嗨啊!大家好!這禮拜有點忙,所以在星期日的尾巴才有時間PO出這篇文,絕對不是因為我偷懶想晃掉這個禮拜XD,那一樣,說好的每五篇就一個Hard的題目(誰跟你說好XD),這禮拜也輪到了!其實這一篇解題的邏輯不難,因為之前有經歷過換座位的題目,感覺還滿類似的,所以如果卡關了可以回顧一下!他在這裡:[演算法][SQL]演算法挑戰系列(7)-Exchange Seats,好到這邊就好,打廣告不能太明顯XD,那讓我們來看看題目是什麼吧!
題目:Human Traffic of Stadium
難易度:高
題目內容:事情是這樣子,在Q市,神Q超人他建了一棟體育館。經營一陣子後,他想查詢連續三天,體育館的入場人數都大於等於100的資料,該怎麼做呢?
例如:stadium表內容:
| id | date | people |
|---|---|---|
| 1 | 2017-01-01 | 10 |
| 2 | 2017-01-02 | 109 |
| 3 | 2017-01-03 | 150 |
| 4 | 2017-01-04 | 99 |
| 5 | 2017-01-05 | 145 |
| 6 | 2017-01-06 | 1455 |
| 7 | 2017-01-07 | 199 |
| 8 | 2017-01-08 | 188 |
| 查詢結果: | ||
| id | date | people |
| ------------- | ------------- | ------------- |
| 5 | 2017-01-05 | 145 |
| 6 | 2017-01-06 | 1455 |
| 7 | 2017-01-07 | 199 |
| 8 | 2017-01-08 | 188 |
就是這樣子,不管是前後兩天,或是前一天後一天,只要連續三天都有100人以上瀏覽,就把該筆資料列出來,另外貼心小提醒,表中的id欄位會和date一樣依序編號下去,不會有跳號的情形,那以下來看一下解法吧! |
SELECT *
FROM stadium m
WHERE m.people >=100 AND
/*找出明後兩天的資料,然後條件人數大於100的資料,因為是明後兩天所以如果數量等於2才算*/
CASE WHEN (SELECT COUNT(*) _count FROM stadium d WHERE (d.id = m.id + 1 OR d.id = m.id + 2) AND d.people >= 100) = 2 THEN TRUE
/*找出明天和昨天的資料,然後條件人數大於100的資料,因為是兩天所以如果數量等於2才算*/
WHEN (SELECT COUNT(*) _count FROM stadium d WHERE (d.id = m.id + 1 OR d.id = m.id - 1) AND d.people >= 100) = 2 THEN TRUE
/*找出昨天和前天的資料,然後條件人數大於100的資料,因為是兩天所以如果數量等於2才算*/
WHEN (SELECT COUNT(*) _count FROM stadium d WHERE (d.id = m.id - 1 OR d.id = m.id - 2) AND d.people >= 100) = 2 THEN TRUE
/*如果都沒有就回傳FALSE不顯示*/
ELSE FALSE END
以上那樣解是因為id不會跳號,所以才這樣直接用加減1,2來取他附近的日期,然後會讓人覺得奇怪的地方可能是為什麼要用CASE WHEN,這部分也是我想要請教版上大大的地方,其實我一開始是寫OR去連接那三種情況的條件,就像平常一樣,但是跑出來的效率差到不行,原因也很明顯是子查詢的關係,後來就在想如果是(id='A' OR id='B')這種情況,是會判斷完兩個條件後再回傳TRUE或是判斷到id='A'就不再判斷id='B'了,想請版上大大解答一下這個疑惑。
這方面,小弟認為是都會判斷!所以為了讓成績好看一點就改成了CASE WHEN id = 'A' THEN TRUE WHEN id = 'B' THEN TRUE ELSE FALSE,讓他可以判斷到id='A'就回傳TRUE不會再跑下一個WHEN,想說這樣效能或許會好一點,那也來分享一下這次的成績: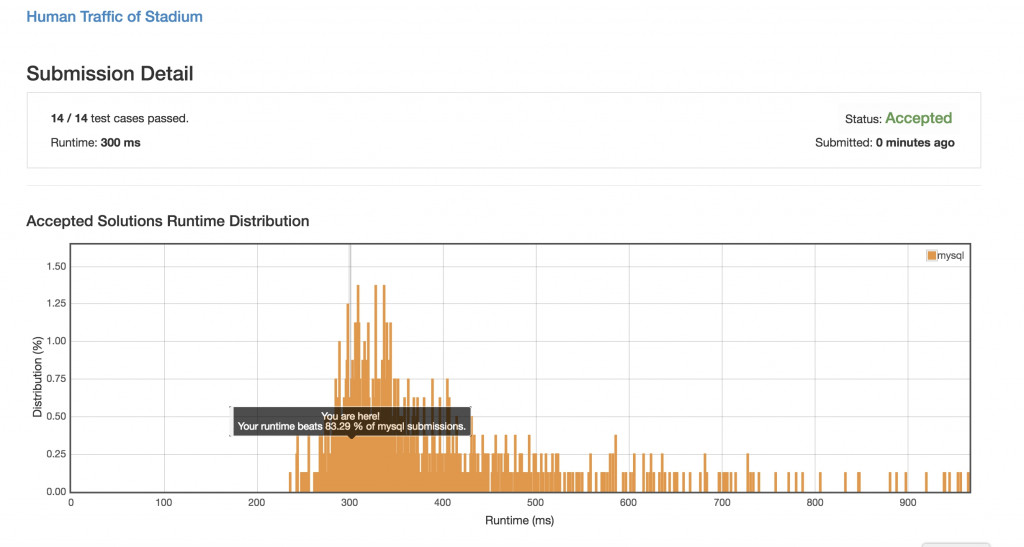
我也找了一些其他大大討論的解答,題外話我居然有榮幸看到和我一樣的解答XD,不過是OR版本的就不再分享,我們就來看看其他寫法吧:
原解答網址
/*(6)最後一步因為(4)的INNER JOIN會找出重複的資料,
所以用DISTINCT過濾掉。*/
SELECT DISTINCT c.*
FROM stadium c
INNER JOIN
(
/*(3)在這裡用MIN()來找出昨天、今天、明天中最少的人數
另外也用COUNT()來判斷說該筆資料出現的次數(最後的WHERE再說明用途)*/
SELECT a.id id, MIN(b.people) min_people, COUNT(1) units_around
FROM stadium a
INNER JOIN stadium b
/*(1)用a.id-b.id在-1到1之間去INNER JOIN找出前後1天的資料*/
ON a.id - b.id BETWEEN -1 AND 1
/*(2)把同個id做群組GROUP BY起來*/
GROUP BY a.id
) d
/*(4)比較關鍵的地方在這邊,
他在這裡用裡面查出來的資料再JOIN一次,原本資料表的資料,
這時候會找出原本的所有日期對應出的當天+前後一天的最少人數的資料,*/
ON c.id - d.id BETWEEN -1 AND 1
/*(5)因為(4)的關係,所以在這裡判斷該日期+前後的三天資料有沒有一筆大於100
第二個條件是因為(3)的COUNT(1) units_around其實就像是比較幾筆資料,
而因為題目中要連續3天大於100,所以這邊要等於3*/
WHERE d.min_people >= 100 and d.units_around = 3
上面的方法要理解起來滿困難的(對我來說啦XD),所以上面解釋的方式可能有點不清楚,尤其是第(5)步驟的地方,也是去查了以後才明白它的道理,所以如果以上解釋不清楚的話,可以再告訴我!我再想想怎麼表達會比較好,啊如果是表達錯誤的地方,也麻煩大大們提出,我會儘速修正!那以下會提供CREATE的SQL方便大家練習,啊我一直忘了說,這一次官方的解題方式也只有提供MySQL的方式,不過文章內的兩種解法在MSSQL上也不會有問題的!
Create table stadium (id int, date DATE NULL, people int)
insert into (id, date, people) values ('1', '2017-01-01', '10')
insert into (id, date, people) values ('2', '2017-01-02', '109')
insert into (id, date, people) values ('3', '2017-01-03', '150')
insert into (id, date, people) values ('4', '2017-01-04', '99')
insert into (id, date, people) values ('5', '2017-01-05', '145')
insert into (id, date, people) values ('6', '2017-01-06', '1455')
insert into (id, date, people) values ('7', '2017-01-07', '199')
insert into (id, date, people) values ('8', '2017-01-08', '188')
最後的最後,還是感謝大家的觀看!現在也不能祝大家週末愉快了(其實我也沒這麼說過XD),就祝大家新一個禮拜繼續好好加油吧!謝謝大家!
嗯@@...這篇可以玩玩XD
MSSQL
declare @Tmp table(
id int
,[date] date
,people int
)
insert into @Tmp
values(1,'2017-01-01',10)
,(2,'2017-01-02',109)
,(3,'2017-01-03',150)
,(4,'2017-01-04',99)
,(5,'2017-01-05',145)
,(6,'2017-01-06',1455)
,(7,'2017-01-07',199)
,(8,'2017-01-08',188)
select *
from @Tmp as a
where (
select min(people)
from @Tmp as b
where a.id <= b.id
and a.id between a.id and a.id + 2
) >= 100
MySQL
Create table stadium (id int, dates DATE NULL, people int);
insert into stadium(id, dates, people)
values ('1', '2017-01-01', '10')
,('2', '2017-01-02', '109')
,('3', '2017-01-03', '150')
,('4', '2017-01-04', '99')
,('5', '2017-01-05', '145')
,('6', '2017-01-06', '1455')
,('7', '2017-01-07', '199')
,('8', '2017-01-08', '188');
select *
from stadium as a
where (
select min(people)
from stadium as b
where a.id <= b.id
and a.id between a.id and a.id + 2
) >= 100
純真的人 大大,假如在只有10,109,150情況會錯誤得到109跟150只有連續兩次的值
(撇除這個,這script邏輯真簡潔,贊!)
哇!剛剛看到完全嚇一跳XD
想說這麼簡潔的程式碼居然就搞定了,
不過暐翰大大說的情況,只有連續兩筆破百的資料,的確還是會把資料撈出來,
小弟我看不太懂邏輯,不過可能是因為最後的a.id between a.id and a.id + 2會讓最後一筆資料沒有後兩筆,所以自己就是最小的,只有他自己破百就顯示,
如果不是這個原因的話別打我
暐翰
神Q超人
是可以加條件@@~過濾最後2筆
畢竟是撈三筆出來判斷~
判斷三筆資料的人數至少要超過100~
因為我看你的預期資料是有id7跟id8
若再加上一個條件就是一定就是要連續三筆@@
所以只會出現id5跟id6
select *
from @Tmp as a
where (
select min(people)
from @Tmp as b
where a.id <= b.id
and a.id between a.id and a.id + 2
having count(*) > 2
) >= 100
然後這句 ** a.id between a.id and a.id + 2 **
可能比較迷惑吧@@..
換成 ** b.id between a.id and a.id + 2 **
比較好理解@@..
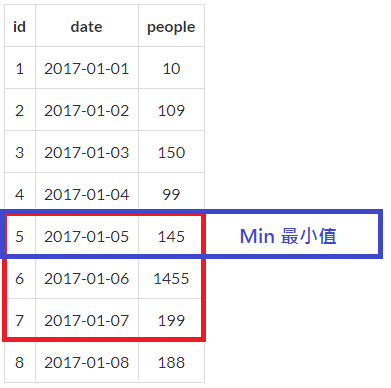
select *
from @Tmp as a
where (
select min(145)
from @Tmp as b
where 5 <= (5,6,7)
and (5,6,7) between 5 and 7
having count(*) > 2
) >= 100
關於這點可能是我解釋得不夠清楚,造成大大誤會
其實上面的例子而言,id7和8是應該顯示沒錯,
因為以id7來說,雖然他是倒數第二筆,但是他昨天(id6)和隔天(id8)都有破百人數,所以有達成連三天破百人要顯示出來的條件,
另外就id8而言,雖然他是最後一筆,但他昨天(id7)及前天(id6)人數也有破百,所以也是要顯示的資料之一。
而暐翰大大提到的以下資料:
declare @Tmp table(
id int
,[date] date
,people int
)
insert into @Tmp
values(1,'2017-01-01',10)
,(2,'2017-01-02',109)
,(3,'2017-01-03',150)
意思是因為不論是id1、id2、id3都沒有達成連續三天破百人數的條件,但大大修改前的SQL會把沒符合條件的id2和id3查詢出來,但修改後的SQL又會把一開始提供的資料中過濾掉最後兩筆符合的id7和id8。
因為他要判斷連續三天有三種狀況,以下面id6為例,需要判斷紅色、藍色、和綠色都符合連續三筆: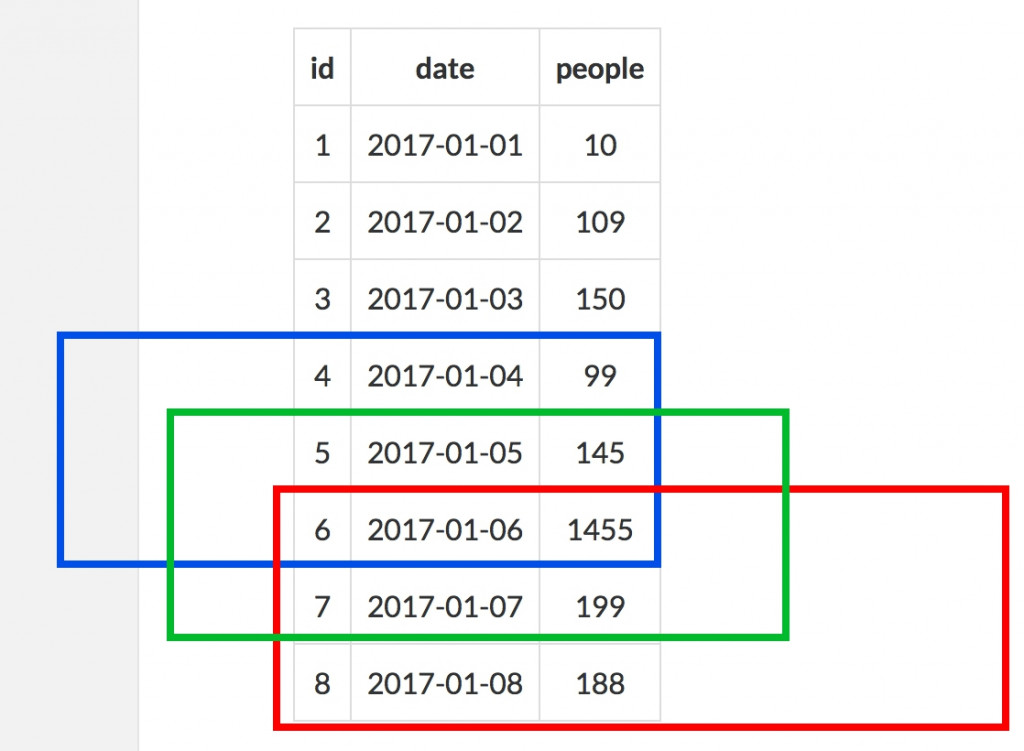
造成大大的困擾真的很抱歉!
呵呵~~
用一個特別的方式來做
select T1.*
from stadium T1,(select @strC := (select CONCAT(GROUP_CONCAT(id) ,',')
from stadium
where people >= 100)) T2
where people >= 100
and (
@strC REGEXP concat(
CONCAT(id-2,',',id-1,',',id,',')
,'|',CONCAT(id-1,',',id,',',id+1,',')
,'|',CONCAT(id,',',id+1,',',id+2,',')
)
) ;
1.先把100人數以上的資料以字串變數(使用GROUP_CONCAT把每個id都以,相加方便regex like)保存起來(@strC)
2.用regex like |(or)方式,找出連續三次的資料
3.只有以下三種情況都有資料那麼是連續三次的資料id-2,id-1,id 或是 id-1,id,id+1 或是 id,id+1,id+2
使用cross join宣告變數是因為leetcode的限制,可以拿掉放最前面宣告,效能也比較好。
##set varible
set @strC := (select CONCAT(GROUP_CONCAT(id) ,',')
from stadium
where people >= 100);
##query using rlike
select T1.*
from stadium T1
where people >= 100
and (
@strC Rlike
concat(
CONCAT(id,',',id+1,',',id+2,',')
,'|',CONCAT(id-2,',',id-1,',',id,',')
,'|',CONCAT(id-1,',',id,',',id+1,',')
)
) ;
這個方法真的想都沒想過欸!
先去串出所有大於等於100的資料,
並把每個欄位的id資料用豆點串在一起,
最後用正規表示法比較每筆資料!開了眼界了
話說現在大家都愛用大大推薦的sqlfiddle了XD
哈~
大大們用的習慣就好 
有想過要用串 id 的方式,不過後來沒有做出來,太厲害了。
既然是日期連續三天,我就把測試資料變動一下,id就跳動,以日期來作判斷.
create table ithelp180702 (
id serial primary key
, idate date not null
, people int not null
);
insert into ithelp180702 (idate, people) values
('2017-01-05'::date, 145),
('2017-01-06'::date, 1455),
('2017-01-08'::date, 188),
('2017-01-03'::date, 150),
('2017-01-04'::date, 99),
('2017-01-01'::date, 10),
('2017-01-02'::date, 109),
('2017-01-07'::date, 199);
id | idate | people
----+------------+--------
1 | 2017-01-05 | 145
2 | 2017-01-06 | 1455
3 | 2017-01-08 | 188
4 | 2017-01-03 | 150
5 | 2017-01-04 | 99
6 | 2017-01-01 | 10
7 | 2017-01-02 | 109
8 | 2017-01-07 | 199
(8 筆資料列)
---
with t1 as (
select idate
, lag(idate, 1) over w l1
, lag(idate, 2) over w l2
from ithelp180702
where people >= 100
window w as (order by idate)
), t2 as (
select array[idate, l1, l2] datearr
from t1
where idate - l2 = 2
), t3 as (
select distinct unnest(datearr) pickdate
from t2
)
select a.*
from t3
join ithelp180702 a
on t3.pickdate = a.idate
order by a.idate
;
id | idate | people
----+------------+--------
1 | 2017-01-05 | 145
2 | 2017-01-06 | 1455
8 | 2017-01-07 | 199
3 | 2017-01-08 | 188
(4 筆資料列)
使用了 window function lag(),還有array function unnest().
大大是先用people >= 100和lag()得出每筆破百日期的下一個日期和下下一個日期,
之後用idate減掉下下一個日期,如果等於2的話就代表有連續3筆,並把他放在一個陣列裡面,
最後使用unnest把符合的資料拆開來,再JOIN原資料表得出那些日期的資料。
暫時理解是這樣,再讓我消化一下
你說明的很不錯,還有個 distinct. lag() 是之前,不是之後.
對!!不好意思,那時候想的有點混亂了,讓我改一下以免誤人子弟XD
哈哈哈,其實我看得很吃力,謝謝大大誇獎!
我一開始也有想說直接從每一筆去判斷後三筆就好,
然後把判斷到符合的三筆的紀錄下來,
可是我那時候想破頭都出不來,
沒想到大大用了array配合unnest達成這個方式,
覺得很厲害!
這次的題目也是熟悉的 連續範圍 問題,不過題目限定 MySql 沒有 CTE 可以用,寫法有點笨拙,懷念的 CTE。
select id, date, people from (
select g
from (
/* 將人數大於等於100的資料重新編號,
再用id減去新編號,就是連續資料的群組編號 */
select t.*, id-(@i1:=@i1+1) as g
from (
select * from stadium where people>=100
) as t, (select @i1:=1) as temp
) as t
group by g
/* 找出大於等於3天的群組 */
having count(id) >= 3
) as a
inner join (
/* 以群組編號 join 回原資料,就是期望的結果 */
select t.*, id-(@i2:=@i2+1) as g
from (
select * from stadium where people>=100
) as t, (select @i2:=1) as temp
) as b on b.g=a.g
order by id
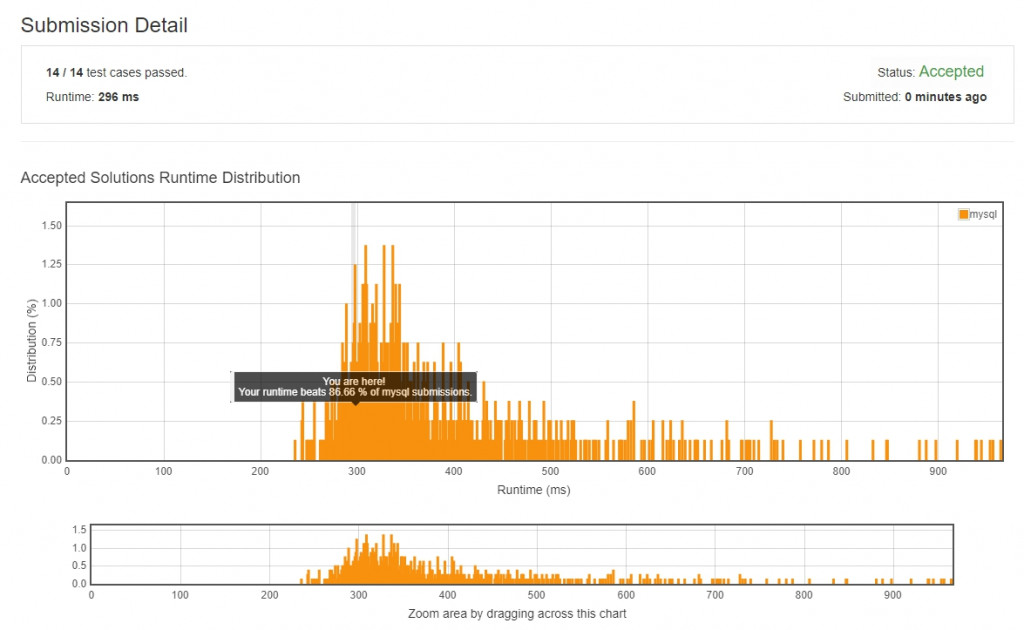
SQL 的分數有點飄,我絕對不會承認,我按了好多次選了一個最高的。
幫大大測試了 OR 的邏輯,OR 只要遇到 true 就會返回,和程式語言的 || 相同。
select @i as i,
case when (1=1 or (@i:=@i+1)>0) then 1 else 0 end as x
from (
select * from temp
) as t, (select @i:=1) as temp
| 條件 1=1 | 條件 1=0 |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
MSSQL 版本,用 CTE 和 ROW_NUMBER 簡潔很多。
;WITH CTE AS
(
SELECT *, id - ROW_NUMBER() OVER (ORDER BY id) AS g
FROM @Temp WHERE people>=100
)
SELECT id, [date], people
FROM
(
SELECT g
FROM CTE
GROUP BY g
HAVING COUNT(id)>=3
) AS A
INNER JOIN CTE AS B ON B.g=A.g
ORDER BY id
大大也是先將大於100日期的找出來重新編號,
不過用原本的id減掉新編的流水號,
再去INNER JOIN原本的資料表,把連續的剛好都會出現三次或以上撈出來!!!
這個邏輯是怎麼學來的,真得很厲害,而且也很簡潔,我想了非常之久
哈哈,其實我也在50%~70%間徘徊,想說取個比較好看的成績XD
話說原來他判斷到低一個為TRUE就不會繼續跑了!那我改那個CASE WHEN果然是心理作用嗎
連續範圍問題是在 【SQL分享】 統計玩家遊戲連勝連敗的資料 這篇看到的。
連續資料有一個特性:
連續的數值 - 流水號 = 相同的值
利用這點就可以將連續的資料分群。
+-----+------+-----------+
| num | row | num - row |
+-----+------+-----------+
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 3 | 0 |
| 10 | 4 | 6 |
| 11 | 5 | 6 |
| 14 | 6 | 8 |
+-----+------+-----------+
CASE WHEN 要測試看看,搞不好有什麼優化,哈哈哈
參考資料:
[SQL連續範圍] 數字,日期連續範圍
真的欸!!連續的數值 - 流水號 = 相同的值
這句話我會背起來抄十遍
 神Q超人
神Q超人
