今天使用python練習簡單的爬取博客來即時榜
爬取內容:
1.榜單排名
2.書名
3.書的圖片網址
import requests
from bs4 import BeautifulSoup
#博客來即時榜單
url='https://www.books.com.tw/web/sys_hourstop/books?loc=act_menu_th_43_001'
#使用get方式向網頁發送請求
html=requests.get(url)
#使用utf-8方式編碼讀取網頁
html.encoding='utf-8'
#自訂網頁表頭,讓電腦模擬瀏覽器操作網頁,騙過網頁伺服器
headers={'user-agent':'Mozilla/5.0'}
#使用BeautifulSoup解析原始碼
sp=BeautifulSoup(html.text,'lxml')
#讀取網頁內容,找到博客來即時榜的位置範圍
m=sp.select('.mod_no')[0].select('.item')
for i in m:
#讀取榜單排名
print("%s"%i.find_all('strong')[0].text,end=' ')
#讀取書名
print(i.find_all('h4')[0].text)
#讀取圖片網址
print(i.select('img')[0]['src'])
sp=BeautifulSoup(html.text,'lxml')
關於BeautifulSoup解析原始碼這裡
我們前面教學使用的方式是html.parser
但是最近聽說大家推薦 lxml
聽說解析速度會比較快
所以這裡就使用lxml方始製作囉
結果顯示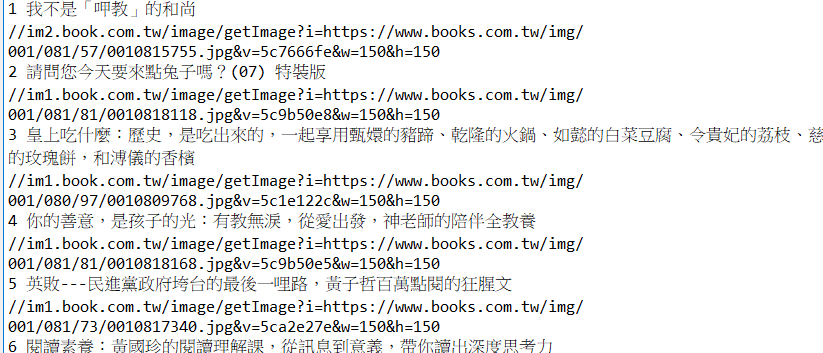
 Zoey
Zoey
