此篇為 SICP教程 6a 的筆記
若是 流 的方式來處理,流程如下:
這顯然是非常非常佔記憶體的事情,若是更大的範圍呢,況且只是要找第二個數,用這個例子來比較傳統 時序 概念與流概念誰比較適合的話,答案反而是前者。
現在反而矛盾了,之前把 流 吹捧得這麼厲害,能把邏輯複雜的規則呈現的簡單又清楚,但實務上卻是佔記憶體且無法處理大型數據,怎麼會這樣?
其實接下來才是真正厲害的地方。
流 之所以會輸 傳統時序 的地方,就是需要 先產生所有計算要用到的數據 才進行處理,那能不能讓數據在 需要計算 的時候再進行計算呢?
如果用圖形來表示(影片當中用道具):
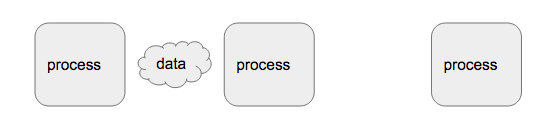
失敗的流:
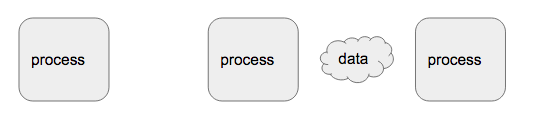

想像中成功的流:
當result要求一個數據,就從 流 的尾部(tail)向最後一個process拉取一個數據,最後一個process再向前一個process拉取,以此類推。只有在末端要求一定量數據時,源頭才產生定量的數據。
但有什麼 data structure 可以這樣搞? 有的! 而且是最基本的種類,就是 "function as data" 來達成這個夢幻的 流。
首先認識幾個基本元素 con-stream, head, tail
(defn con-stream [x y]
(cons x (delay y)))
(defn head [s] (car s))
(defn tail [s] (force (cdr s)))
delay 所做的有兩件事 1. 產生function的表達式 2.一個執行許可,當接收到執行許可時再去執行。force 就是 delay 的執行許可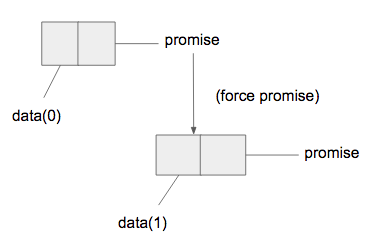
(head (tail (filter prime? (map 每一個數 1000 1000000)))))
(map 每一個數 1000 1000000) -> (cons 1000 (delay (map 每一個數 1001 1000000)))
(filter prime? (map 每一個數 1000 1000000))
-> (filter prime? 1000)
-> (filter prime?(tail (cons 1000 (delay (map 每一個數 1001 1000000)))))
上述可見,filter出來的數據,不會比map的還要多,因為filter去要求(force delay)的時候,數據才會產生。
真正神奇的地方 delay 與 force ,實作上也非常的簡單
(defn delay [exp] (fn [] (exp)))
(defn force [fn] (fn))
還有一個問題,當執行遞迴的tail時會出現 (tail (tail (tail...))),每一次計算新的數據,就要把以前的tail都計算一次,相當沒有效率,因此若能將之前計算過的tail都記錄下來就能避免,因此將delay改成為
(defn delay [exp] (memo-proc (fn [] (exp))))
memo-proc是一個function,記錄前面所有產生過的數據,讓每一次force tail時只做一次的計算。
 MarkWengSTR
MarkWengSTR

 iThome鐵人賽
iThome鐵人賽