上一篇我們做了出戰前的大概介紹,相信大家是越發的不明白。沒關係,我們來真的
1. 取出鳶尾花數據庫
鳶尾花資料集是非常著名的生物資訊資料集之一,基本上學習都從這裡開始,其實才 150 筆資料,但是對於作練習而言是很夠用的了。
from sklearn import datasets #載入 sklearn
iris = datasets.load_iris();
for key,value in iris.items() :
print(key)
我們先把 key 印出來看看裡面有什麼:
data
target
target_names
DESCR
feature_names
我們也可以這樣印出他的 key
我們可以快樂的印出每個 key 裡面的東西,大概就可以看出一些端倪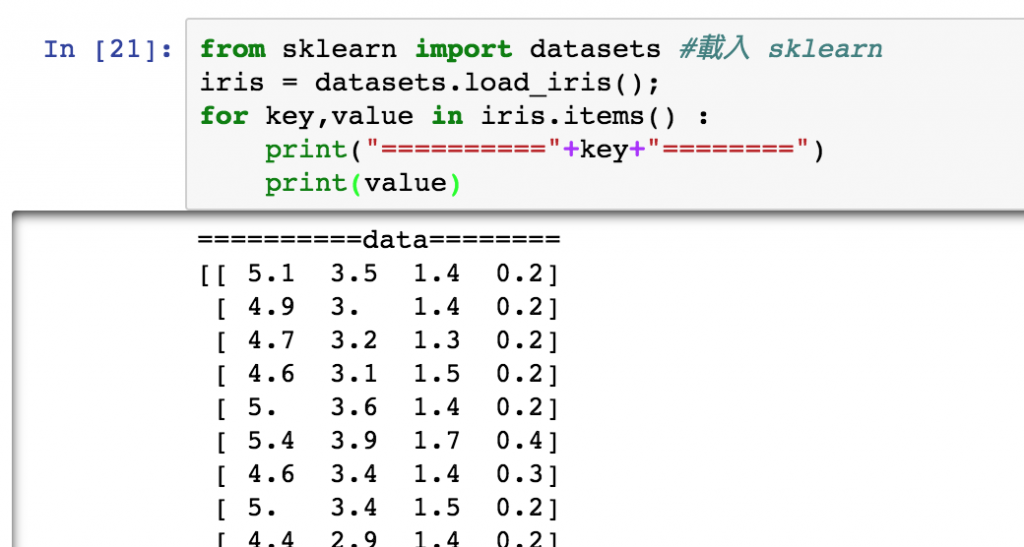

這是DESCR 看起來是說明文件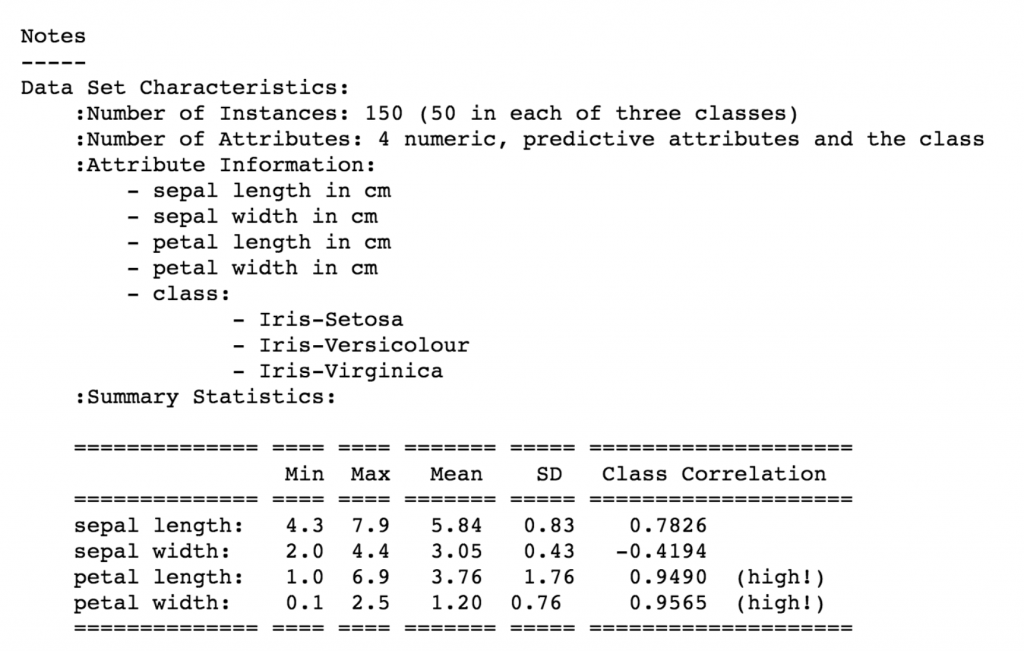

從上面的資料來看:
data 是特徵內容的資料
feature_names 是特徵的欄位名稱
target 是分類結果
target 是分類結果的名稱(判斷是哪個種類的花
這樣實在是太難閱讀了對吧!

