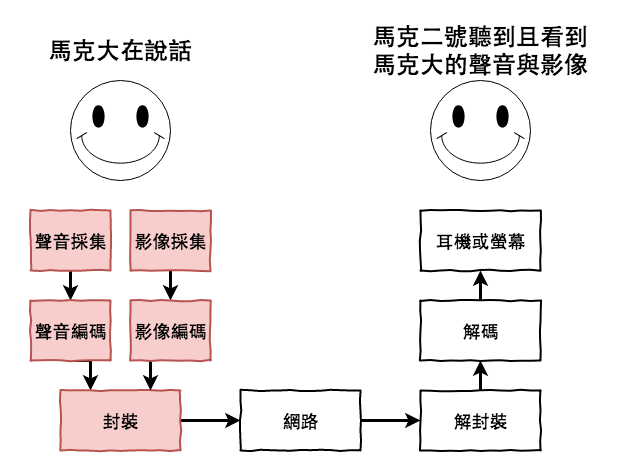
前一篇文章『30-07 Web 如何進行語音與影像採集 ?』咱們已經學習到如何使用 WebRTC 來進行聲音與影像的採集,並且將採集的結果儲放成一個 stream,最後在將儲放成檔案,接下來我們將研究一下 stream 裡面的東西,以及來簡單的將所採集到的聲音進行加工。
採集的詳細說明與聲音的加工。
本篇文章會將之分成以下幾個章節:
stream = track A + track B
前一篇文章中,咱們有提到可以用以下的程式碼,將聲音與影像給採集下來。
const constraints = { audio: true, video: true }
navigator.mediaDevices.getUserMedia(constraints)
.then((stream) => {
// stream 就是咱們的聲音與影像
})
.catch((err) => {
// 錯誤處理
})
然後咱們這裡來問個問題:
stream 是由什麼組合的 ?
大部份的人應該會說不就是聲音與影像嗎 ? 嗯某些方面的對,但這是抽象的說法,在研究程式碼時我覺得要儘可能的去討探它裡面實際的做法,這樣出現問題了咱們可以才可以理解為啥。
在 WebRTC 中,咱們使用 getUserMedia 來取得聲音與影像的 stream,它就是一個通道,會不斷的將聲音與影像編碼,然後 stream 裡面實際上是由 track 所組成,它就是每一個媒體來源,用下面的圖會更容易的理解。
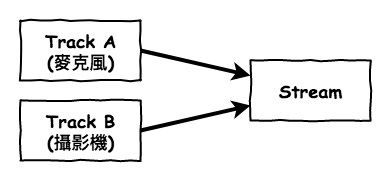
然後轉換成 WebRTC 的物件關係圖會如下:
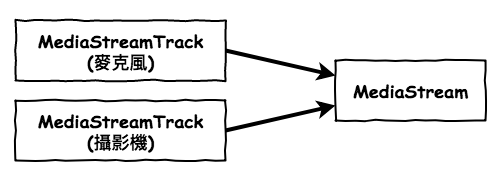
知道了它的組合以後,基本上我們就可以針對那個 Track 進行操作。假設我們想操作麥克風或攝影機,那我們可以使用以下的程式碼,那將該個 track 取出來。
MediaStream.getAudioTracks()
MediaStream.getVideoTracks()
然後咱們就可以針對 track 做些事情,例如在某段時間將聲音禁止然後影像繼續錄,又或是在某段時間將採集的影像變小,然後在某段時間回復過來,這些就都可以做到囉。這裡就不寫範例囉。
MediaStream.getAudioTracks 這方法是會回傳多個 track 沒錯,因為不同的麥克風就會有不同的 track。
使用 AudioContext 就可以對聲音做點喝喝喝的事情
在某些時後,咱們希望將採集到的聲音進行一些加工,例如讓別人聽不出來聲音是誰,又或是想讓原本採集的聲音大聲些,這時咱們就需要使用 Web Audio API 的 AudioContext。
Web Audio API 是一個用來專門在 Web 上進行音源處理的東東,它的基本核心如下圖,第一個是 AudioContext,這東東你可以想成它是一個聲音世界的神。然後第二個是 AudioNode 它就是每個處理聲音的實體,它裡面的聲音可以從外部檔案、麥克風採集或是用 AudioContext 裡面所提供的東西來產生聲音。相對的它也可以將他的聲音丟給其它 AudioNode 來進行加工。
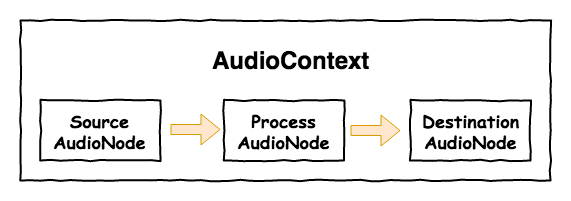
上面這樣說或需還有點兒抽像,接下來咱們簡單的來實作一段程式碼。
首先這段程式碼首先會先創造 AudioContext,接下來透過 createMediaStreamSource 來將 WebRTC 所採集的聲音流,轉換成 AudioContext 世界的 AudioNode。
navigator.mediaDevices.getUserMedia({ audio: true })
.then((stream) => {
const audioContext = new AudioContext;
// 將 WebRTC 所採集的聲音轉換成 AudioNode。
const sourceNode = audioContext.createMediaStreamSource(stream);
……
})
.catch((err) => {
console.log('nonono ~~~ !!');
})
接下來我們在產生另一個 AudioNode 它是用來將我們來源聲音,音量加大的加工師。
navigator.mediaDevices.getUserMedia({ audio: true })
.then((stream) => {
const audioContext = new AudioContext;
// 將 WebRTC 所採集的聲音轉換成 AudioNode。
const sourceNode = audioContext.createMediaStreamSource(stream);
// 產生音量加工師,用來將來源聲音加大
const processNode = audioContext.createGain();
processNode.gain.value = 20;
sourceNode.connect(processNode);
……
})
.catch((err) => {
console.log('nonono ~~~ !!');
})
最後在將加工完的聲音丟到終端麥克風。
navigator.mediaDevices.getUserMedia({ audio: true })
.then((stream) => {
const audioContext = new AudioContext;
// 將 WebRTC 所採集的聲音轉換成 AudioNode。
const sourceNode = audioContext.createMediaStreamSource(stream);
// 產生音量加工師,用來將來源聲音加大
const processNode = audioContext.createGain();
processNode.gain.value = 20;
sourceNode.connect(processNode);
// 將加工完的聲音丟給終端麥克風
const destinationNode = audioContext.destination;
processNode.connect(destinationNode);
})
.catch((err) => {
console.log('nonono ~~~ !!');
})
本篇文章中咱們學習到了以下的重點:

