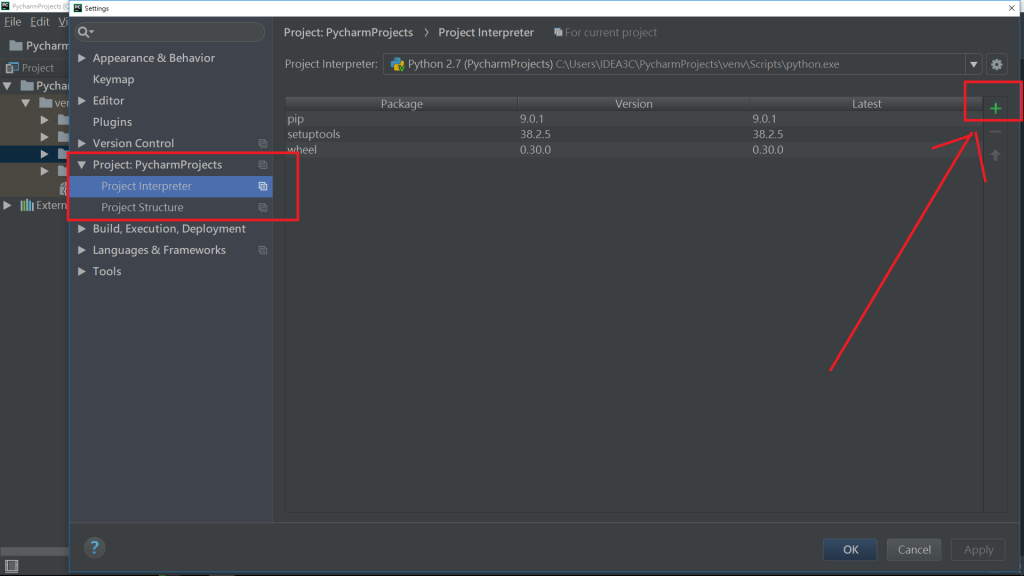
進到這個頁面點擊右邊的綠色+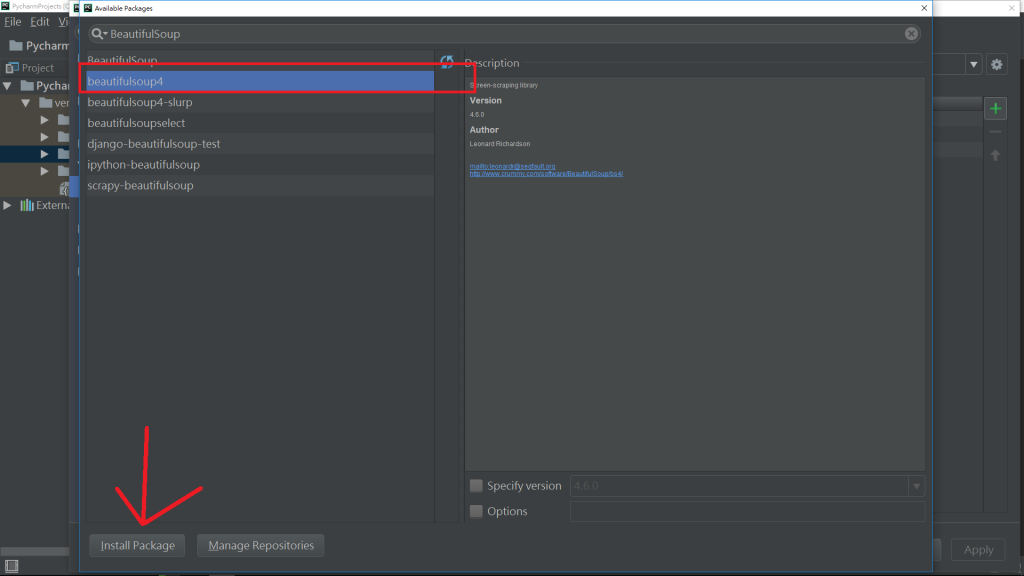
搜尋BeautifulSoup4,點擊Install Package
顯示下圖,即安裝成功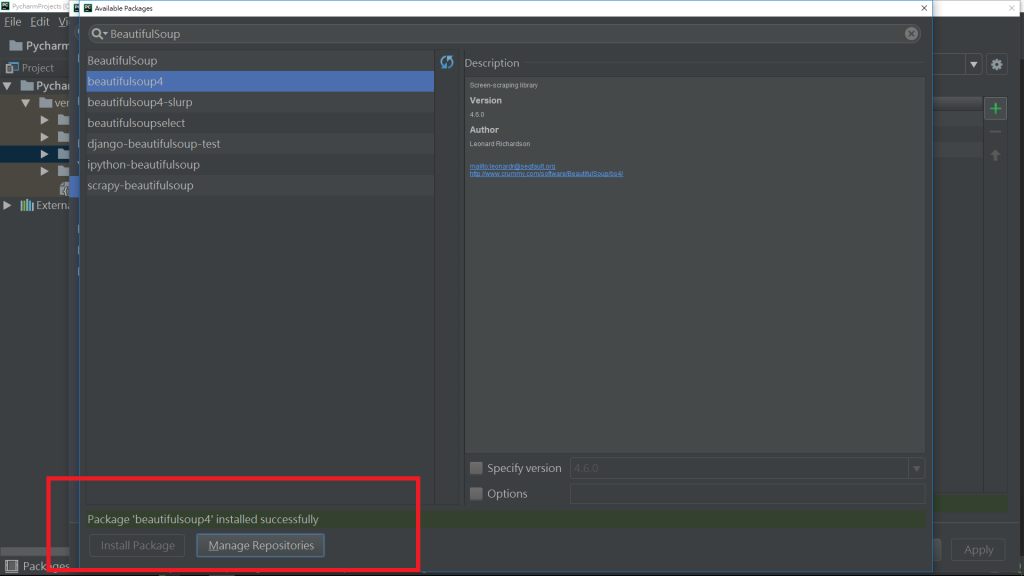
測試是否能引入此函式庫
如下圖: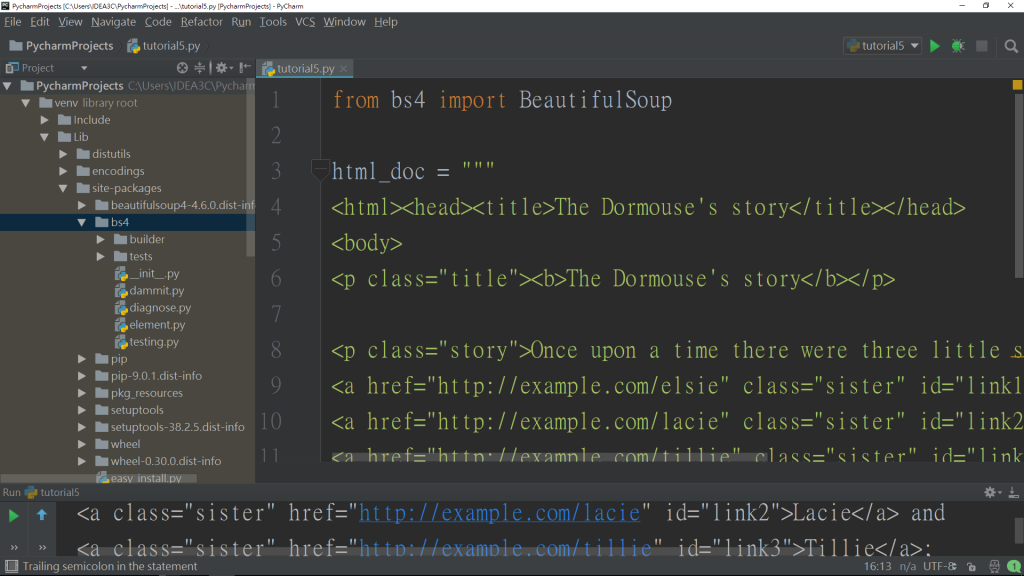
能正常執行,代表你已經成功安裝了!
當然不可能只靠這個函式庫就能完成!
先思考,BeautifulSoup在做什麼?
以此範例作為安裝一個函式庫,當然我們不可能只靠這個函式庫就能完成爬蟲程式,下一章將介紹
HTML是什麼



 iThome鐵人賽
iThome鐵人賽