如同我們前幾天所寫的倒排索引,多數搜尋引擎為了查詢的效率,會將索引儲存在記憶體當中。如此,需要足夠的記憶體才能夠將所有索引儲存起來。如果我們能夠從索引的資料型態中壓縮,便可以減少硬體需求,因此人們開始思考如何壓縮索引,讓更多部分可以存在記憶體中,以達到有效率的查詢。
一種做法稱為變數位元壓縮(Variable Byte Compression),從我們倒排索引的Posting List下手,壓縮的方法主要為:
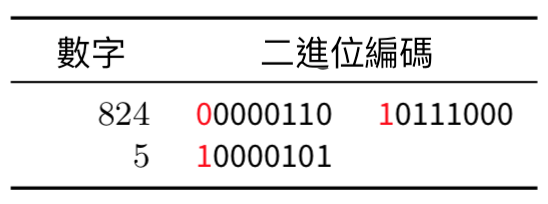
第一行電腦讀到0000110 10111000 = 2^9 + 2^8 + 2^5 + 2^4 + 2^3 = 824
第二行讀到10000101 = 2^2 + 2^0 = 5

而儲存文件ID的間隔而非文件本身的好處也如上圖,可以減少位元組的數量,達到空間壓縮的效果。
附上Variable Bytes Compression的加解密演算法,我們明天來實作!



 iThome鐵人賽
iThome鐵人賽