基本上看到題目有要除掉 "duplicates" (重覆) 字眼,十之八九都會用到 Set
/*javascript
Given an array of integers, find if the array contains any duplicates.
Your function should return true if any value appears at least twice in the array, and it should return false if every element is distinct.
Example 1:
Input: [1,2,3,1]
Output: true
Example 2:
Input: [1,2,3,4]
Output: false
Example 3:
Input: [1,1,1,3,3,4,3,2,4,2]
Output: true
*/
/**
* @param {number[]} nums
* @return {boolean}
*/
var containsDuplicate = function(nums) {
};
這題坦白說真的是送分題
var containsDuplicate = function(nums) {
return new Set(nums).size < nums.length;
};
題目連結在此
這題有趣很多,原來前端也可以寫出拯救國家 Morse Code (想太多)
這題會用到一些 String 的 method,有興趣的可以看這裡
/*
International Morse Code defines a standard encoding
where each letter is mapped to a series of dots and dashes,
as follows: "a" maps to ".-", "b" maps to "-...", "c" maps to "-.-.", and so on.
For convenience, the full table for the 26 letters of the English alphabet is given below:
[".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."]
Now, given a list of words, each word can be written as a concatenation of the Morse code of each letter.
For example, "cba" can be written as "-.-..--...", (which is the concatenation "-.-." + "-..." + ".-").
We'll call such a concatenation, the transformation of a word.
Return the number of different transformations among all words we have.
Example:
Input: words = ["gin", "zen", "gig", "msg"]
Output: 2
Explanation:
The transformation of each word is:
"gin" -> "--...-."
"zen" -> "--...-."
"gig" -> "--...--."
"msg" -> "--...--."
There are 2 different transformations, "--...-." and "--...--.".
Note:
The length of words will be at most 100.
Each words[i] will have length in range [1, 12].
words[i] will only consist of lowercase letters.
*/
/**
* @param {string[]} words
* @return {number}
*/
var uniqueMorseRepresentations = function(words) {
};

let mos = [".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."];
let getIndex = char => char.charCodeAt(0) - "a".charCodeAt(0)
var uniqueMorseRepresentations = function(words) {
// ["gin", "zen", "gig", "msg"]
let transform = words.map( word =>{
// ["gin"]
return word.split('') // // ["g", "i", "n"]
.map( char => {
// ["g"]
return mos[getIndex(char)]
})
.join('')
})
return new Set([...transform]).size;
};
結果出來是 Your runtime beats 65.49 % of javascript submissions。
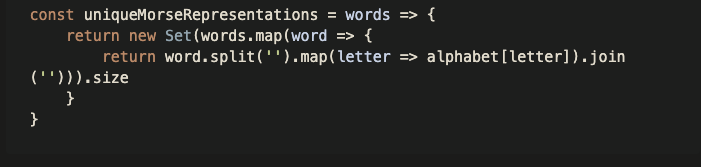
想看看有沒有更好寫法,結果找到一個概念跟我想的很像,但比我簡潔,runtime 也高到 90% 以上。最大差別應該就是他沒有再用 charCodeAt 去計算,一開始就先把字母對應哪個摩絲密碼寫好了。
自己畫了一張圖幫助理解
也可以看作者的解釋
const alphabet = {
a: '.-', b: '-...', c: '-.-.', d: '-..', e: '.', f: '..-.', g: '--.', h: '....', i: '..', j: '.---', k: '-.-', l: '.-..', m: '--',
n: '-.', o: '---', p: '.--.', q: '--.-', r: '.-.', s: '...', t: '-', u: '..-', v: '...-', w: '.--', x: '-..-', y: '-.--', z: '--..'
}
const uniqueMorseRepresentations = words => {
return new Set(words.map(word => {
return word.split('').map(letter => alphabet[letter]).join(''))).size
}
}
所以多參考別人答案,真的很有幫助,每每看到簡潔又厲害的答案真的覺得自己很不足,一起加油 ~~
歡迎追蹤我的部落格,除了技術文也會分享一些在矽谷工作的甘苦。
加油~這是我看過最圖文並茂的系列文了~
其實做圖應該有花一半的時間 XD,來介紹一下 https://www.canva.com
工程師作圖救星,前端打死也不想裝 PS 在電腦裡讓電腦變超慢
解 804. Unique Morse Code Words 這題的時候拿到
Memory Usage: 34.8 MB, less than 100.00% of JavaScript online submissions for Unique Morse Code Words.
覺得開心 XD



 iThome鐵人賽
iThome鐵人賽