
在 Resolver field 時,預設傳進來的參數無疑是非常強大的幫手,但要搞懂它並不容易。
我自己在剛開始學習時,因為 JS 不會強制規定參數名稱,所以每個教學文章使用的命名皆不盡相同,搞得明明一樣的東西你要兜一大圈才知道他們是一樣的。因此這邊我會使用與語意較為接近的命名方法,分別為
開始前可以參考 [Prisma] 部落格裡面一張超讚的解說圖:
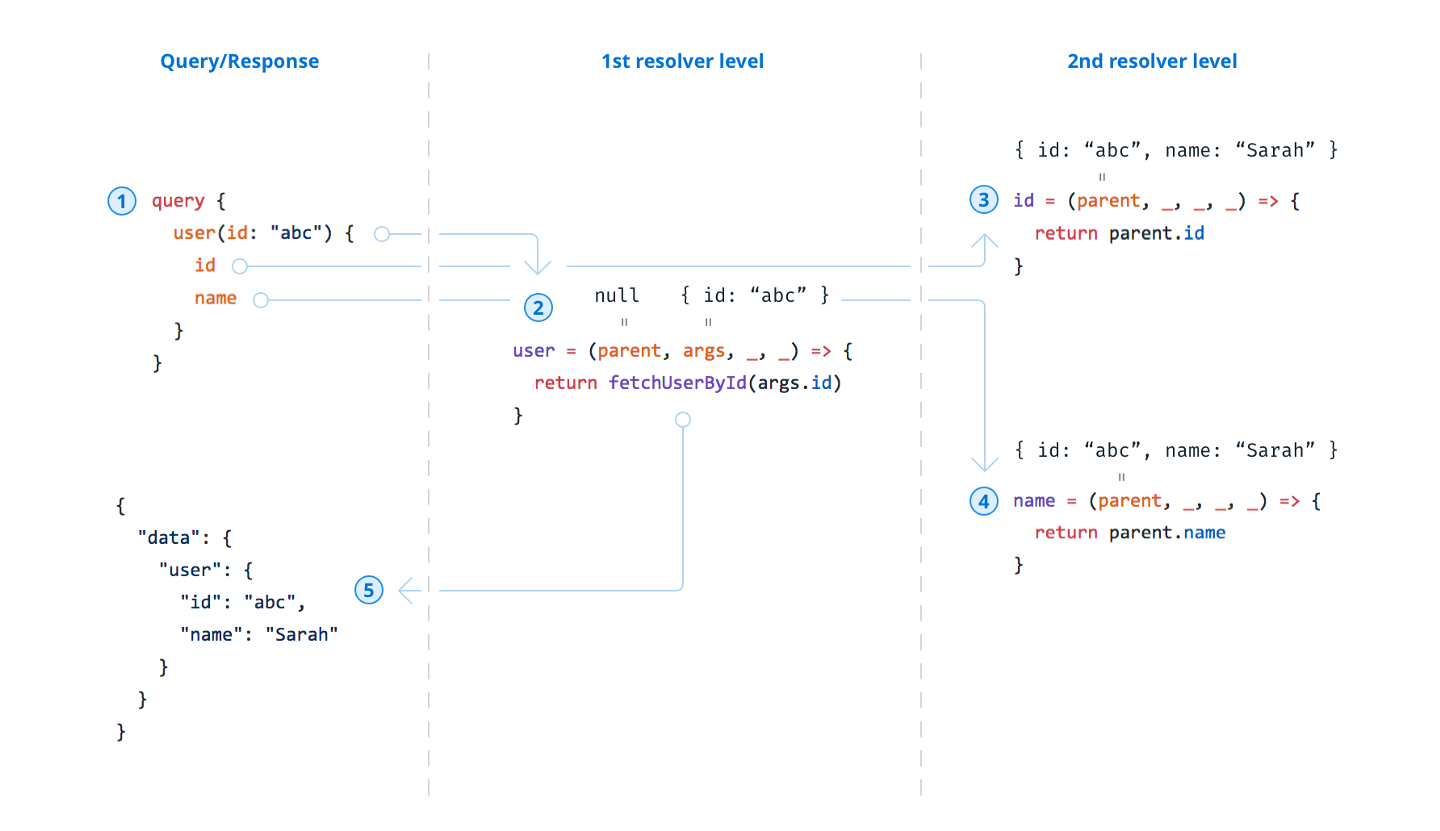
首先是 parent ,最直白的意義就是上一層的資料,至於什麼是上一層呢 ? 只需要看你的 field 是屬於哪個 Object Type 底下,你的 parent 就是該 Object Type 的資料,而如果是最上層的 Query field ,我通常會把 parent 命名為 root ,而 root 的值除非有特別設定不然都會是 null 。
type User {
id
name
age
friends
}
type Query {
me: User
}
const resolvers = {
Query: {
me: (root, args, context) => ({
// 這裡 root, args 都是 null
id: 1,
name: 'Fong',
age: 23,
posts: [2, 3]
})
},
User: {
id: (parent, args, context) => parent.id,
name: (parent, args, context) => parent.name,
age: (parent, args, context) => parent.age,
posts: (parent, args, context) => {
/* db operation to get posts by userId */
}
}
};
以上 Resover 中 User 的三個 field resolver function 的 parent 值都是一樣的。
parent 的妙用在於如果你需要特別處理某些 field ,假設是要對 age 添加額外資料 (ex: 搭配參數計算、依使用者權限調整值) 等等,就可以使用 parent.age 取得原值再做計算 ; 又假設你是想要得到其他同樣也是 User Type 的 posts 資料,但 db 撈出的原始資料與 schema 不合或甚至根本沒這項值,就可以用 parent.id 取得 user id 再去 db 撈相關的貼文 (post) 資料出來。
但對於初學者需注意的是,並不是 Schema 有定義的 field 就一定會出現在 parent 的裡面,重點是要看你 如何實作 Resolver。
之前說過 Query 為整個 Schema 的 entry point 。所以如果是因為前端 query 到 me 這個 field 而進入 User 的 field resolver ,那裡面的 parent 就得要看 me 的 Field Resolver 傳了什麼東西回去。
不同的 entry point 可能會造成
parent值的不同,所以應該透過良好的規範來避免不確定的parent值。
如果是使用 Relational Database (關聯式資料庫) 的朋友需要注意, Field Resolver 只能實作一層的
Resolver,沒有 Nested Field Resolver 這件事,因此也不會有 parent.parent 的存在 ! 因此也不會有以下的程式出現:
const resolver = {
User: {
posts: {
title: () => 'Can Nested FieldResolver Works?'
}
}
};
所以當你想新增的 Object Type (ex: Post Type) 在 Database Table (ex: post table) 有 Foriegn Key (ex: post.authorId) 時,最好放在 Foriegn Key (ex: authorId) 指向的 Object Type (ex: User Type) 的第一層。
EX: 你今天想要新增貼文 post 功能,而 post 的資料會存 authorId 來指向 user ,這時候如果你不知道為何沒把它放在第一層如下:
type Post { ... }
type Blog {
"貼文"
posts: [Post]
"貼文數"
postCount: Int
"觀看數"
viewCount: Int
}
type User {
...
blog: Blog
}
加上如果你的 Resolver 如下方程式這樣做,可能就會拿不到貼文:
const resolver = {
Blog: {
posts: (parent, args, context) {
// 此時的 parent 就是 blog 而非 user 資料,因此會沒有 userId 可以取得
}
}
}
可以看到這時候 Blog.posts 就無法依靠 user id 來取得貼文 (post) ,所以要不一開始就放第一層,要不就在設計貼文的 post table 時就將 blog id 也加進 Foreign Key.
**經驗談:**公司一開始開發時其實並不太會用 Field Resolver ,因此就傻傻的將有 Foreign Key 對應到的 Object Type 給塞到了深處,結果在開始了解 Field Resolver 的妙用後卻有很多因為拿不到上一層需要的資料而難以實作。當然在 GraphQL 有一些比較成熟的 Design Pattern 如 Pagination 為了處理大量資料分頁因此會將資料往裡層封裝,但除非你有很好的理解與適當的實作,不然不要輕易將資料往內層塞。
這裡的 args 概念很簡單,就是取得 query 或是 mutation 傳進來的參數,如果是使用 JS 的朋友我會建議直接在第一行就 deconstruct (解構) 掉,變成:
(parent, { args1, args2 }, context)
如果只是一個個參數排下來還好,但當加入 Input Object Type 就很容易造成錯誤的 deconstruct 。 因為 Input Object Type 格式上是 Object 形式 ,
所以如果 Schema 如下
input AddPostInput {
title: String!
body: String
}
type Mutation {
addPost: (input: AddPostInput!): Post
}
需注意 input 裡面還有一層,所以 resolver 使用時需再多 deconstruct 一層 (我當初常常忘記多 deconstruct 一層導致 bug 一直爆出來而且又超難除錯)
想知道更多參數如何命名的學問,可推薦參考 Github GraphQL API Explorer,可以從裡面可以推論出很多 pattern ,如
input 並有該 mutation 專屬的 Input Objcet Type ,連回覆的 Object Type 也是專屬的。接下來是今天的重頭戲 context 。
很多人會想說在 GraphQL 怎麼認證使用者 ?
答案是就通通放在 context 裡 ! 儘管去拿吧 !
以 token-based authentication 來說, Client Side 發出一支 login mutation 來, Server side 會給 Client Side 一個 token (可參考 JWT token),而下次 Client Side 發 query 或 mutation 來時就把 token 夾進 header 裡,這時 Server Side 接收到並開始解析 token ,如果成功從中解析出 user 資料,就將 user 資料塞進 context ,確保讓接下來一層層的 Field Resolver 是使用同一個 user 資料。
除了 token 解析成功的 user 資料, context 還可以放入一些機密的 secret 、環境變數等等,而這些資料可以傳入 authorization 、 business logic 等 layer 使用,如官方教學的下圖: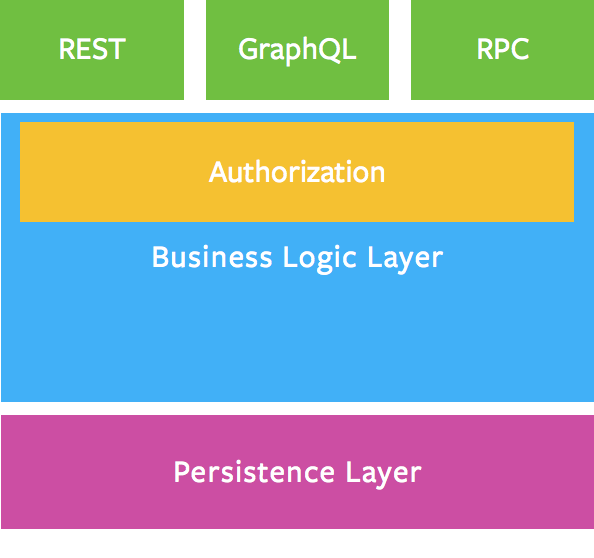
另外 context 還有另一個妙用:放入 ORM 或是其他 db operation 的 function 。 如下:
const resolvers = {
me: (parent, args, { user, UserModel }) => {
return UserModel.findById(user.id);
}
};
這樣的好處是減少管理外部引入的 dependency ,此外 GraphQL 在做 cache 或是 batching 等效能提升時,能將 function 下去會相當有用! (之後會介紹))
context 在 Apollo Server 的設定可以參考 Apollo Server 官方教學
。
const typeDefs = gql`
type Author {
name
}
`;
new ApolloServer({
typeDefs,
resolvers,
context: ({ req }) => {
const token = req.header['x-token'];
const user = jwt.verify(token);
return {
me: user,
userModel
// ...others like db models, env, secret, ...
};
}
});
有了這一層,當我登入成功得到 token 後使用 addPost mutation (記得 token 要放 header) 進入 GraphQL resolver 時,我們可以看到 context 裡面帶有 me 這項 user 資料。
const resolvers = {
Mutation: {
addPost: (root, { input: { title, body } }, context) => {
const { me, userModel } = context;
return userModel.create({
title,
body,
authorId: me.id
});
}
}
};
可以發現其實 context 其實就是一個 middleware ,只是藉由參數傳進 Apollo Server 會自動幫你設定好。
但其實,還有一個低調的第四人 info ,裡面主要存取一些 GraphQL 的 AST 資料結構及執行料,但基本上完全不會用到,連 GraphQL 官方文件都沒有說裡面在搞什麼鬼,因此真的不需費心。
有興趣的可以看 Prisma 的這篇文:
原本今天想要直接實作一個 server ,但發現還有一些觀念需要先建立,這樣實作過程若有不懂的也可以往前找到解答。
Reference
我們團隊這邊有使用 info 來作為 LOG 或 Debug 的使用。
我一直都把 info 裡面當亂碼(誤
我蠻好奇是怎麼樣當 log ? 是當 error 發生時 log 出錯的路徑嗎?


 iThome鐵人賽
iThome鐵人賽